《分库分表》专题
-
JsonException没有分配_valueDeserializer
问题内容: 我有一个带有某些Spring Crud存储库的经典Spring Web应用程序。 我试图将我的实体保存在经典的角度形式内,并且随机出现此错误: 这是我发送的杰森: 这是我的课程: Exchange.java Halfflow.java 这是我的控制器签名: 我想知道什么会引发此错误,并且这种出现是随机的。 问题答案: 正如Alex所说,为防止无限递归,您添加了此批注 所以我实际上通过在
-
Kafka 分区的目的?
本文向大家介绍Kafka 分区的目的?相关面试题,主要包含被问及Kafka 分区的目的?时的应答技巧和注意事项,需要的朋友参考一下 分区对于 Kafka 集群的好处是:实现负载均衡。分区对于消费者来说,可以提高并发度,提高效率。
-
Mysql DateTime组15分钟
问题内容: 我有一张看起来像这样的桌子 我基本上将某些记录的创建时间存储在表中。我知道是否要对在15分钟间隔内创建的记录进行计数,我将使用类似的方法 那给我这样的东西 我如何理解第一列?如果我想给我看类似的东西 我了解通过一些操作,我可以在下午2:15出现1434187。甚至那可能是一个好的开始。。。然后我可以用一些逻辑来说明整个时期。谢谢! 问题答案: 一种方法是只使用和以使所有内容都在一个范围
-
entityManager.getTransaction()。rollback()分离实体?
问题内容: 我有以下代码: 这会在第四行引发IllegalArgumentException,提示“实体未管理”。如果我将第三行改为而不是,那么一切似乎都可以正常工作。 这里发生了什么?我可以防止这种情况发生吗? 更新: @DataNucleus将我引向PersistenceContext。如何在代码中更改持久性上下文? 问题答案: 根据Eval 2.0 Eval的JSR-000317持久性规范:
-
休眠分页机制
问题内容: 我正在尝试对查询使用Hibernate分页(PostgreSQL) 我设置,我的SQL查询。我的代码如下: 但是当查看SQL Hibernate日志时,我仍然看到完整的SQL查询: 为什么在Hibernate分页SQL日志查询中没有LIMIT OFFSET? 有人知道Hibernate分页机制吗? 我猜Hibernate将选择所有数据,将数据放入Resultset,然后在Results
-
将Hashmap分配给Hashmap
问题内容: 我有一个哈希图,我想复制该哈希图以用于其他用途。但是,每当我复制并重复使用它时,它也会更改原始内容。这是为什么? 提前致谢 问题答案: 您要做的不是创建地图的副本,而是创建地图的副本。当两个引用指向同一对象时,对一个对象的更改将在另一个对象中反映出来。 解决方案1:如果这是从某种简单类型到另一种类型的Map,则应改为: 这称为复制构造函数。几乎所有标准的Collection和Map实现
-
XMLHttpRequest 206部分内容
问题内容: 我想从JavaScript中的XMLHttpRequest对象发出部分内容请求。我正在从服务器加载一个大的二进制文件,而宁愿从服务器流式传输它,类似于html5视频的处理方式。 我可以使用setRequestHeader设置Range标头。Chrome中的网络检查器显示Range标头设置成功。但是,Accept- Encoding标头设置为“ gzip,deflate”,Chrome不
-
Tensorflow GPU内存分配
我正在尝试使用我的GPU而不是CPU来训练一个自定义的对象检测模型。我遵循了以下教程中给出的所有说明:https://tensorflow-object-detection-api-tutorial.readthedocs.io/ 我已经测试了我的软件,一切都已安装并正常工作。 目前正在使用: Windows 10 但问题是,在训练几秒钟后,它停止使用GPU,并发出以下警告消息。 此外,我没有在我
-
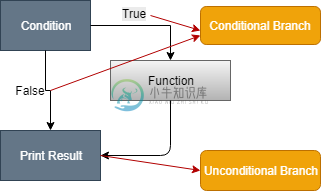 分支覆盖测试
分支覆盖测试主要内容:如何计算分支覆盖范围?分支覆盖技术用于覆盖控制流图的所有分支。它至少涵盖决策点的每个条件的所有可能结果(真和假)。分支覆盖技术是一种白盒测试技术,可确保每个决策点的每个分支都必须执行。 然而,分支覆盖技术和决策覆盖技术非常相似,但两者之间存在关键差异。决策覆盖技术涵盖每个决策点的所有分支,而分支测试涵盖代码的每个决策点的所有分支。 换句话说,分支覆盖遵循决策点和分支覆盖边缘。许多不同的指标可用于查找分支覆盖范围和决策覆
-
 等效分区技术
等效分区技术等效分区是一种软件测试技术,其中输入数据被划分为有效值和无效值的分区,并且所有分区必须表现出相同的行为。如果一个分区的条件为真,则另一个等效分区的条件也必须为真,如果一个分区的条件为假,则另一个等效分区的条件也必须为假。等价划分的原则是,测试用例应设计为至少覆盖每个分区一次。每个等效分区的每个值必须表现出与其他分区相同的行为。 等效分区源自软件的要求和规范。这种方法的优点是,它有助于减少测试时间,
-
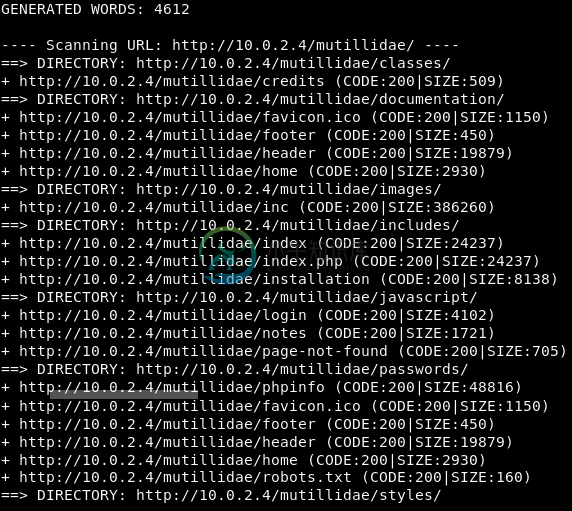 分析发现文件
分析发现文件在下面的屏幕截图中,可以看到dirb工具能够找到许多文件的结果。下面是我们已经知道的一些文件: 在下面的屏幕截图中,我们可以看到只是一个图标文件。是我们经常看到的索引。页脚和标题可能只是样式文件。可以看到有一个登录页面。 现在,我们可以通过利用一个非常复杂的漏洞找到目标的用户名和密码。但我们最终无法登录,因为无法找到登录的位置(页面)。在这种情况下,像这样的工具会很有用。我们查看文件通常非常有用,
-
TensorFlow分布式计算
本章将重点介绍如何开始使用分布式TensorFlow。目的是帮助开发人员了解重复出现的基本分布式TF概念,例如TF服务器。我们将使用Jupyter Notebook来评估分布式TensorFlow。使用TensorFlow实现分布式计算如下所述 - 第1步 - 为分布式计算导入必需的模块 - 第2步 - 使用一个节点创建TensorFlow集群。让这个节点负责一个名称为“worker”的作业,并在
-
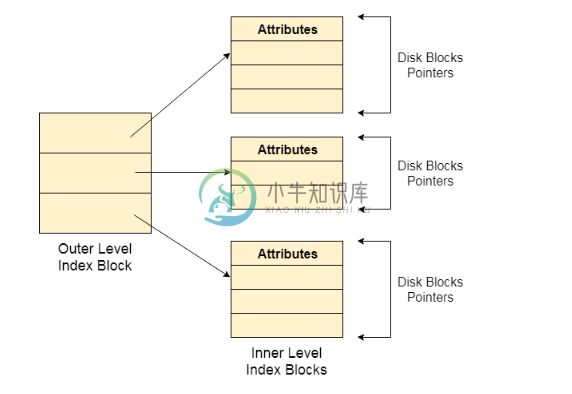 链接索引分配
链接索引分配主要内容:多级索引分配单级链接索引分配 在索引分配中,文件大小取决于磁盘块的大小。 要允许大文件,我们必须将几个索引块链接在一起。在链接索引分配中, 提供文件名称的小标题 前100个块地址的集合 指向另一个索引块的指针 对于较大的文件,索引块的最后一个条目是一个指向另一个索引块的指针。 这也被称为链接模式。 优点: 它消除了文件大小限制 缺点: 随机访问变得有点困难 多级索引分配 在多级指数分配中,有各种索引级别。 有
-
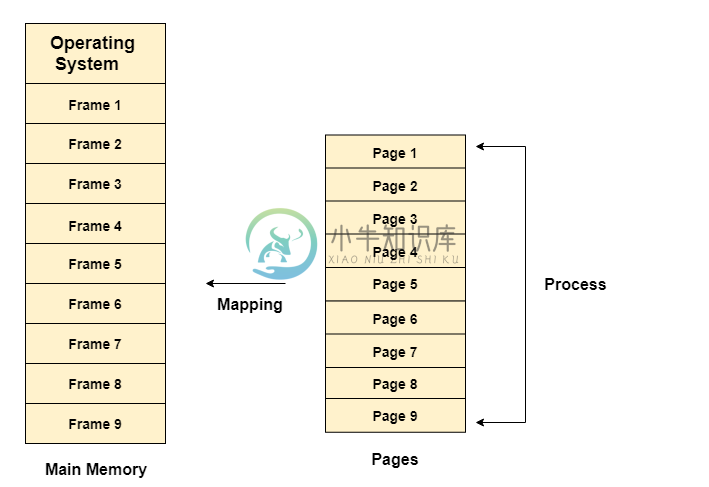 分页技术实例
分页技术实例主要内容:内存管理单元在操作系统中,分页是一种存储机制,用于以页面形式从辅助存储器检索进程到主内存中。 分页背后的主要思想是以页面的形式划分每个进程。 主存也将以帧的形式分割。 进程的一页将被存储在存储器的一个帧中。 分页可以存储在内存的不同位置,但优先级始终是查找连续的帧或空洞。 进程页面只有在需要时才会被带入主内存,否则它们将驻留在辅助存储中。 不同的操作系统定义不同的帧大小。 每个帧的大小必须相等。 考虑到页面被
-
YAML缩进和分离
主要内容:YAML的缩进,分离字符串当学习任何编程语言时,缩进和分离是两个主要概念。本章详细讨论了与YAML相关的这两个概念。 YAML的缩进 YAML不包括任何强制性空格。此外,没有必要保持一致。有效的YAML缩进如下所示 - 在YAML中使用缩进时,应该记住以下规则:流块必须至少包含一些具有周围当前块级别的空格。 YAML的流含量跨越多条线。流内容以或开头。 阻止列表项包括与周围块级相同的缩进,因为 符号被视为缩进的一部分。 预