《分库分表》专题
-
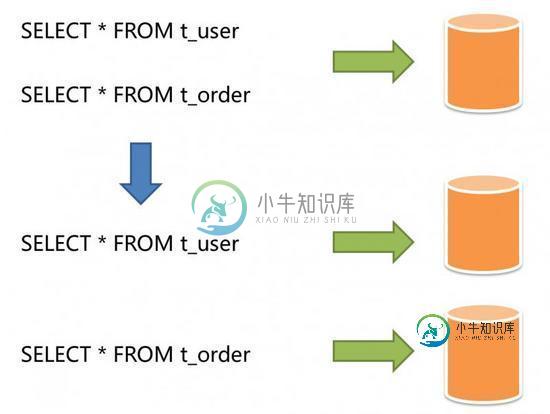
数据库 - 或许我们都被分库分表约束了思维?
概述 这篇文章没什么太多的干货,纯纯是一篇讨论和思考帖。 从业数据库领域三年有余了,从分库分表中间件到数据库团队内核学到了很多东西。也接触了很多项目,包括TiDB、Vitess、Polardb、StarDB等等。 国内的项目好像很多都聚焦于分库分表的概念,包括很多的数据库团队都在尝试这个概念的落地和沉溺于性能的跑分。 最近我在预览MySQL官方,看到了Partitioning的概念,而且占据了很大
-
1.4.4 分库分表之后,id 主键如何处理?
面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个全局唯一的 id 来支持。所以这都是你实际生产环境中必须考虑的问题。 面试题剖析 基于数据库的实现方案 数据库自增 id 这个就是说你的系统里每次得到一个 id,都是往一个库的一个表里插入一条没什么业务
-
 Springboot2.x+ShardingSphere实现分库分表的示例代码
Springboot2.x+ShardingSphere实现分库分表的示例代码本文向大家介绍Springboot2.x+ShardingSphere实现分库分表的示例代码,包括了Springboot2.x+ShardingSphere实现分库分表的示例代码的使用技巧和注意事项,需要的朋友参考一下 之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程。 概念解析 垂直分片 按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专
-
分库分表规则原理及自定义配置
背景 业务在使用分表分表时多数会使用简单的hash分表或者按照时间或者id使用内置的range分表函数,但某些情况下这些简单的hash规则和内置函数并不能满足业务复制的分表场景,这时就需要业务自定义分库分表规则。而zebra的分库分表规则使用的是groovy脚本,理论上可以支持定制各种复杂的路由规则。 基本原理 首先,先看一个简单的分库分表规则(使用本地配置时的XML),后面会基于该例子解释zeb
-
 分库分表让系统性能提升上百倍
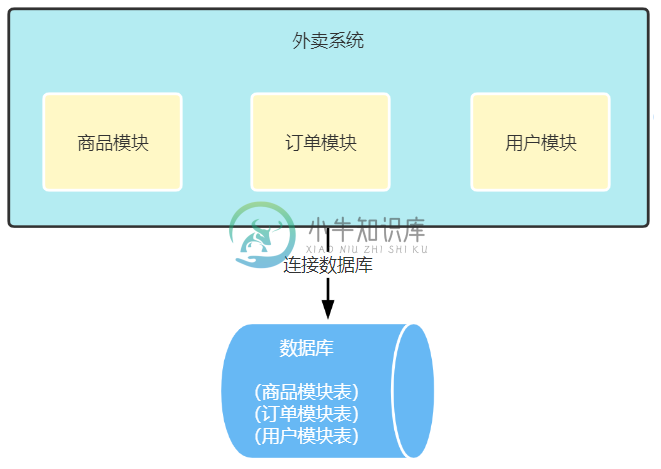
分库分表让系统性能提升上百倍主要内容:前 言,新的挑战,怎么做垂直拆分?,垂直拆分有哪些好处呢?,垂直拆分有什么不足的地方吗?前 言 读写分离方案上线后,订单sql查询时间再一次稳定在了300ms以下,此时对数据的增删改操作会走主库,而读请求会走从库,通过读写分离大大提升了数据读的处理能力,但遗憾的是没办法提升主库写数据的能力。 新的挑战 那么什么时候主库写数据的压力会过大呢?其实我们之前也聊过这个问题,那就是多个业务共用一个物理数据库的,比如商品相关的表、订单相关的表和用户相关的表等,所有表都放到了一个mysql数据库
-
Java文本分析库
问题内容: 我正在寻找一种Java驱动的解决方案来满足分析句子以记录关键字是肯定还是否定使用的要求。 即关键词可能是’白菜’和句子: 我喜欢白菜而不喜欢豌豆 我想要某种Java文本分析器将此记录为肯定。可以使用lucene(休眠搜索)库吗? 有什么想法吗? 问题答案: 您正在寻找“情感分析”。LingPipe是一种可能,他也与竞争对手保持友好联系。Jeff Dalton 的博客中还提供了大量自然语
-
SQLite 分离数据库
主要内容:语法,实例SQLite 的 DETACH DATABASE 语句是用来把命名数据库从一个数据库连接分离和游离出来,连接是之前使用 ATTACH 语句附加的。如果同一个数据库文件已经被附加上多个别名,DETACH 命令将只断开给定名称的连接,而其余的仍然有效。您无法分离 main 或 temp 数据库。 如果数据库是在内存中或者是临时数据库,则该数据库将被摧毁,且内容将会丢失。 语法 SQLite 的 DET
-
分层的库设计
分层的库设计 每个Subversion核心模块都属于三层中的某一层—版本库层、版本库访问(RA)层或是客户端层(见图 1 “Subversion的架构”)。我们很快就会考察这些层,但首先让我们看一下Subversion库的摘要目录,为了一致性,我们将通过它们的无扩展Unix库名(例如libsvn_fs、libsvn_wc和mod_dav_svn)来引用它们。 libsvn_client 客户端程序
-
分布式数据库
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
超大数据量存储常用数据库分表分库算法总结
本文向大家介绍超大数据量存储常用数据库分表分库算法总结,包括了超大数据量存储常用数据库分表分库算法总结的使用技巧和注意事项,需要的朋友参考一下 当一个应用的数据量大的时候,我们用单表和单库来存储会严重影响操作速度,如mysql的myisam存储,我们经过测试,200w以下的时候,mysql的访问速度都很快,但是如果超过200w以上的数据,他的访问速度会急剧下降,影响到我们webapp的访问速度,而
-
 分库分表实战之订单业务完整梳理!
分库分表实战之订单业务完整梳理!主要内容:前 言,用户下单流程,用户查询订单列表流程,用户查看订单详情流程,用户取消订单流程,结束语前 言 上一期内容我们整体了解了分库分表实战项目当前使用的系统架构,也就是单库版本订单系统的系统架构。同时,我们也知道了未来要做的分库分表版本的订单系统架构。现在,我们就从单库版本的订单系统开始,一步一步的来进行优化。 如果想要优化单库版本的订单系统,首先要了解目前的订单系统有哪些核心功能,核心功能的业务流程是什么。 如果你刚入职了这家初创型互联网公司,而你所在的部门又刚好是做外卖APP的订单系统
-
 MySQL 分库分表的基本概念和常见问题
MySQL 分库分表的基本概念和常见问题主要内容:读写分离不能解决的问题,1 分表,1.1 水平切分,1.2 垂直切分,2 分库,2.1 按业务分库,2.2 按表分库,3 分库分表的问题,3.1 跨库join操作,3.2 分布式事务,3.3 跨库排序、分页、函数计算问题,3.4 分布式ID,3.5 数据扩容,3.6 数据迁移,4 分库分表工具简单介绍了分库分表的概念以及相关问题。 读写分离不能解决的问题 读写分离主要应对的是数据库读并发的问题,但还有其他问题不能解决: 单个数据库的可支持的并发量是有限的,在高并发场景下,大量请求都需要
-
按数据库分段Redis
问题内容: 默认情况下,Redis配置了16个数据库,编号为0-15。这仅仅是名称间隔的一种形式,还是按数据库隔离会对性能产生影响? 例如,如果我使用默认数据库(0),并且有1000万个键,则最佳实践建议使用 keys 命令按通配符模式查找键效率低下。但是,如果我存储我的主键,也许是8个段键的前4个段,结果导致在单独的数据库(例如数据库3)中的键子集要小得多。Redis是将它们视为较小的一组密钥,
-
数据库Database - ItemReaders分页
6.9.2 可分页的 ItemReader 另一种是使用数据库游标执行多次查询,每次查询只返回一部分结果。 我们将这一部分称为一页(a page)。 分页时每次查询必须指定想要这一页的起始行号和想要返回的行数。 JdbcPagingItemReader 分页 ItemReader 的一个实现是 JdbcPagingItemReader。 JdbcPagingItemReader 需要一个 Pagi
-
数据库分离部署
V9数据模型功能,允许用户把不同的数据表,分离到不同的数据库服务器上。以实现负载的分离,更加的符合大访问网站的需求。 数据分离方法 1.数据库连接配置 配置文件路径:caches\configs\database.php return array ( 'default' => array ( 'hostname' => 'localhost', 'database' => 'phpcm