《内存淘汰》专题
-
Android内存泄漏?
问题内容: 我认为我的android应用正在泄漏内存。我不是绝对确定这是问题所在。 应用程序打开时经常崩溃,并且logcat尝试加载位图图像时会显示“内存不足”异常。 崩溃后,我重新打开了该应用程序,它运行正常。Logcat会显示许多“ gc”,并且JIT表会不时地向上调整大小,而不会向下调整,直到应用程序因内存不足错误而崩溃。 这听起来像是内存泄漏吗?如果是这样,我该如何定位和关闭泄漏点。 这是
-
Memcache与Java内存
问题内容: 一个简单的,可能是愚蠢的问题:假设我有一个Java服务器,该服务器在内存中存储了我可以查询的常用键和值(比如说在HashMap中) 与使用Memcache(甚至是Redis)有什么区别?它们都将事物存储在内存中。一个或另一个有好处吗?Memcache是否会减少内存占用量?可以在更少的内存中存储更多内容吗?查询更快?没有不同? 问题答案: Java内存相对于Memcache的优势:
-
Python内存zip库
问题内容: 是否有一个Python库,可以在不使用实际磁盘文件的情况下操纵内存中的zip存档? ZipFile库不允许您更新存档。唯一的方法似乎是将其提取到目录中,进行更改,然后从该目录中创建新的zip。我想修改没有磁盘访问权限的zip归档文件,因为我将下载它们,进行更改并再次上传它们,因此没有理由存储它们。 尽管几乎没有任何接口可以避免磁盘访问,但类似于Java的ZipInputStream /
-
Elasticsearch内存问题
问题内容: 当我也尝试在Ubuntu中启动elasticsearch时,启动脚本给我以下错误: 我已经尝试通过此方法进行搜索,但找不到解决方案。如果我重启机器,一切正常工作一天,然后elasticsearch下降并出现此错误。 我已经在elasticsearch.yml文件中设置了bootstrap.mlockall:true属性,并在默认的elasticsearch文件中设置了属性: 有人知道我
-
Nginx内容缓存
主要内容:1. 介绍,2. 启用响应缓存,3. 涉及缓存的NGINX进程,4. 指定要缓存的请求,5. 限制或绕过缓存,6. 从缓存中清除内容,7. 字节缓存,8. 组合配置示例本节介绍如何启用和配置从代理服务器接收的响应的缓存。主要涉及以下内容 - 缓存介绍 启用响应缓存 涉及缓存的NGINX进程 指定要缓存的请求 限制或绕过缓存 从缓存中清除内容 配置缓存清除 发送清除命令 限制访问清除命令 从缓存中完全删除文件 缓存清除配置示例 字节缓存 组合配置示例 1. 介绍 当启用缓存时,NGINX
-
alsa-内存泄漏?
问题内容: 我一直在追寻内存泄漏(由“ valgrind –leak-check = yes”报告),它似乎来自ALSA。这段代码已经存在于自由世界中一段时间了,所以我猜这是我做错的事情。 输出看起来像这样: 并继续一些页面 这是由于我在一个项目中使用ALSA并开始看到这种巨大的泄漏……或者至少是所说泄漏的报告。 所以问题是:是我,ALSA或valgrind在这里遇到问题吗? 问题答案: ht
-
Malloc内存问题
问题内容: 首先,我注意到当我分配内存与calloc时,内存占用量是不同的。我正在使用数GB的数据集。此数据可以是随机的。 我以为我可以分配大量的内存并读取其中的任何随机数据,然后将其强制转换为浮点数。但是,在进程查看器中查看内存占用量时,显然并没有要求使用内存(与calloc相比,我看到了较大的占用空间)。我运行了一个循环,将数据写入内存,然后看到内存占用量攀升。 我是否正确地说,直到初始化内存
-
Java内存编译
问题内容: 我如何在运行时从字符串生成字节码(Byte []),而无需使用“ javac”进程或类似的东西?有没有像这样调用编译器的简单方法? 以后添加: 我选择接受最适合 我的 情况的解决方案。我的应用程序是一个尚处于设计草图阶段的业余项目,现在是考虑插入新技术的合适时机。另外,由于应该帮助我解决BL的人是JavaScript开发人员,因此在这种情况下,使用JavaScript解释器而不是存根编
-
8.3 内存管理
一、内存连续分配 主要是指动态分区分配时所采用的几种算法。 动态分区分配又称为可变分区分配,是一种动态划分内存的分区方法。这种分区方法不预先将内存划分,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。因此系统中分区的大小和数目是可变的。 首次适应(First Fit)算法: 空闲分区以地址递增的次序链接。分配内存时顺序查找,找到大小能满足要求的第一个空闲分区。
-
Python内存泄漏
问题内容: 我有一个长时间运行的脚本,如果让脚本运行足够长的时间,它将消耗系统上的所有内存。 在不详细介绍脚本的情况下,我有两个问题: 是否有可遵循的“最佳实践”,以防止泄漏发生? 有什么技术可以调试Python中的内存泄漏? 问题答案: 看看这篇文章:跟踪python内存泄漏 另外,请注意,垃圾收集模块实际上可以设置调试标志。看一下功能。此外,请查看Gnibbler的这段代码,以确定调用后已创建
-
nodejs内存不足
问题内容: 我今天遇到一个奇怪的问题。对于其他人来说,这可能是一个简单的答案,但这让我感到困惑。为什么下面的代码会导致内存错误? 我得到了这两个错误之一…第一个是在节点的解释器中运行此代码时,第二个是通过nodeunit运行它时: 严重错误:CALL_AND_RETRY_2分配失败-内存不足 严重错误:JS分配失败-内存不足 问题答案: 当我尝试访问阵列时会发生这种情况。但是获取长度却没有。
-
Java 内存泄漏
本文向大家介绍Java 内存泄漏,包括了Java 内存泄漏的使用技巧和注意事项,需要的朋友参考一下 在Java中,垃圾回收(析构函数的工作)是使用垃圾回收自动完成的。但是,如果代码中有引用它们的对象怎么办?它无法取消分配,即无法清除其内存。如果这种情况一再发生,并且创建或引用的对象根本没有被使用,它们就会变得无用。这就是所谓的内存泄漏。 如果超过了内存限制,则程序将通过抛出错误(即“ OutOfM
-
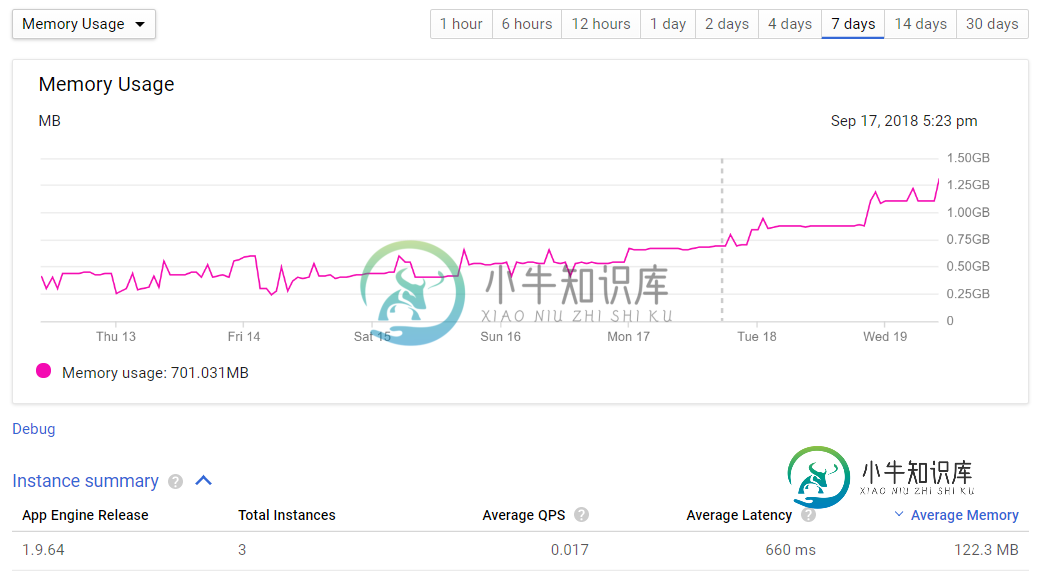 软内存使用
软内存使用我是新来的谷歌应用程序引擎,但试图找到我的应用程序消耗多少软内存的真正来源。 我正在标准环境中运行F1实例类(128MB内存限制),尚未出现“软内存超出”错误。 我用来检查内存的工具有: GoogleAppEngine仪表板(内存使用量图表)——显示了过去一周内存使用量从250MB逐渐增加到1GB以上。请参阅下面的第一张图片 GoogleAppEngine仪表板(实例摘要表)-显示122MB的平均
-
Informix内存泄漏
问题内容: 我使用Informix遇到了一个奇怪的问题(具体来说,我使用的是IBM.Data.Informix命名空间,即4.10 Client SDK)。我正在使用ODBC连接到IBM Informix数据库,并且遇到内存泄漏问题。该文档相当稀疏,并且我只能使用当前安装的驱动程序/ SDK。这是我用于数据库上下文的代码: } 我已尝试处置并关闭所有可以的连接,但这似乎无济于事。我是否缺少某些东西
-
CPython内存分配
问题内容: 这是一篇受此评论启发的帖子,内容涉及如何在CPython中为对象分配内存。最初,这是在创建列表并将其添加到for循环中_以_ 实现列表理解的上下文中。 所以这是我的问题: CPython中有多少个不同的分配器? 每个功能是什么? 什么时候被正式称为?(根据此评论中的内容,列表理解可能不会导致调用, python在启动时会为其分配多少内存? 是否有规则来控制哪些数据结构在此存储器上首先获