《内存淘汰》专题
-
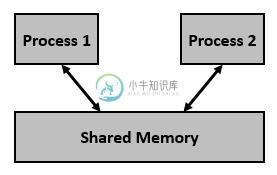 共享内存
共享内存共享内存是两个或多个进程共享的内存。 但是,为什么我们需要共享内存或其他通信方式呢? 重申一下,每个进程都有自己的地址空间,如果任何进程想要将自己的地址空间的某些信息与其他进程进行通信,那么只能通过IPC(进程间通信)技术进行。 我们已经知道,通信可以在相关或不相关的进程之间进行。 通常,使用管道或命名管道来执行相互关联的进程通信。 可以使用命名管道或通过共享内存和消息队列的常用IPC技术执行无关
-
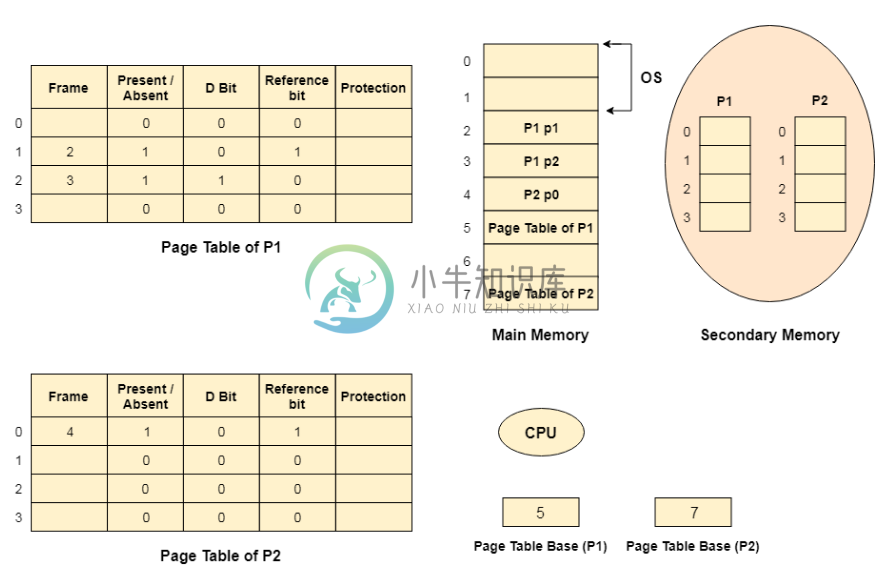 虚拟内存
虚拟内存主要内容:虚拟内存如何工作?,按需分页,虚拟内存管理系统的快照虚拟内存是一种存储方案,为用户提供了一个拥有非常大的主内存的幻觉。 这是通过将辅助存储器的一部分作为主存储器来完成的。 在这种方案中,用户可以加载比可用主存更大的进程,因为存在内存可用于加载进程的错觉。 操作系统不是在主内存中加载一个大进程,而是在主内存中加载多个进程的不同部分。 通过这样做,多程序的程度将会增加,因此CPU利用率也会增加。 虚拟内存如何工作? 在现代语言中,虚拟内存近来变得非常普
-
C#内存流
我在使用SharpZipLib的GZipInputStream编写未压缩的GZIP流时遇到问题。我似乎只能获得256字节的数据,其余的数据没有写入并保留为零。已检查压缩流(compressedSection),所有数据都在那里(1500字节)。解压缩过程的片段如下: 因此,在这段代码中: 1) 压缩的部分被传入,准备解压缩。 2) 未压缩输出的预期大小(以2字节小endian值的形式存储在文件头中
-
内存溢出?
JNIEXPORT jint JNICALL Java_nc_mes_pub_hardware_PCI1761_readChanel(JNIEnv*,jobject,jint channel){ }
-
内存不足
我正在努力解决古老的字谜问题。多亏了许多教程,我能够迭代一组字符串,递归地找到所有的排列,然后将它们与英语单词列表进行比较。我发现的问题是,在大约三个单词之后(通常是关于“变形”之类的东西),我会得到一个OutOfMemory错误。我试着把我的批分成小的集合,因为它似乎是消耗我所有内存的递归部分。但即使只是“变形”也把它锁起来了... 编辑:根据出色的反馈,我已经将生成器从排列更改为工作查找: 它
-
内存篇 - heapdump
2.2.1 使用 heapdump heapdump 是一个 dump V8 堆信息的工具。v8-profiler 也包含了这个功能,这两个工具的原理都是一致的,都是 v8::Isolate::GetCurrent()->GetHeapProfiler()->TakeHeapSnapshot(title, control),但是 heapdump 的使用简单些。下面我们以 heapdump 为例讲
-
内存占用
【内存占用】页面主要展示项目运行过程中内存的使用情况,主要包括以下几个部分: 数据汇总 该项主要展示项目运行过程中的 “总内存峰值”、“堆内存峰值”、“GFX内存峰值” 和 “泄露风险”。其中,总内存为Unity引擎所统计的真实物理内存分配,并不包含系统缓存和第三方库的自身分配内存; 堆内存所指的是 Mono 管理和分配的托管堆内存; GFX内存为用于渲染的资源所占用的内存,主要包括纹理资源、网格
-
内存安全
内存安全 Rust推崇安全与速度至上,它没有垃圾回收机制,却成功实现了内存安全 (memory safety)。 所有权 在Rust中,所有权 (ownership) 系统是零成本抽象 (zero-cost abstraction) 的一个主要例子。 对所有权的分析是在编译阶段就完成的,并不带来任何运行时成本 (run-time cost)。 默认情况下,Rust是在栈 (stack) 上分配内存
-
内存同步
9.4. 内存同步 你可能比较纠结为什么Balance方法需要用到互斥条件,无论是基于channel还是基于互斥量。毕竟和存款不一样,它只由一个简单的操作组成,所以不会碰到其它goroutine在其执行"期间"执行其它的逻辑的风险。这里使用mutex有两方面考虑。第一Balance不会在其它操作比如Withdraw“中间”执行。第二(更重要)的是"同步"不仅仅是一堆goroutine执行顺序的问题
-
内存调优
调整内存的使用以及Spark应用程序的垃圾回收行为已经在Spark优化指南中详细介绍。在这一节,我们重点介绍几个强烈推荐的自定义选项,它们可以 减少Spark Streaming应用程序垃圾回收的相关暂停,获得更稳定的批处理时间。 Default persistence level of DStreams:和RDDs不同的是,默认的持久化级别是序列化数据到内存中(DStream是StorageLe
-
内存管理
对于一个基于图论的框架来说,节点和边是最小的部件。实际应用中,这些部件构成了各种有向图。比如一个有环图,它的数据流动就是一个环形,部件之间的持有关系如果不能很好的处理,那么可能就会存在内存问题。EasyReact 的内存管理逻辑非常简单,也非常精巧。可以让框架使用者无需关注太多的细节即可轻松的使用,而不必担心本框架涉及的内存方面的问题。 中间节点 节点包含了 fork、map、filter、ski
-
内存管理
在计算系统中,通常存储空间可以分为两种:内部存储空间和外部存储空间。内部存储空间通常访问速度比较快,能够按照变量地址随机地访问,也就是我们通常所说的 RAM(随机存储器),可以把它理解为电脑的内存;而外部存储空间内所保存的内容相对来说比较固定,即使掉电后数据也不会丢失,这就是通常所讲的 ROM(只读存储器),可以把它理解为电脑的硬盘。 计算机系统中,变量、中间数据一般存放在 RAM 中,只有在实际
-
内存管理
内存生命周期 垃圾回收 垃圾回收在计算机科学中是一种自动的内存管理机制。当一个计算机上的动态内存不再需要时,就应该予以释放以让出内存,这种内存资源管理称为垃圾回收。垃圾回收器可以让程序员减轻许多负担,也减少程序员犯错的机会。 特征 垃圾回收基于两个原理: 考虑某个对象在未来的程序运行中将不会被访问; 向这些对象要求归还内存。 然而,最主要的也是最艰难的部分就是找到「所分配的内存确实已经不再需要了」
-
6.1 内存池
概述 Go的内存分配器采用了跟tcmalloc库相同的实现,是一个带内存池的分配器,底层直接调用操作系统的mmap等函数。 作为一个内存池,回忆一下跟它相关的基本部分。首先,它会向操作系统申请大块内存,自己管理这部分内存。然后,它是一个池子,当上层释放内存时它不实际归还给操作系统,而是放回池子重复利用。接着,内存管理中必然会考虑的就是内存碎片问题,如果尽量避免内存碎片,提高内存利用率,像操作系统中
-
内存模型
(译注:这一个item有相当深的理论深度,原文也比较晦涩难懂,翻译者提醒大家,最好参照原文理解,如果翻译中有什么不恰当的地方,还请批评指出,不胜感谢。) 所谓“内存模型”,是计算机(硬件)体系结构与编译器双方之间的一种约定。有了它,大多数程序员便不用处处考虑日新月异的计算机硬件细节。如果没有内存模型,那么线程机制、锁机制及无锁编程等都无从谈起。 内存模型的最关键保证是:两个线程可以各自独立地存取各