
软内存使用

我是新来的谷歌应用程序引擎,但试图找到我的应用程序消耗多少软内存的真正来源。
我正在标准环境中运行F1实例类(128MB内存限制),尚未出现“软内存超出”错误。
我用来检查内存的工具有:
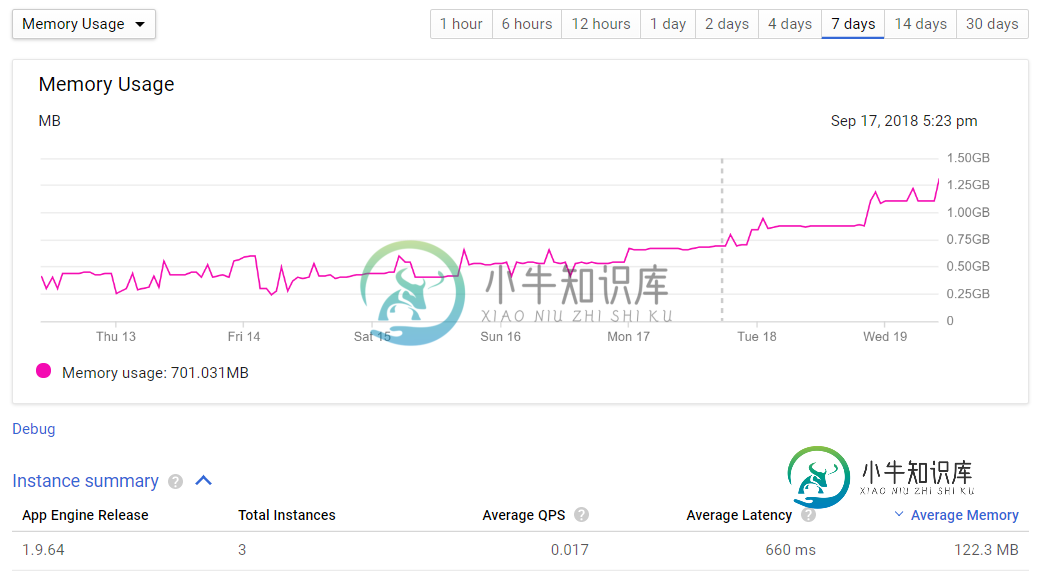
- GoogleAppEngine仪表板(内存使用量图表)——显示了过去一周内存使用量从250MB逐渐增加到1GB以上。请参阅下面的第一张图片
- GoogleAppEngine仪表板(实例摘要表)-显示122MB的平均内存使用量。请参阅下面的第一张图片
- 日志记录运行时。memory_usage()-显示全天120MB到160MB之间的范围
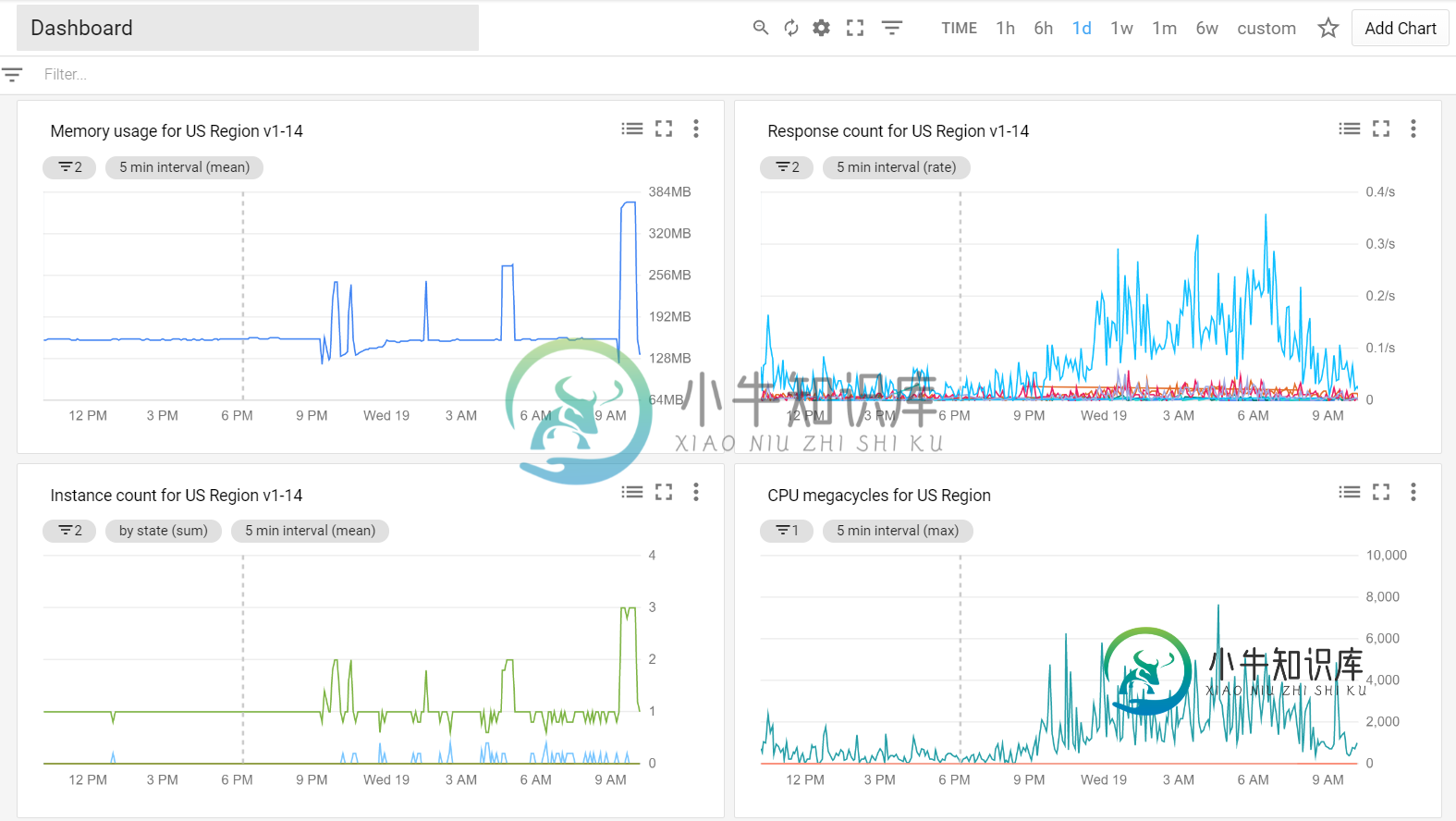
- Stackdriver监控-显示内存大部分徘徊在150MB左右,但随着新实例的产生而出现峰值。请参阅下面的第二幅图
感谢任何关于我应该使用哪个信息源来确定应用程序的实际内存使用的指导,以及谷歌将使用什么来抛出软内存错误。
应用程序引擎仪表板:
堆垛机监控:
共有1个答案

当您达到软限制时,应用程序引擎不会引发异常。相反,您的实例将正常地重新启动(停止接受新请求,完成所有现有请求,然后关闭)。
在第一个图中,“250MB到1GB以上”是所有应用程序引擎实例的总内存使用量。您可以在实例汇总表中看到,每个实例的平均内存为122.3MB,因此它处于软限制之下。
堆栈驱动程序图显示了一个区域的聚合内存使用情况。您可以看到内存中的尖峰与同时运行的多个实例相关。
-
我们有一个可怕的经验与gae围棋。当我们的应用程序是一个免费的,我们从来没有超过软私有内存限制的问题。我们抢了定额,因此决定付款。我们每天的预算定为3美元。付费服务激活后,我们可以再次使用该网站,超额配额消失了。几个小时后,我们得到了这个超软私有内存限制,除了这个,再也看不到任何东西了。我试图清除数据存储中的一些大数据,禁用内置插件,但仍然没有运气。 我在代码中做了一些测试,以确定故障来自何处。删
-
我有一个linux用户,软虚拟内存限制(ulimit-v)设置为aroud 5GB。 考虑到这一点,我试着做: 我的问题是:我关于ulimit-v>=VmSizes之和的假设正确吗?如果不是,软限制实际上是什么意思?是否有可能超过特定用户的软限制,并仍然可以接受它? 顺便说一句,ulimit-v-h被设置为unlimited,这有什么不同。
-
我想了解为什么多次动态分配调用的数据比直接在代码中指定的或通过的单个调用分配的数据使用如此多的内存。 例如,我用C编写了以下两个代码: 测试1.c:int x用malloc分配 我在这里没有使用free来保持简单。当程序等待交互时,我查看另一个终端中的顶级功能,它向我显示了以下内容: test2. c: int x不是动态分配的 顶部显示: 我还编写了第三个代码,其结果与test2相同,我在tes
-
Pika内存占用 rocksdb 内存占用 pika 内存占用(tcmalloc 占用) 1. rocksdb 内存占用 命令行命令 info data used_memory_human = db_memtable_usage + db_tablereader_usage 相应配置及对应影响参数 write-buffer-size => db_memtable_usage max-write-b
-
在并发编程的传统线程模型中,线程之间的数据共享需要通过锁来保持一致性(consistentBalance),当数据产生变化时,还需要使用条件变量(condition variable)对各个线程进行通知。 某种程度上,Haskell 的 MVar 机制对上面提到的工具进行了改进,但是,它仍然带有和这些工具一样的缺陷: 因为忘记使用锁而导致条件竞争(race condition) 因为不正确的加锁顺
-
在python上的GoogleAppEngine中,我遇到了以下错误:在服务了总共2个请求后,超过了128 MB的软私有内存限制,达到了157 MB。我尝试使用以下命令来解决这个问题。上下文=ndb。获取上下文()和上下文。设置缓存策略(False)。我把这个方法放在appengine\u配置中。py,也在应该处理请求的处理程序中。我想知道是否还有其他地方可以放置这个命令,或者我是否应该总共使用一