《数据仓库》专题
-
Spring JPA数据仓库
我正在努力让Spring JPA Data为我工作,但一直在努力。问题出在这里。 我有两个域类,它们之间有一个简单的一对多关系: 我已经为每个类设置了存储库接口:CardRepository,扩展JpaRepository的用户存储库,两个存储库都注入到服务中 非常基本的设置。someMethod() 出现问题,其中我用它的标识符查询了一个用户,然后尝试获取映射@OneToMany的列表,然后发生
-
Spring数据仓库StackOverflow
在使用Spring数据存储库时发现一些奇怪的行为。 我写了这些类和接口: 当我尝试测试UserRepositoryImpl时,java。lang.StackOverflowerr被抛出 我发现save()方法存在一些问题。此外,delete()方法会引发stackoverflow。 我已经找到了解决办法。当我更改将存储库接口扩展为(例如)JpaUserRepository的接口的名称时,我的问题就
-
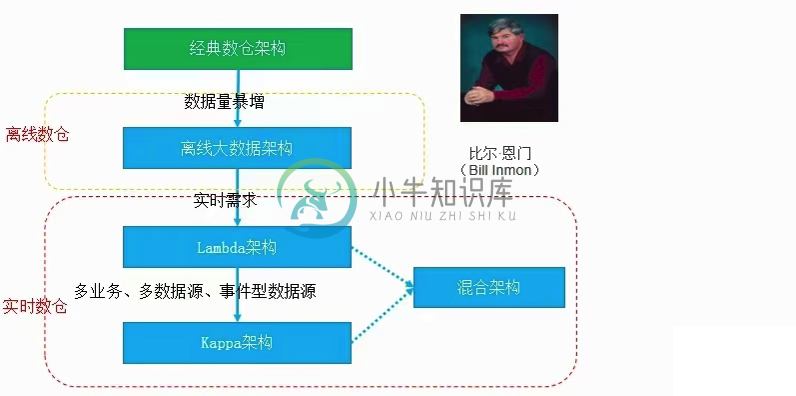 数据仓库发展
数据仓库发展主要内容:1.离线数仓,2.Lambda架构,3.Kappa架构,4.Smack架构,5.湖仓一体传统数仓 离线数仓 实时数仓 Lambda架构 Kappa架构 Smack架构 数据湖架构 仓湖一体架构 1.离线数仓 2.Lambda架构 Lambda架构是大数据平台里最成熟、最稳定的架构,它的核心思想是:将批处理作业和实时流处理作业分离,各自独立运行,资源互相隔离。 (1)Batch Laye:主要负责所有的批处理操作,支撑该层的技术以Hive、Spark-SQL或MapReduce这类批处
-
ebay-数据仓库面试
英文自我介绍和项目介绍 Good Afternoon, my name is Wang Longjiang,graduated from Anhui University. I have been working in the Institute of Aerospace Information, Chinese Academy of Sciences for two years. Focus o
-
 数据仓库:ELT和ETL
数据仓库:ELT和ETL主要内容:1.ETL,2.ELT,3.ELT的演变,4.ELT的工作原理,5.什么时候我们选择ELT,6.数据湖是不是很好的ELT落脚点,7.总结ETL 和 ELT 有很多共同点,从本质上讲,每种集成方法都可以将数据从源端抽取到数据仓库中,两者的区别在于数据在哪里进行转换 1.ETL ETL - 抽取、转换、加载 从不同的数据源抽取信息,将其转换为根据业务定义的格式,然后将其加载到其他数据库或数据仓库中。另一种 ETL 集成方法是反向 ETL,它将结构化数据从数据仓库中加载到业务数据库中,如我们
-
 知乎 数据仓库 凉经
知乎 数据仓库 凉经写在前面:这段时间经过了一段高强度笔面,但还是颗粒无收 面试 面试官进来就说:你不会flink? 我:了解的不多 那我们这次可能通过概率不大,但我们仍然可以就大数据来一波交流 实时: Flink的checkpoint Flink的反压 Flink的状态后端 离线: Kafka的有序性(不可全局有序,但可分区有序)面试官说不对??我让他下去再好好看看 Kafka一定不会丢数据嘛? Spark的内存模
-
 社招-数据仓库面试
社招-数据仓库面试Gaussdb是什么数据库 Gaussdb和Doris有什么区别 数据湖和数据仓库有什么区别 hudi中你们用的哪种表类型 hudi怎么实现实时数据更新的 HIVE有哪些模块 知道HIVE的thrift吗,有什么好处 生产中是用哪种方式连接HIVE的,会用jdbc连接吗 知道哪些spark的运行模式 yarn-client和yarn-cluster的区别是什么,从中选一个运行模式具体介绍下 sel
-
Spring Boot数据redis仓库@Id注释vs jpa仓库@Id
我使用的是spring boot 1.5.2和spring boot数据redis 1.8。 我有两个@Id注释,一个用于JPA,另一个用于redis哈希。这里我想使用由mysql主键自动增量生成的JPA@Id值。 但我发现每次使用redis@Id注释时,redis中我的Id都会是另一个随机值,但我想使用mysql主键。 我的实体是这样的: 我的服务是这样的: 我得到了以下错误: redis的数据
-
Spring数据仓库和DAO Java泛型
阅读有关在DAO层中使用Java泛型的信息,我怀疑将其应用于spring数据存储库。我的意思是,使用 spring 数据存储库,你有这样的东西: 但是如果我有其他10个实体,我必须创建10个类似于上面的接口来执行CRUD操作等等,我认为这不是很可扩展的。Java Generics和DAO是关于创建一个接口和一个实现,并将其用于实体,但使用Spring数据存储库,我必须为每个实体创建一个界面,因此。
-
 货拉拉 数据仓库实习生
货拉拉 数据仓库实习生由于已经离职了,就发一下面经把 一面 自我介绍 项目 数仓怎么分层 数据倾斜怎么处理 join优化 实时数仓和离线数仓的定位 能实习多久 反问 数据量多少进去干什么工作对我的建议 进去主要负责什么 二面 说一下MR的执行流程 内部表和外部表的区别 其他记不太清了,主要是一些基本的数仓八股文
-
 吉利汽车 数据仓库 凉经
吉利汽车 数据仓库 凉经8.25 18min 1.自我介绍 2.专业介绍 3.大学期间相关经历 4.实习工作 5.数仓分层 6.主题域划分标准 7.数仓建模 8.项目中组件作用 9.反问 主要是深挖项目和细节 #秋招##24秋招##数据人的面试交流地#
-
 微网优联 数据仓库 面经
微网优联 数据仓库 面经Timeline: 10.14 投递 10.18 一面 10.25 二面 10.18 一面 21min: 1.项目介绍 2.具体数据表 3.存储数据量达到多少 4.Mysql数据类型 5.聚集索引和非聚集索引 6.怎么处理数据丢失 7.对redis的理解 8.http协议 9.了解的基础数据结构与算法 10.介绍一种排序算法 11.怎么远程连接到linux服务器 12.部署过服务器吗 10
-
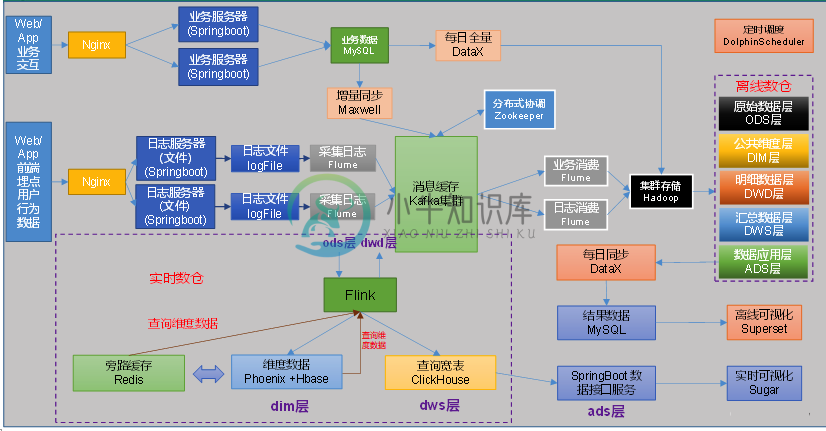 数据仓库建模过程分析
数据仓库建模过程分析主要内容:1.数据仓库概述,2.数据仓库建模概述,3.维度建模理论之事实表,4.维度建模理论之维度表,5.数据仓库设计1.数据仓库概述 1.1 数据仓库概念 数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。 1.2 数据仓库核心架构 2.数据仓库建模概述 2.1 数据仓库建模的意义 数据模型就是
-
数据仓库和运营数据库之间的区别
本文向大家介绍数据仓库和运营数据库之间的区别,包括了数据仓库和运营数据库之间的区别的使用技巧和注意事项,需要的朋友参考一下 数据仓库是用于结构化,经过过滤的数据的存储库,该数据已针对特定目的进行了处理。数据软件从多个来源收集数据,并使用ETL流程转换数据,然后将其加载到数据仓库中以用于业务目的。 运营数据库是那些数据经常更改的数据库。它们主要设计用于大量数据交易。它们是数据仓库的源数据库,用于维护
-
 快手数据研发一面(大数据、数仓、数开)
快手数据研发一面(大数据、数仓、数开)项目为sgg经典离线数仓 1. 自我介绍 2. 项目介绍(难点、亮点) 3. 根据难点亮点提问 4. 数据域是什么,如何划分数据域,为什么这样划分数据域 5. DIM层维度表的设计原则 6. DWD层事实表设计要点 7. mapreduce shuffle流程 8. maptask和reduce task 与哪些因素有关 9. 数据热点(数据倾斜)在哪些场景下出现,如何解决 10. spark是为