《数据仓库》专题
-
从HDInsight OnDemand连接到SQL数据仓库
我正在尝试从spark on demand HDInsight集群向Azure SQL数据仓库读/写数据。 通过使用脚本操作来安装jdbc驱动程序,我可以在普通的HDInsight spark集群上实现这一点,但我认为不可能在按需集群上运行脚本操作。 我试过了 正在从%user%复制文件。m2\repository\com\microsoft\sqlserver\mssql jdbc\6.2.2。
-
 2022/09/21 携程数据仓库(已OC)
2022/09/21 携程数据仓库(已OC)2022/09/06 一面 50min 实习在做什么 介绍一下实习项目 你在这个项目做了什么 为什么用click house click house库引擎 表引擎 click house优缺点 DataX什么作用 数据倾斜 spark有用过吗 小文件怎么处理 spark任务慢怎么查看问题 RDD说一下 spark宽依赖 spark application job stage task的关系
-
 9.3-微众银行-数据仓库-笔试
9.3-微众银行-数据仓库-笔试一、选择题 总计20道 408内容+大数据相关 有单选,也有多选 二、编程题 两道很简单,第一次笔试AK 第一题:随机播放器 直接用queue搞定 import java.util.LinkedList; import java.util.Queue; import java.util.Scanner; public class Main { public static void ma
-
 好未来 数据仓库开发实习
好未来 数据仓库开发实习一面 项目深挖 数仓分几层,每一层的作用 事实表如何设计 维度表如何设计 数据域如何划分 业务总线矩阵的概念 如何设计完整的指标 开发中和上线后数据质量如何保证 如何设计调度,依据是什么 hive数据倾斜解决办法 hivesql常见优化手段 什么是spark宽窄依赖,起到什么作用 sql题:用户连续登录游戏的最大天数,允许间隔一天 反问 做什么业务 教培业务中的线下面授分析 网络问题迟到了一会,面
-
 携程 数据仓库工程师 面经
携程 数据仓库工程师 面经火车票业务 有点久远一直忘了写,就记得这么多 一面: 1、自我介绍 2、聊实习,扣细节 3、聊实习项目技术难点,聊到了我用later view遇到的坑,面试官直接激动,并表示他前几天也碰到了这个坑,两边都很惊喜,直接惺惺相惜 4、聊竞赛经历,内容以及遇到的难点 5、开始八股,写吐了,这里就省略了,要看的看我之前的帖子 6、sql题,是啥忘了,难度中等吧 7、反问 二面 主管面: 1、自我介绍 2、
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
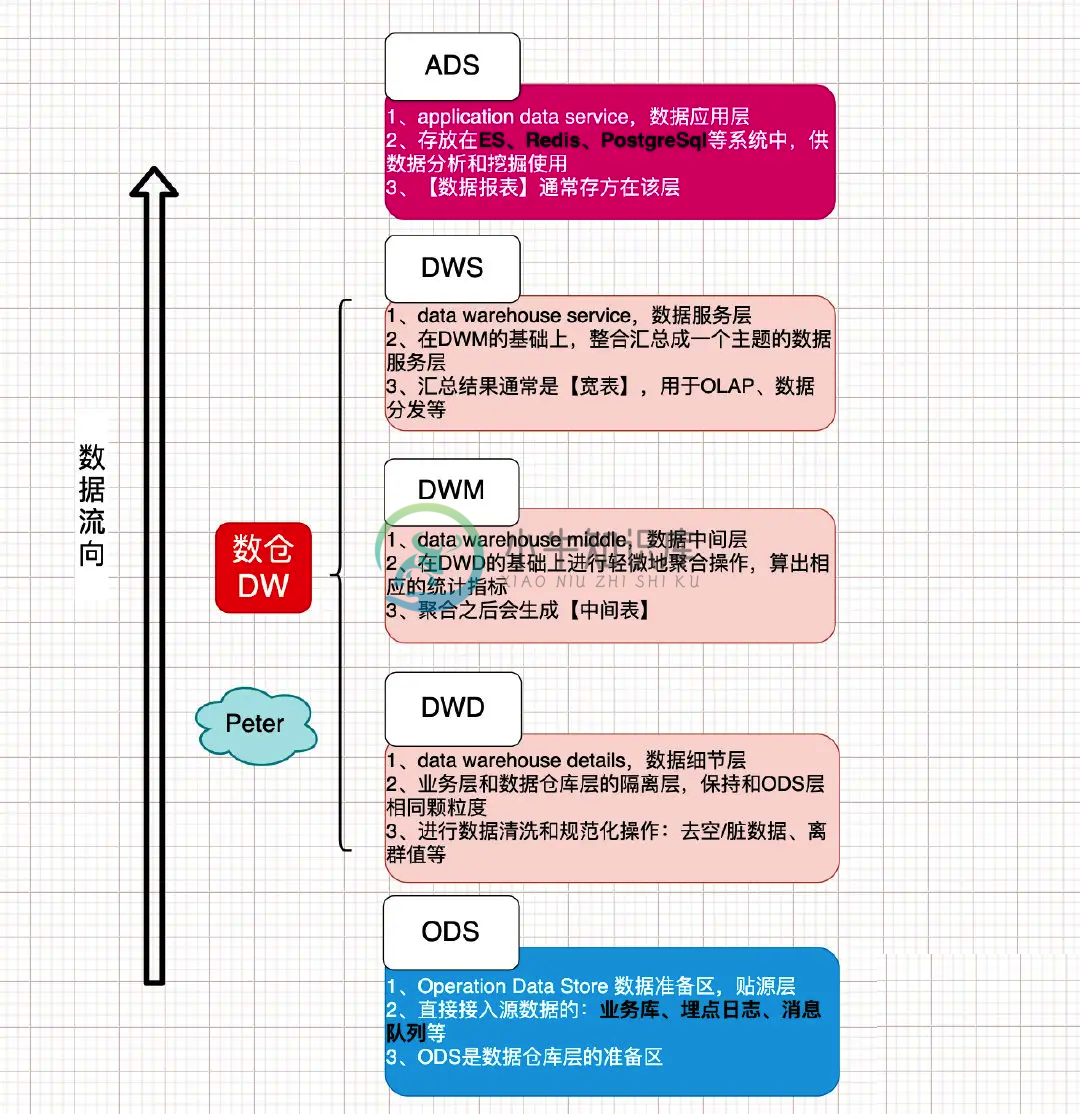 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
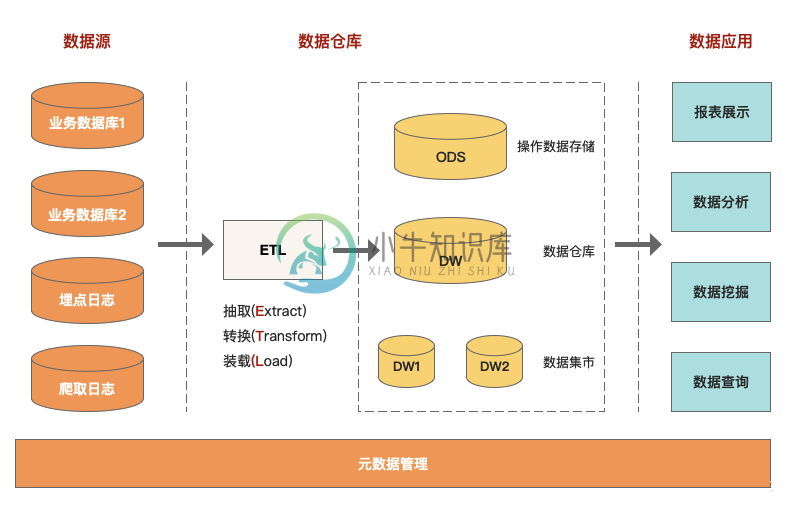 大数据数仓高级面试题 2
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
 5.14 携程数仓(数据开发)一面
5.14 携程数仓(数据开发)一面40min 1. 自我介绍 2. 用户行为漏斗分析,从ods层开始全链路步骤,埋点如何设计,应该关注哪些触发的动作 采集到ods层的数据什么样的,有哪些字段 dwd层设计了哪些事实表 dim维度又有哪些表 dws层汇总聚合了哪些表与用户行为漏斗有关,这些表怎么设计的 最后ads层漏斗分析怎么做,如何可视化 3. 手撕sql 连续7天登录 4. 反问
-
 上海银行大数据开发(数仓)数据一面
上海银行大数据开发(数仓)数据一面离线数仓项目介绍 hdfs读流程 hdfs 中datanode怎么与namenode交互 mr过程 hive数据倾斜,介绍原因和解决方案 介绍一下网络结构,tcp在哪一层 java有哪些集合类 介绍java接口 MySQL索引 数据结构(B+树) 反问 上海银行数仓技术框架
-
nosql:MongoDB、Cassandra或数据仓库的替代方案
我陷入了关于是否使用MongoDB或Cassandra来满足我的数据库需求的具体决定之间,并希望对我的用例进行输入以指导我的决定。 要求: 数据源 X个包含Y个服务器的数据中心。 每个服务器有N个网络和M个统计数据。 e、 g.目前(3个数据中心、50台服务器、19个网络和10个统计数据)。这些数字会随着时间的推移而增加。 数据获取: 每小时为每台服务器解析一个xml页面(约20kb/页)。(~2
-
将Spark SchemaRDD保存到Hive数据仓库中
我们有很多Json日志,并且希望构建我们的Hive数据仓库。将Json日志获取到spark schemaRDD中很容易,并且schemaRDD有一个saveAsTable方法,但它只适用于从HiveContext创建的Schemards,而不是从常规SQLContext创建的Schemards。当我试图使用从Json文件创建的schemaRDD保存Eastable时,它会抛出异常。有没有办法强制它
-
 美团数据仓库工程师一面 40min
美团数据仓库工程师一面 40min👥 面试题目 1.自我介绍,能不能从几个方面说一下项目 2.有什么收获 3.简历里面哪个技术学的最好 4.spark的client模式和集群模式 5.yarn 6.能够重分区的算子 7.为什么用rdd,不用df和ds,他们的区别 8.为什么spark比mapreduce更快(磁盘io和进程线程模型) 9.spark也会OOM和溢写磁盘啊,mapreduce也有缓冲区啊,都是内存计算,为什么更快(
-
 敦煌网数据仓库实习生面试
敦煌网数据仓库实习生面试敦煌网(电商公司面试)(感觉像是kpi面试啊) 居然没要求开摄像头真是奇怪啊。 首先上来自我介绍,然后等我介绍到在滴滴实习的时候打断了我让我展开说说,之后就这段实习经历提问了很多,譬如如何处理数据异常,如何进行A/Btest等;接着是学校经历,问我大数据相关的课程有哪些,有看过阿里的大数据架构之类的书吗?回答没有,过(阿里的书这么受欢迎吗?啊,这就是强者盲从效应吗?)到