《数据仓库》专题
-
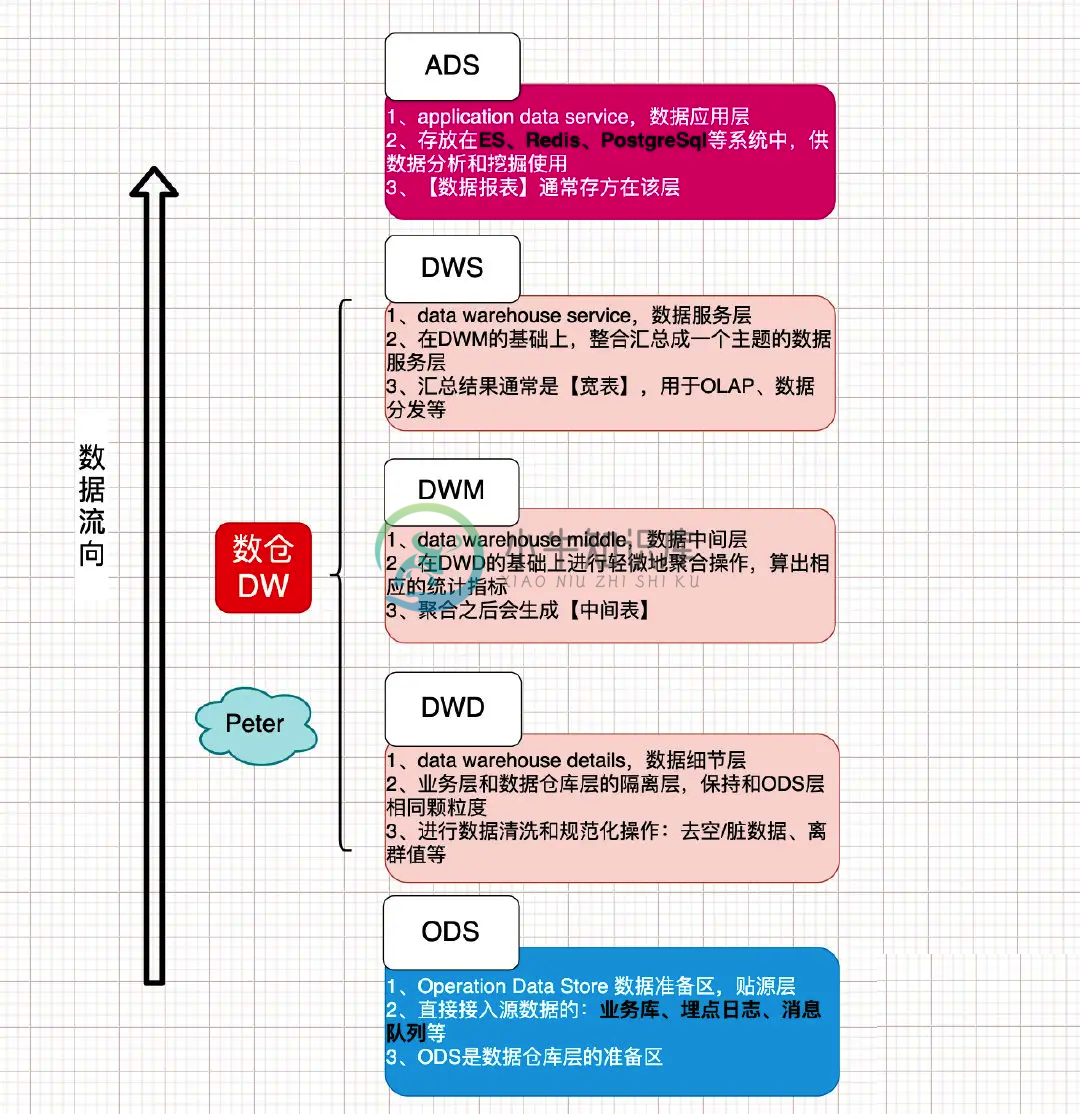 大数据数仓高级面试题【8道】
大数据数仓高级面试题【8道】主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
 携程数据仓库工程师一面凉经
携程数据仓库工程师一面凉经1 . 自我介绍 2.面试官,你们有教过大数据技术吗?应该没教过吧? 2.spark为什么比MapReduce快 3.spark算子链 4.问项目 5.Sql调优 6数据倾斜 6.一道sql题,思路,之前笔试做过,但只过了2/3 7.有接触过flink实时计算框架吗? 8.MySQL索引是越多越好吗?索引类型?什么时候用聚簇索引,什么时候用非聚簇索引 9.反问。 面试官挺好的,是我太菜了,一些没答
-
使用 azure databricks scala 将数据从 blob 存储加载到 sql 数据仓库
我正在尝试使用 azure databricks scala 将数据从 blob 存储加载到 SQL 数据仓库中。 我收到这个错误 潜在的SQLException:-com.microsoft.sqlserver.jdbc.SQLServerException:由于内部错误,外部文件访问失败:“访问HDFS时发生错误:Java调用HdfsBridge_IsDirExist时引发的异常。Java异常
-
将generic作为实体类型的Spring数据仓库
我想在我的项目中使用SpringDataJPA存储库。通常我创建自己的存储库 但是,我想提供符合以下条件的更复杂的情况: > 我有一个具有共同定义的基本实体: 我有扩展上述实体的所有其他实体,例如: 和
-
 人大金仓数据库测试一面面经(10.26)
人大金仓数据库测试一面面经(10.26)1.自我介绍 2.数据库语言,DDL,DQL,DML... 3.考察数据库语言,建表,更改等 4.事务的四大特性 5.利用session模拟读已提交(完蛋,一点都不会) 6.对隔离的理解 7.项目中你如何进行测试,自己的项目 8.使用什么进行测试的,Jmeter 9.Jmeter怎么进行并发的检测,设置线程数(问性能测试) 10.linux的基本命令 11.软件测试模型VW 12.熟悉python
-
 杭州电魂数据开发-数仓方向一面
杭州电魂数据开发-数仓方向一面1.分区表 2.Hive和Spark的区别 3.为什么要来数据开发,了解数据开发吗 4.维度建模 5.项目相关问题 6.对UDF、UDAF、UDTF三者的理解 7.数据格式Parquet、ORC、Avro 8.Parquet、ORC的区别 9.分层的作用 .......... 总的来说和面试官沟通的过程中也学到了很多,但是感觉通过希望不大,好多都没答上来
-
仓库
Repository,仓库,简称 Repo。为项目添加一个 Git 仓库以后,你就可以用 Git 为项目做版本控制了。 git init 上面的命令可以为项目初始化一个仓库,这个动作只需要执行一次,它会在项目下面创建一个 .git 目录,Git 会把它需要的东西存储在这个 .git 目录里面,它其实就是项目的仓库。 练习 1,创建一个项目。打开你的命令行界面,执行: cd ~/desktop m
-
仓库
仓库(Repository),这里指的是可以使用包管理工具安装的软件包的列表。系统自带一些仓库,如果你发现要安装的包在这些仓库里不存在,你可能需要在系统上安装额外的仓库。 仓库列表 先查看一下安装在系统上的仓库列表,执行: yum repolist 返回类似的东西: repo id repo name
-
仓库
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。 一个 Docker Registry 中可以包含多个 仓库(Repository);每个仓库可以包含多个 标签(Tag);每个标签对应一个镜像。 通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的
-
使用JDBC连接到Azure SQL数据仓库时的SQLException
* 我在这里看到过关于连接到SQLServer DB的类似问题。 我将数据库配置为允许使用此处的过程访问我的IP。 请帮助我解决这个问题。
-
Azure数据仓库的Azure blob存储网络规则(Ip)
我需要使用Polybase将外部数据(在blob存储中)加载到我的Azure数据仓库。当我使用经典Azure存储时,它运行良好。 最近,我必须将我们的存储更新到ARM,我不知道如何将ARM存储上的防火墙规则设置到我的Azure数据仓库。如果我将防火墙设置为“所有网络”,一切都可以无缝运行。但是,我不能让blob大开。 我尝试使用nslookup为我们的Azure数据仓库查找出站ip,并将值放入存储
-
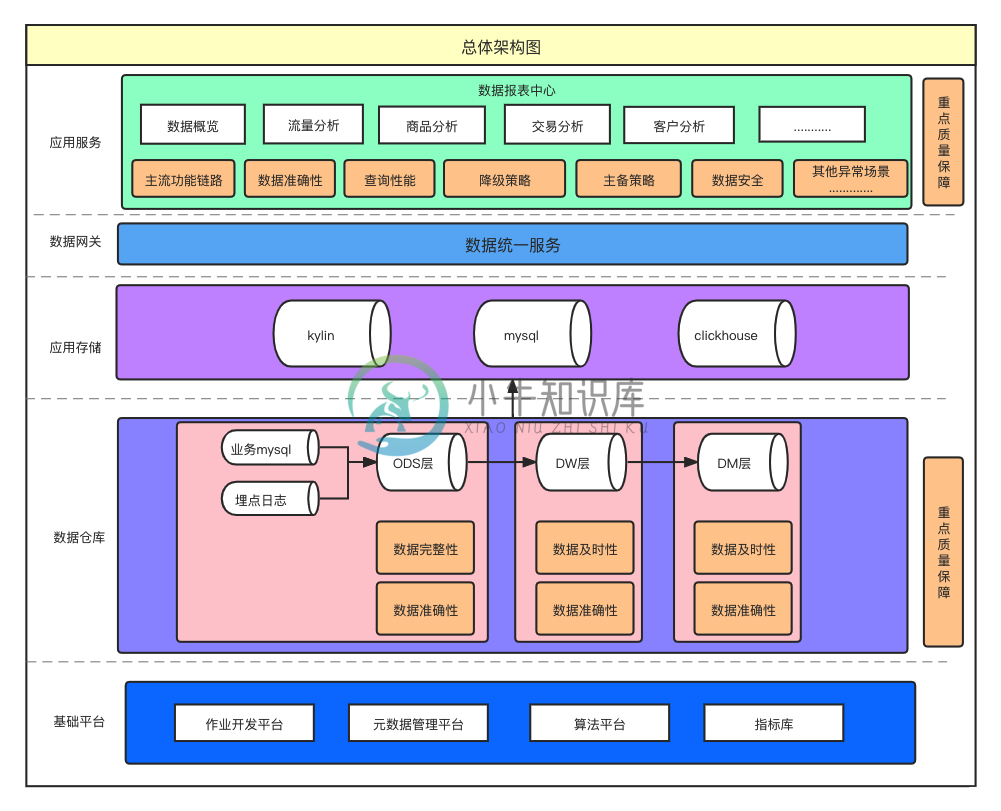 数仓链路保障体系与数据测试方法
数仓链路保障体系与数据测试方法主要内容:1.数据链路介绍,2.数据层测试,3.应用层测试,4.后续规划1.数据链路介绍 应用服务层、数据网关层、应用存储层、数据仓库,并且作业开发、元数据管理等平台为数据计算、任务调度以及数据查询提供了基础能力。 对于质量把控来说,最核心的两个部分是:数据仓库以及数据应用部分。因为这两部分属于数据链路中的核心环节,相对于其他层级而言,日常改动也更为频繁,出现问题的风险也比较大。 2.数据层测试 数据层的质量保障,可以分成三个方面:数据及时性、完整性、准确性。 2.1
-
详解Maven仓库之本地仓库、远程仓库
本文向大家介绍详解Maven仓库之本地仓库、远程仓库,包括了详解Maven仓库之本地仓库、远程仓库的使用技巧和注意事项,需要的朋友参考一下 什么是Maven仓库 在不用Maven的时候,比如说以前我们用Ant构建项目,在项目目录下,往往会看到一个名为/lib的子目录,那里存放着各类第三方依赖jar文件,如log4j.jar,junit.jar等等。 每建立一个项目,你都需要建立这样的一个/lib目
-
 菜鸟数仓一面
菜鸟数仓一面电话面 基本没有八股 1.自我介绍重点让说项目和实习 深挖项目和实习经历 a.什么是数据倾斜,实习中遇到过吗怎么处理 b.项目中数仓怎么搭建,为什么这么的分层 2.说出一个自己遇到的技术问题怎么解决的具体流程 3.说一下几种join,都怎么用以及自己常用什么 4.常见窗口函数,怎么用 因为非科班问了下边的 5.数据结构怎么样 6.操作系统基础,网络基础 7.为什么选大数据 反问 问的很基础感觉kp
-
 无忧数仓实习
无忧数仓实习面试时给的SQL题 1.有个无忧达人开的店铺,每个顾客访问任何一个店铺的任何一个商品时,都会产生一条访问日志 访问日志存储的表名为vsit,访客用户id为user id,被访问的店铺名称为shop。请统计每个店铺访问次数top3的访客信息。输出店铺名、访客id、访问次数。 2.现在只有两个字段工号,姓名,请你在原有数据不动的情况下,标记这个人是否出现重名情况,并把其余重名的人的工号(要去除自己的工