《lambda》专题
-
AWS:如何将数据从AWS Lambda发送到现场应用程序
我试图将AWS Lambda函数中的数据(可能大于10MB)发送到正在写入内部数据存储的内部CDAP应用程序。
-
AWS lambda到Firehose的转换:Python
-
AWS Lambda函数从kinesis流中无限读取记录
我有一个kinesis流,有一个碎片和一个用Python编写的lambda函数。我添加了kinesis流作为批量大小为5的事件源。我在kinesis中添加了数百条记录,lambda函数得到了正确的调用和执行。但是对于最后3条记录,lambda函数被无限地调用,即使函数返回是成功的。
-
Kinesis流到AWS lambda
我目前正在使用DynamoDB流,并期待着转向Kinesis流,因为我想控制我喜欢从流中处理的记录数量。 我一直在读有关Kinesis流和lambda的文章。有很多关于Kinesis流和EC2的多用户和KCL等的文章。 null
-
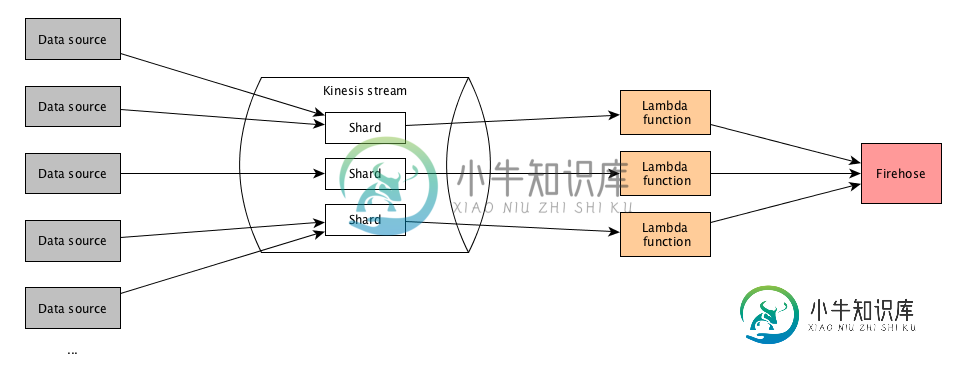 使用Kinesis中的分区键来保证使用相同键的记录由相同的记录处理器处理(lambda)
使用Kinesis中的分区键来保证使用相同键的记录由相同的记录处理器处理(lambda)我正在使用AWS kinesis和lambda开发一个实时数据管道,我试图弄清楚如何确保来自相同数据生产者的记录由相同的碎片处理,并最终由相同的lambda函数实例处理。 我的方法是使用分区键来确保来自相同生产者的记录由相同的碎片处理。但是,我不能让同一碎片中的记录由同一lambda函数实例处理。 基本设置如下: null 分区键用于在流中按碎片对数据进行分组。Kinesis Data Strea
-
NodeJS脚本在本地工作,但不能在lambda的处理程序中工作
代码: 知道是什么导致了这个问题吗。可能与VPC或安全组有关?并给出了思考和建议。谢了。
-
如何在AWS Lambda运行时上查看实际的java依赖项/库
我有自定义逻辑,它定义了杰克逊应该如何在AWS lambda函数中序列化和反序列化域对象。AWS lambda函数使用AWS lambda运行时java 11(amazon-corretto-11)部署在AWS上。在本地测试时,序列化工作正常,但在AWS中则不然。 如何找出AWS lambda运行时中实际使用的java依赖项和依赖项的版本? 在我的具体案例中,我想了解的是杰克逊依赖的版本。
-
无法将purrr样式的lambda函数与`select()`(dplyr 1.0.0开发程序)一起使用
(我目前使用的是dplyr 1.0.0的开发版本) 在dplyr 1.1.0中,应该取代所有限定范围的谓词。但是,当我尝试使用的purrr样式函数时,就像使用一样,它会出现错误,我找到的唯一解决办法是使用替换的。 由reprex包(v0.3.0)在2020-04-17创建
-
为什么我必须在提供lambda参数时捕获异常?
考虑以下示例: 问题来了:上例中的lambda参数是稍后将在“display()”方法内执行的对象。将参数传递给“display()”时,它显然不会执行。 为什么它被编译器拒绝?我认为只有在实际调用lambda时,用try... catch来包围它是很合理的。
-
为什么我不能在Java8 lambda表达式中抛出异常?[复制]
我升级到Java 8,并试图用一个新的lamdba表达式替换通过映射的简单迭代。循环搜索空值,如果找到,则抛出异常。旧的Java 7代码如下所示: 我尝试将其转换为Java 8,如下所示: 有人能解释为什么这里不允许语句以及如何纠正这一点吗? Eclipse的快速修复建议在我看来不太对劲......它只是用块包围语句:
-
Java lambda交集两个列表并从结果中删除
我想对两个列表的交集使用Java lambda表达式,然后使用lambda表达式从列表中删除。 我想用lambda表达式,我怎么做?
-
在Clojure中有没有构造lambda函数?
我可能是错的,但是在rethinkdb驱动程序中,lambda不知怎么地被编译成ast语法,这些语法被转换成js并发送到数据库。我相信我需要以某种方式显式地创建一个lambda。http://www.retinkdb.com/blog/lambda-functions/那么这个问题是如何在Clojure中将lambda实现为一个名为“lambda”的函数的呢?只显示如何使用函数,而不是lambda
-
lambda内的Java 8 lambda不能从外部lambda修改变量
假设我有一个和一个。我想将每个变压器应用于列表中的每个字符串。 使用Java8 lambdas,我可以这样做: 但我想做更像这样的事情,但这会导致编译时错误: 我刚刚开始玩lambdas,所以也许我只是没有正确的语法。
-
Java为什么使用花括号时需要在lambda中进行异常处理[重复]
我有两个函数引发异常: 若在lambda表达式中使用花括号组合这些函数调用,则需要try/catch来处理异常。 然而,若我合并到for循环中,就可以了。 我认为由于创建了新的闭包(使用括号),所以需要try/catch,但在for循环中,它不需要。我只使用for循环解决了这个问题,但我想知道为什么会发生这种情况。
-
为什么Lambda不理解抛出的方法签名?[副本]
在下面的代码中,我在方法签名中编写了throws,但在Lambda for write中,编译器给出了一个错误。为什么? 编译器错误:未处理的异常:java.io.IOException