
使用Kinesis中的分区键来保证使用相同键的记录由相同的记录处理器处理(lambda)

我正在使用AWS kinesis和lambda开发一个实时数据管道,我试图弄清楚如何确保来自相同数据生产者的记录由相同的碎片处理,并最终由相同的lambda函数实例处理。
我的方法是使用分区键来确保来自相同生产者的记录由相同的碎片处理。但是,我不能让同一碎片中的记录由同一lambda函数实例处理。
基本设置如下:
-
null
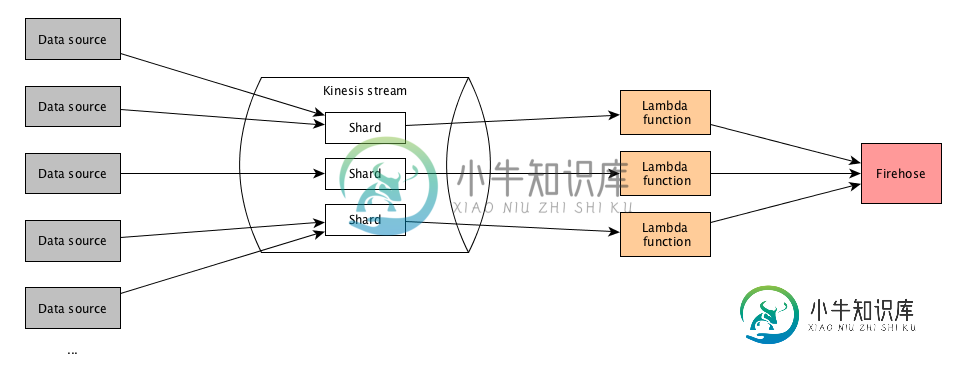
分区键用于在流中按碎片对数据进行分组。Kinesis Data Streams服务使用与每个数据记录相关联的分区键将属于流的数据记录分离成多个碎片,以确定给定数据记录属于哪个碎片。分区键是Unicode字符串,最大长度限制为256字节。MD5哈希函数用于将分区键映射到128位整数值,并将相关的数据记录映射到碎片。当应用程序将数据放入流中时,必须指定分区键。
来源:https://docs.aws.amazon.com/streams/latest/dev/key-concepts.html#partition-key
这管用。因此具有相同分区键的记录由相同的碎片处理。但是,它们由不同的lambda函数实例处理。因此,每个碎片调用一个lambda函数实例,但它不仅处理来自一个碎片的记录,而且处理来自多个碎片的记录。这里似乎没有记录如何移交给lambda的模式。
下面是我的测试设置:我将一系列测试数据发送到流中,并在lambda函数中打印记录。这是三个函数实例的输出(检查每行末尾的分区键。每个键应该只出现在三个日志中的一个,而不是多个日志中):
Lambda实例1:
{'type': 'c', 'source': 100, 'id': 200, 'data': 'ce', 'partitionKey': '100'}
{'type': 'c', 'source': 100, 'id': 200, 'data': 'ce', 'partitionKey': '100'}
{'type': 'c', 'source': 103, 'id': 207, 'data': 'ce2', 'partitionKey': '103'}
{'type': 'c', 'source': 100, 'id': 200, 'data': 'ce', 'partitionKey': '100'}
{'type': 'c', 'source': 103, 'id': 207, 'data': 'ce2', 'partitionKey': '103'}
{'type': 'c', 'source': 101, 'id': 204, 'data': 'ce4', 'partitionKey': '101'}
{'type': 'c', 'source': 101, 'id': 205, 'data': 'ce5', 'partitionKey': '101'}
{'type': 'c', 'source': 101, 'id': 205, 'data': 'ce5', 'partitionKey': '101'}
Lambda实例2:
{'type': 'c', 'source': 101, 'id': 201, 'data': 'ce1', 'partitionKey': '101'}
{'type': 'c', 'source': 102, 'id': 206, 'data': 'ce1', 'partitionKey': '102'}
{'type': 'c', 'source': 101, 'id': 202, 'data': 'ce2', 'partitionKey': '101'}
{'type': 'c', 'source': 102, 'id': 206, 'data': 'ce1', 'partitionKey': '102'}
{'type': 'c', 'source': 101, 'id': 203, 'data': 'ce3', 'partitionKey': '101'}
{'type': 'c', 'source': 100, 'id': 200, 'data': 'ce', 'partitionKey': '100'}
{'type': 'c', 'source': 100, 'id': 200, 'data': 'ce', 'partitionKey': '100'}
{'type': 'c', 'source': 101, 'id': 201, 'data': 'ce1', 'partitionKey': '101'}
{'type': 'c', 'source': 101, 'id': 202, 'data': 'ce2', 'partitionKey': '101'}
{'type': 'c', 'source': 101, 'id': 203, 'data': 'ce3', 'partitionKey': '101'}
{'type': 'c', 'source': 101, 'id': 204, 'data': 'ce4', 'partitionKey': '101'}
{'type': 'c', 'source': 101, 'id': 204, 'data': 'ce4', 'partitionKey': '101'}
{'type': 'c', 'source': 101, 'id': 204, 'data': 'ce4', 'partitionKey': '101'}
{'type': 'c', 'source': 101, 'id': 204, 'data': 'ce4', 'partitionKey': '101'}
{'type': 'c', 'source': 101, 'id': 204, 'data': 'ce4', 'partitionKey': '101'}
processed_records = []
for r in records:
processed_records.append({
'PartitionKey': str(r['source']),
'Data': json.dumps(r),
})
kinesis.put_records(
StreamName=stream,
Records=processed_records,
)
-
null
共有1个答案

为什么要关心哪个Lambda实例处理碎片?反正Lambda实例没有状态,所以哪个实例读取哪个碎片并不重要。更重要的是,在任何时候,Lambda实例都只能读取一个碎片。在调用完成后,它可以从另一个碎片中读取。
-
我正在spring Boot中使用异步任务执行器对数百万条记录的数据进行分区,块大小为1000条,网格大小为10条。为了从数据库中获取特定的分区数据,我正在使用项目读取器的before步骤中的StepExecution获取分区数据的开始和结束索引(来自Partitioner类)。 例如:项目阅读器 Item Reader遍历testData列表并将testData值返回给writer TestDa
-
问题内容: 我试图将数据库表保存在班级 学生* 的 ListArray 中。 * 在while循环中,当我尝试将数据打印为 它打印完美。但是当我尝试将其打印为 它打印从数据库读取的最后一条记录。记录数相同。如果在数据库表中保存了4行,那么显示的记录也将是4次。 我使用LIST的方式有问题吗?谢谢! 问题答案: 更改为 您是,因为您创建 了。您必须在数据库中添加等于。因此,创建如下。 使用
-
我实际上是使用处理来检查从键盘输入的值并采取行动。现在的问题是,我想使用键盘上的数字“1”来根据IF语句执行两个不同的操作,但第二个条件似乎不起作用。请帮助我仔细阅读这段代码,因为我不知道我可能在哪里出错了
-
我需要在多个线程中使用来自Kafka分区的记录,每个线程上有唯一的记录要处理。我有以下代码,我不知道是什么错误 结果 应为:
-
根据AWS文件: worker使用Java ExecutorService任务调用记录处理器方法。如果任务失败,工作进程将保留对记录处理器正在处理的碎片的控制。工作进程启动一个新的记录处理器任务来处理该碎片。有关详细信息,请参阅阅读节流。 根据AWS文件的另一页: Kinesis客户端库(KCL)依靠您的进程记录代码来处理处理数据记录时出现的任何异常。从进程记录抛出的任何异常都被KCL吸收。为了避
-
我还希望com.mypack的级别“trace”与“info”的行为方式相同。到目前为止,我还没有取得任何成功。我需要像这样的东西 感谢你的帮助。