《lambda》专题
-
使用Lambda设置DynamoDB触发器
我正在尝试使用DynamoDB流和AWS Lambda创建DynamoDB触发器。我做了很多研究,但在Java 8中找不到任何读取和处理DynamoDB流事件的方法。我对这两种技术都是新手,所以不知道如何使用它。 本质上,我想做的是每当在表A中创建记录时,都在表B中创建一条记录。 你们谁能给我指出一个在Java中处理这个用例的代码或帖子吗? 谢谢:)
-
如何通过AWS Lambda索引Amazon Elasticsearch服务中的Dynamodb流数据?
我一步一步地遵循本教程,但当我到达“测试结果”步骤时,我在索引时间中看不到我的表名,因为示例中显示了“所有产品”。 这意味着我的dynamodb表在我的Amazon ES域中没有索引。 我设置了所有授权并配置了lambda,就像在示例中一样。 现在我只是不知道如何在AWS ES中触发我的Dynamodb流。
-
如何在Lambda函数中检索DynamoDB的碎片ID?
AWS DynamoDB触发器使我们能够捕获DynamoDB表中的所有更改。Lambda将每个Lambda函数分配给DynamoDB流的碎片。 我想在Lambda函数中检索碎片ID,以在某些数据处理任务中保持一致性,但我找不到获得它的方法。有人做到了吗?
-
AWS DynamoDB:如何订购使用DynamoDB Stream触发的Lambda?
我已经启用了我的表的DynamoDB Streaming,并且有两个lambda与之关联。每当DynamoDB表中发生变化时,这两个触发器都通过Dynamo触发器。 问题:两个Lambda相应地将数据插入到两个RDS表中。就像λ1插入表1和λ2插入表2一样。表1主键是表2中的外键。 因此,每当两个lambda都触发lambda two首先完成执行时,它会显示外键约束错误,因为lambda two试
-
AWS Lambda和Dynamo db:如何通过多个参数过滤扫描结果?
我是AWS和Dynamo的新手。我正在使用React.js前端和AWS(Gateway API、Lambda、Dynamo)后端进行我的项目。这是我的应用位置: https://www.alphaux.com 单击“获取提示”后,我收到服务器响应。如果我单击一个关键字-这些关键字将添加到请求的GET参数列表中,如:topic=blah 以下是我的问题的详细信息: 在我的Lambda中:…const
-
Dynamodb batchWrite在具有Async的Lambda中不工作
BatchWrit在Laqmbda中不适用于异步。代码将插入一条记录,但它不能。但是,当我删除异步时,它可以工作。 结果如下。没有错误。 你们有同样的行为吗?
-
DynamoDB未触发lambda
我正在试验Dynamo db和lambda,并且在以下流程中遇到问题: Lambda A由put to S3事件触发。它获取对象(一个音频文件),计算其持续时间,并在dynamoDB中为每30秒的段写入一条记录。 Lambda B由DynamoDB触发,从S3下载文件并对Dynamo行中定义的30秒记录进行操作。 我的问题是,当我运行这个流时,函数A通过函数B写入Dynamo所需的所有行 似乎没有
-
我什么时候应该使用DynamoDB触发器来调用另一个Lambda?
我目前有一个AWS Lambda函数正在更新DynamoDB表,我需要另一个Lambda函数,该函数需要在数据更新后运行。在这种情况下,使用DynamoDB触发器而不是使用第一个Lambda调用第二个Lambda有什么好处吗? 看起来编程调用会让我更好地控制何时调用Lambda(即。我可以在调用之前等待几个更新发生),并且从DynamoDB Stream读取会花钱,而简单地调用Lambda不会。
-
AWS有没有办法在dynamodb流达到批量大小限制或时间限制时触发Lambda?
我试图创建一个流,使AWS DynamoDB流仅在达到批量大小限制或达到指定时间间隔(即批量大小为100,时间间隔为5分钟)时触发Lambda函数。假设只有50个记录更新,距离上次调用只有4分钟。如果记录更新未达到100,我希望在下一分钟触发lambda。如果在下一分钟之前达到100,则触发lambda并重置时钟。 我试着只使用批量大小限制。这不起作用。如果我做两次更新,它会调用lambda两次。
-
如何从AWS Lambda内部访问Dynamodb?
如何从AWS Lambda函数中读取Dynamodb记录? 我正试图通过以下方式调用get_item: 但是,当我通过Lambda测试工具运行测试时,它失败并出现错误: 尽管文档说get_item应该返回包含字典的对象,但它实际上返回: 为什么没有提供项目?如何从Dynamo检索记录?
-
目标仅在通过AWS CLI调用Lambda时有效
我有一个hello world测试Lambda,配置为: 触发器:API网关 目的地:亚马逊SQS。一个队列表示成功,另一个队列表示失败 当我通过CLI调用Lambda时,消息会按预期排队到成功队列中: 但是,当我通过API网关调用Lambda时,没有消息排队到任何一个目标队列。我启用了Lambda代理集成。Cloudwatch指标确认调用成功(调用计数上升,错误计数不上升)。以下从我的Lambd
-
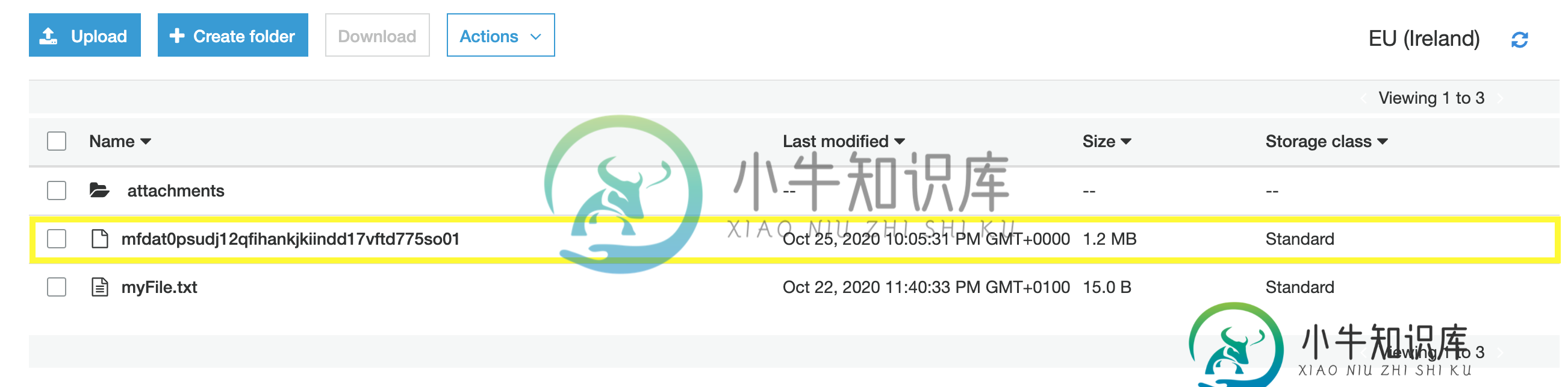 AWS Lambda put_对象函数未将文件发送到目标s3存储桶
AWS Lambda put_对象函数未将文件发送到目标s3存储桶我调用一个Lambda函数,将一个.csv文件从电子邮件发送到我在所述函数中指定的目标s3存储桶。当传入的s3 bucket接收到电子邮件时,调用由事件类型:ObjectCreatedByPut触发。 我从CloudWatch日志中看到该函数确实按预期调用,但从未将文件发送到目标s3存储桶。 这是显示键mfdat0psudj12qfihankjkiindd17vftd775so01存在的传入文件夹
-
从Nodejs中的Dynamodb Steam调用AWS Lambda
当我尝试从AWS控制台运行lambda函数时,代码工作正常。由于我想仅在添加了新的Dynamo DB记录时运行特定代码,因此我想从dymanoDB流插入事件中运行lambda函数。我尝试了以下代码,似乎lambda没有调用。 serverless.yml中的权限 dynamoDB流代码 我将非常感谢你的指导。
-
单个DynamoDB流上的多个AWS Lambda函数
我有一个Lambda函数,将多个DynamoDB流配置为事件源,这是更大管道的一部分。在进行检查时,我在一个下游组件中发现了一些缺失的数据。我想编写一个更简单的Lambda函数,将其配置为前面提到的DynamoDB流之一的事件源。这将导致我的一个DynamoDB流有两个Lambda函数从中读取。我想知道这样可以吗?这两个Lamdba函数是否都能保证接收流中的所有记录,是否有任何需要注意的资源(读/
-
AWS Lambda是否严格按顺序处理DynamoDB流事件?
我正在编写一个Lambda函数,用于处理DynamoDB流中的项。 我认为Lambda背后的部分观点是,如果我有一个大的事件突发,它将启动足够多的实例来同时通过它们,而不是通过单个实例顺序地提供它们。只要两个事件具有不同的键,我就可以不按顺序处理它们。 然而,我刚刚阅读了关于了解重试行为的这一页,上面说: 对于基于流的事件源(Amazon Kinesis Data Streams和DynamoDB