《流处理》专题
-
对另一个流进行流过滤并计数
我需要基于另一个流过滤一个流,并获取所有匹配条目的计数。 我已经尝试了以下和各种其他组合,但它没有按预期工作。 这个想法是: < li >对于从0到256的每个数字(流1) < li >查看该号码是否出现在另一个列表中(流2 ),如果出现的话 < li >计算出现次数除以流2中的元素总数(18)。 < li >如果没有出现,请收集0。 这基本上是根据流 2 中的出现次数查找流 1 中数字的频率。
-
将流分成具有N个元素的子流
在Java中,我们能否以某种方式将流分成不超过N个元素的子流?例如 按两个流拆分的解决方案仅对2个流是正确的,对于N个流也是如此,这将是非常丑陋和只写的。
-
模拟输入流,输入流阅读器和BufferedReader
我有以下代码: 我只想模拟这些行,并在,因为我将有多个测试用例,具体取决于行(文件为空,行为空,我只得到一行,我得到几行,等等)。 注意:我使用库访问FTP服务器上的文件,因此方法将作为返回类型,而具有。 我正在使用junit 4.12和mockito 3.1.0 提前感谢!
-
8.5 重载流插入与流读取运算符
C++ 的流读取运算>>和流插入运算符<<可用来输入输出标准类型的数据。这两个运算符是 C++ 编译器在类库中提供的,可以处理包括类C语言中的char*字符串和指针在内的每一种内部数据类型。也可以重载运两个运算符以输入输出用户自定义类型的数据。图 8.3 中的程序演示了重载的流读取运算符和流插入运算符,它们用来处理用户自定义的电话号码类 PhoneNumber 的数据。程序假定输入的电话号码是正确
-
春云流手工偏移管理
我是否可以按以下方式使用Spring Cloud Steam实现手动Kafka偏移管理: 每当我的使用者处理消息时,它都会将其偏移量提交到DB中。不喜欢Kafka 每当我的使用者重新启动时,它就从数据库中读取上次处理的偏移量,查找该偏移量并开始处理下一条消息。
-
Kafka溪流基本原理解释
null
-
Apache flume twitter代理不流数据
我试图将twitter提要流到hdfs,然后使用Hive。但是第一部分,流数据和加载到hdfs不起作用,并给出空指针异常。 这是我尝试过的。 4.我将flume-sources-1.0-snapshot.jar添加到/user/lib/flume/lib。 5.启动Hadoop并执行以下操作 6.我在/user/lib/flume中运行以下内容
-
流量管理 - Istio Ingress控制器
此任务将演示如何通过配置Istio将服务发布到service mesh集群外部。在Kubernetes环境中,Kubernetes Ingress Resources 允许用户指定某个服务是否要公开到集群外部。然而,Ingress Resource规范非常精简,只允许用户设置主机,路径,以及后端服务。下面是Istio ingress已知的局限: Istio支持不使用annotation的标准Kub
-
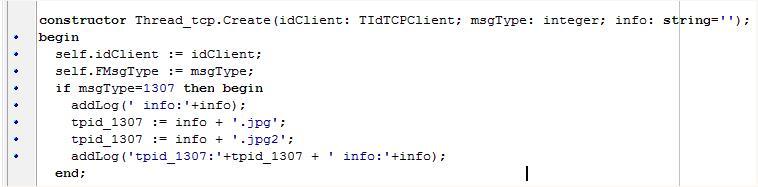 delphi 字符串处理中的怪异现象与处理方式
delphi 字符串处理中的怪异现象与处理方式本文向大家介绍delphi 字符串处理中的怪异现象与处理方式,包括了delphi 字符串处理中的怪异现象与处理方式的使用技巧和注意事项,需要的朋友参考一下 1, 怪异现象:字符串相加操作不正常! 以上代码,明显输出字符串应含有后缀“.jpg”,但实际输出却不含后缀(如下),字符串加法操作似乎不起作用了! 采用showMessage进行输出,看看结果如何? 结果仍是不显示字符串后缀,但可以看到字符串
-
 批处理闪退、运行中断等问题的处理方法
批处理闪退、运行中断等问题的处理方法本文向大家介绍批处理闪退、运行中断等问题的处理方法,包括了批处理闪退、运行中断等问题的处理方法的使用技巧和注意事项,需要的朋友参考一下 因为我只会一些批处理代码,所以我的“局域网共享一键修复”等软件就都做成了批处理程序(后缀名为.bat)供大家使用。有些网友反馈:右键运行批处理,会一闪而过。或者,运行后共享修复也不成功。下面我整理汇总了一些最常见的情况及其原因,供大家参考。 一、闪退 1、不要随便
-
NodeJS批处理多处理池(或多线程)中的子进程
我知道子进程是进程,而不是线程。我使用了错误的语义,因为大多数人在谈到“多线程”时都知道您的意图。所以我会把它保留在标题中。 想象一下这样一个场景:使用一个自定义函数或模块,您连续有多个类似和复杂的事情要做。使用所有可用的核心/线程(例如8/16)非常有意义,这就是的目的。 理想情况下,您需要多个同时工作的人员,并向一个控制器发送/从一个控制器发送/回调消息。 node cpool、fork po
-
Spring批处理-在读卡器和处理器之间传递值
我有一个要求,我需要从xls(其中存在一个名为netCreditAmount的列)中读取值并将值保存在数据库中。要求是从所有行中添加netCreditAmount的值,然后在数据库中仅为xls中的第一行设置此总和,其余行插入相应的netCreditAmounts。我应该如何在Spring Batch中进行实施。普通的阅读器、处理器和写入器工作正常,但我应该在哪里插入这个实现?谢谢!
-
Spring批处理分区-所有线程处理相同的记录
我正在spring Boot中使用异步任务执行器对数百万条记录的数据进行分区,块大小为1000条,网格大小为10条。为了从数据库中获取特定的分区数据,我正在使用项目读取器的before步骤中的StepExecution获取分区数据的开始和结束索引(来自Partitioner类)。 例如:项目阅读器 Item Reader遍历testData列表并将testData值返回给writer TestDa
-
在批处理模式下如何处理反序列化异常
如何在批处理模式的情况下处理反序列化异常? 我正在使用Spring boot-2.3.8版本的Spring kafka。 尝试过此选项: 但它抛出了一个异常:由java引起。lang.IllegalStateException:错误处理程序必须是ErrorHandler,而不是org。springframework。Kafka。听众。请参阅OcuCurrentBatchErrorHandler 以
-
Spring批处理链式复合项目处理器和编写器
我必须像这样配置批处理作业流。 XML文件阅读器- 我的定制处理器是这样的 这是一个好的方法吗?我看到了一些CompositeProcess、CompositeWriter的例子,但没有一个适合我的案例。 提前谢谢。