《流处理》专题
-
Apache flume twitter代理不流数据
我试图将twitter提要流到hdfs,然后使用Hive。但是第一部分,流数据和加载到hdfs不起作用,并给出空指针异常。 这是我尝试过的。 4.我将flume-sources-1.0-snapshot.jar添加到/user/lib/flume/lib。 5.启动Hadoop并执行以下操作 6.我在/user/lib/flume中运行以下内容
-
流量管理 - Istio Ingress控制器
此任务将演示如何通过配置Istio将服务发布到service mesh集群外部。在Kubernetes环境中,Kubernetes Ingress Resources 允许用户指定某个服务是否要公开到集群外部。然而,Ingress Resource规范非常精简,只允许用户设置主机,路径,以及后端服务。下面是Istio ingress已知的局限: Istio支持不使用annotation的标准Kub
-
直接流入BigQuery与通过Google发布/订阅数据流流入BigQuery的利弊
我们有一个托管在Google Kubernetes引擎上的NodeJS API,我们想开始将事件记录到BigQuery中。 我可以看到三种不同的方法: 使用API中的节点BigQuery SDK将每个事件直接插入BigQuery(如此处“流式插入示例”下所述):https://cloud.google.com/bigquery/streaming-data-into-bigquery或此处:htt
-
关闭Java 8流
问题内容: 如果我们使用Java 8 Stream,例如何时关闭此流? 作为下一个示例,我们关闭流是不是一个好习惯? 问题答案: 通常根本不需要关闭流。您只需要关闭使用IO资源的流。 从Stream文档中: 流具有方法和实现,但是实际上几乎所有流实例在使用后都不需要关闭。通常,只有源是IO通道的流(例如由返回的)才需要关闭。大多数流都由集合,数组或生成函数支持,而无需特殊的资源管理。(如果流确实需
-
流口水验证
问题内容: 这是我的流口水验证问题的第二部分。第一部分已经回答,我的代码中已经实现了建议的解决方案。 这是我的java类结构 好的,我的问题是,如果FinanceItemName为“土地或建筑物”,并且该用户的地址符合以下条件,则我需要验证FinanceDetails实例的itemValue, AddressStatus ==当前 AddressType ==物理 AddressUseType =
-
Xamarin.Forms XAML的NavigationPage流
本文向大家介绍Xamarin.Forms XAML的NavigationPage流,包括了Xamarin.Forms XAML的NavigationPage流的使用技巧和注意事项,需要的朋友参考一下 示例 App.xaml.cs文件(默认为App.xaml文件,因此已跳过) FirstPage.xaml文件 在某些情况下,您需要不在当前导航中而是在全局导航中打开新页面。例如,如果您的当前页面包含底
-
Node.js调试流程
问题内容: 我想像rails一样调试node.js。我尝试了几种方法: Webstorm调试–在这种情况下,每次更改代码后,我都需要单击“重新运行调试” 使用chrome远程调试器的Nodemon –在这种情况下,每次由nodemon重新加载代码后,我都需要重新连接到调试器 pry.js –在这里我需要输入“ eval(pry.it)” –并没有使其更简单的选项,例如“ debug”或pry()
-
Kafka流的特点?
本文向大家介绍Kafka流的特点?相关面试题,主要包含被问及Kafka流的特点?时的应答技巧和注意事项,需要的朋友参考一下 答:Kafka流的一些最佳功能是 Kafka Streams具有高度可扩展性和容错性。 Kafka部署到容器,VM,裸机,云。 我们可以说,Kafka流对于小型,中型和大型用例同样可行。 此外,它完全与Kafka安全集成。 编写标准Java应用程序。 完全一次处理语义。 而且
-
Java 8流短路
问题内容: 阅读了有关Java 8的一些知识后,我进入了这篇博客文章,解释了有关流及其还原的一些知识,以及何时有可能使还原短路。在底部,它指出: 请注意,在或的情况下,我们只需要与谓词匹配的第一个值(尽管不能保证返回第一个)。但是,如果流没有排序,则我们的行为应类似于。的操作,并且可能不会短路,因为在所有它的流可能需要评估所有的值,以确定操作者是否是或。因此,使用它们的无限流可能不会终止。 我知道
-
Java 8流-超时?
问题内容: 我想遍历一个巨大的数组并执行一组复杂的指令,这需要很长时间。但是,如果超过30秒,我希望它放弃。 例如 我想避免只在通话中说出是否满足特定条件。 问题答案: 与实际执行操作相比,如果在这种情况下迭代流或数组便宜,那么不仅仅使用谓词和筛选时间是否结束。 问题是您是否需要知道哪些元素已被处理。通过以上内容,您之后必须检查特定元素是否发生了副作用。
-
 数据流测试
数据流测试数据流测试用于分析程序中的数据流。它是收集有关变量如何在程序中流动数据的过程。它试图获得过程中每个特定点的特定信息。 数据流测试是一组测试策略,用于检查程序的控制流程,以便根据事件的顺序探索变量的顺序。它主要关注分配给变量的值和通过集中在两个点上使用这些值的点的点,可以测试数据流。 数据流测试使用控制流图来检测可能中断数据流的不合逻辑的事物。由于以下原因,在值和变量之间的关联时检测到数据流中的异常
-
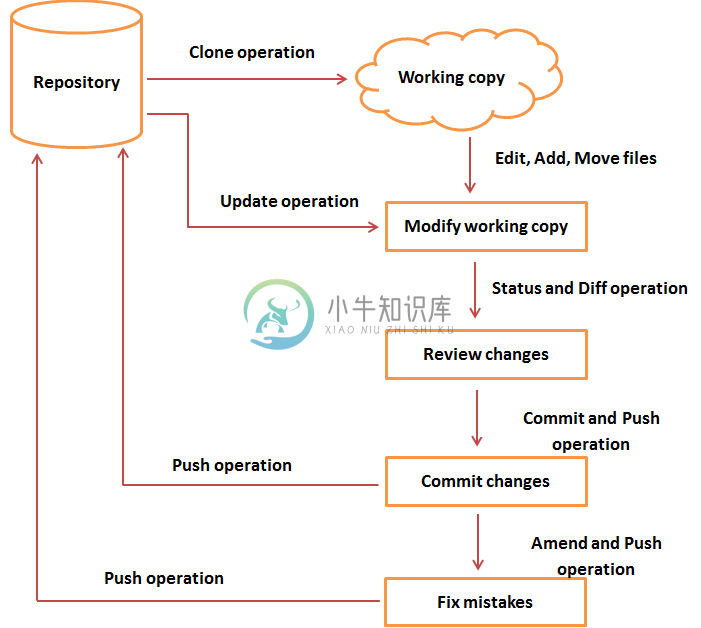 Git工作流程
Git工作流程在本章中,我们将讨论Git的生命周期。 在后面的章节中,我们将介绍每个操作的 Git 命令。 一般工作流程如下: 将Git的一个存储库克隆为工作副本。 可以通过添加/编辑文件修改工作副本。 如有必要,还可以通过让其他开发人员一起来更改/更新工作副本。 在提交之前查看更改。 提交更改:如果一切正常,那么将您的更改推送到存储库。 提交后,如果意识到某些错误并修改错误后,则将最后一个正确的修改提交并将推
-
 6.7 Verilog 流水线
6.7 Verilog 流水线主要内容:实例,实例,实例,实例,实例,实例关键词:流水线,乘法器 硬件描述语言的一个突出优点就是指令执行的并行性。多条语句能够在相同时钟周期内并行处理多个信号数据。 但是当数据串行输入时,指令执行的并行性并不能体现出其优势。而且很多时候有些计算并不能在一个或两个时钟周期内执行完毕,如果每次输入的串行数据都需要等待上一次计算执行完毕后才能开启下一次的计算,那效率是相当低的。流水线就是解决多周期下串行数据计算效率低的问题。 流水线 流水线的基
-
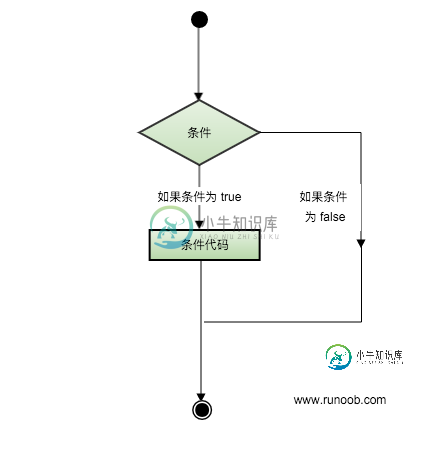 Lua 流程控制
Lua 流程控制主要内容:实例Lua 编程语言流程控制语句通过程序设定一个或多个条件语句来设定。在条件为 true 时执行指定程序代码,在条件为 false 时执行其他指定代码。 以下是典型的流程控制流程图: 控制结构的条件表达式结果可以是任何值,Lua认为false和nil为假,true和非nil为真。 要注意的是Lua中 0 为 true: 实例 --[ 0 为 true ] if ( 0 ) then print
-
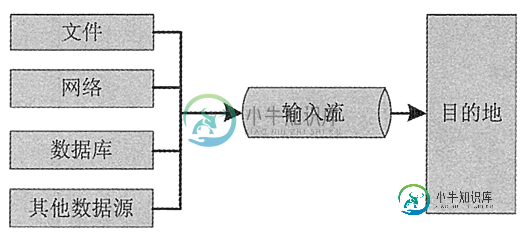 Java流的概念
Java流的概念主要内容:什么是输入/输出流,输入流,输出流在 Java 中所有数据都是使用流读写的。 流是一组有序的数据序列,将数据从一个地方带到另一个地方。 根据数据流向的不同,可以分为输入(Input)流和输出(Output)流两种。 在学习输入和输出流之前,我们要明白为什么应用程序需要输入和输出流。例如,我们平时用的 Office 软件,对于 Word、Excel 和 PPT 文件,我们需要打开文件并读取这些文本,和编辑输入一些文本,这都需要利用输