《流处理》专题
-
使用外部目标进行Spring云数据流错误处理
我一直在阅读spring cloud stream文档,特别是错误处理: 关于留档所说的,当您想要捕获错误时,您可能需要使用。这没有关联的外部目标。 @StreamListener注释的使用专门用于定义连接内部通道和外部目标的绑定。鉴于目标特定的错误通道没有相关的外部目标,这种通道是Spring集成(SI)的特权。这意味着必须使用SI处理程序注释之一(即@ServiceActivator、@Tra
-
如何在所需数量的结果后退出Java流处理?
我有以下代码,它使用Stream API来查找卡路里超过300的集合中的前3个元素的名称: 在传统的基于迭代器的命令式方法中,我可以保留结果的计数,因此一旦我得到所需数量的元素,就可以退出迭代循环。但是上面的代码似乎贯穿了集合的整个长度。我如何停止这样做,并在得到我需要的3个元素后停止?
-
一般处理流程 - 监控正在请求执行的命令
6.1.3 监控正在请求执行的命令 在cli下执行monitor,生产环境慎用。
-
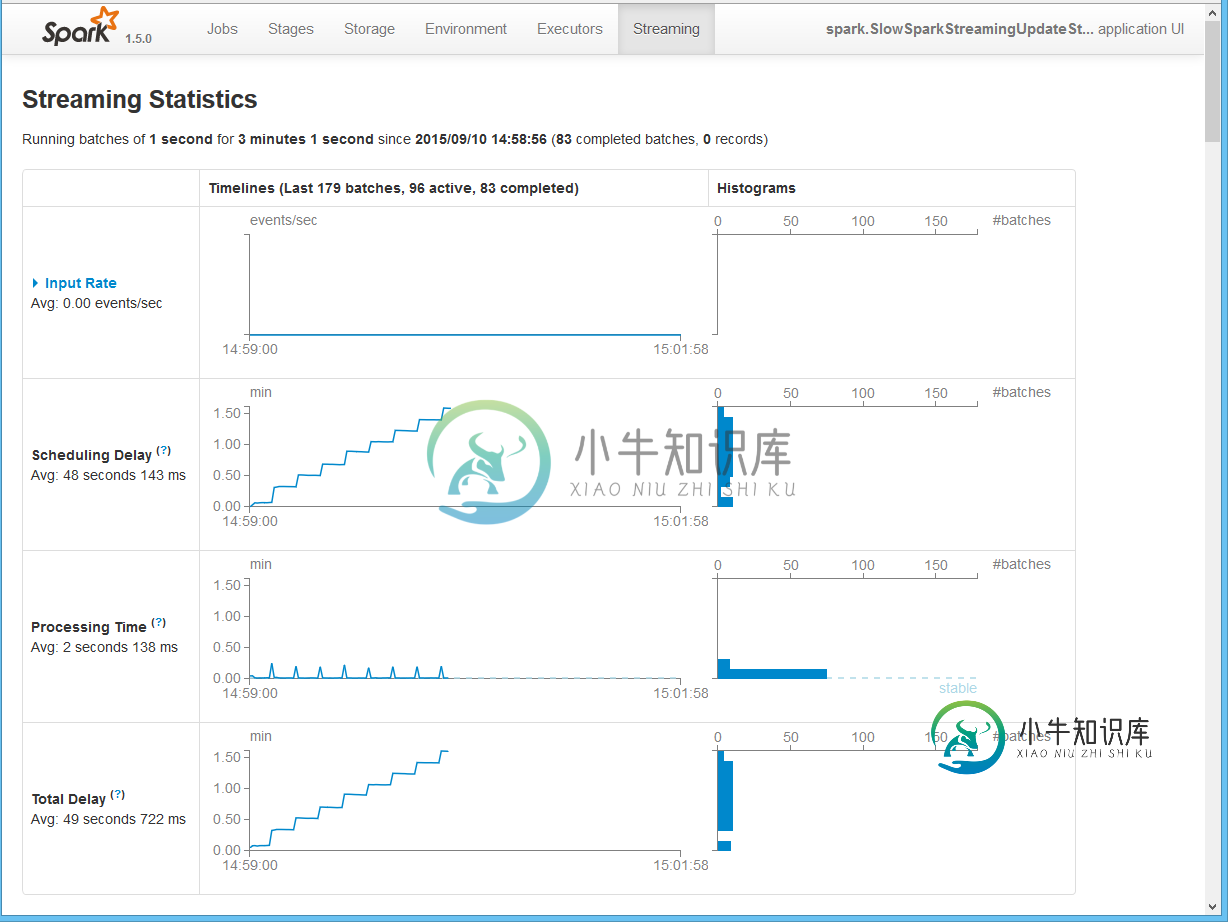 火花流:为什么处理几MB的用户状态的内部处理成本如此之高?
火花流:为什么处理几MB的用户状态的内部处理成本如此之高?根据我们的实验,我们发现当状态变成超过一百万个对象时,有状态的Spark Streaming内部处理成本会花费大量时间。因此,延迟会受到影响,因为我们必须增加批处理间隔以避免不稳定的行为(处理时间 它与我们应用程序的细节无关,因为它可以通过下面的代码复制。 Spark内部处理/基础架构成本到底是什么,需要这么多时间来处理用户状态?除了简单地增加批处理间隔之外,还有什么选项可以减少流转时长吗? 我们
-
Python-多重处理:如何在多个流程之间共享指令?
问题内容: 一个程序,该程序创建在可连接队列上工作的多个进程,并且最终可能会操纵全局字典来存储结果。(因此,每个子进程都可以用来存储其结果,并查看其他子进程正在产生什么结果) 如果我在子进程中打印字典,则可以看到对它进行的修改(即在上)。但是在主流程加入之后,如果我打印D,那就是空洞的字典! 我了解这是同步/锁定问题。有人可以告诉我这里发生了什么,如何同步对的访问? 问题答案: 普遍的答案涉及使用
-
火花流-4核和16核的处理时间相同。为什么?
场景:我正在用spark streaming做一些测试。大约有100条记录的文件每25秒就出现一次。 问题:在程序中使用local[*]时,4核pc的处理时间平均为23秒。当我将相同的应用部署到16核服务器时,我期望处理时间有所改善。然而,我发现它在16个内核中也花费了同样的时间(我还检查了ubuntu中的cpu使用率,cpu得到了充分利用)。所有配置默认由spark提供。 问题:处理时间不应该随
-
如何在流数据的时间戳基础上处理FLINK窗口?
我有一些问题。 基于类中的时间戳,我想做一个逻辑,排除在1分钟内输入N次或更多次的数据。 UserData类有一个时间戳变量。 起初我试着用一个翻滚的窗户。 但是,滚动窗口的时间计算是基于固定时间的,因此无论UserData类的时间戳如何,它都不适合。 如何处理流上窗口UserData类的时间戳基? 谢谢。 附加信息 我使用这样的代码。 我试了一些测试。150个样本数据。每个数据的时间戳增加1秒。
-
解读PHP的Yii框架中请求与响应的处理流程
本文向大家介绍解读PHP的Yii框架中请求与响应的处理流程,包括了解读PHP的Yii框架中请求与响应的处理流程的使用技巧和注意事项,需要的朋友参考一下 一、请求(Requests) 请求: 一个应用的请求是用 yii\web\Request 对象来表示的,该对象提供了诸如 请求参数(译者注:通常是GET参数或者POST参数)、HTTP头、cookies等信息。 默认情况下,对于一个给定的请求,你可
-
Javaweb应用使用限流处理大量的并发请求详解
本文向大家介绍Javaweb应用使用限流处理大量的并发请求详解,包括了Javaweb应用使用限流处理大量的并发请求详解的使用技巧和注意事项,需要的朋友参考一下 在web应用中,同一时间有大量的客户端请求同时发送到服务器,例如抢购、秒杀等。这个时候如何避免将大量的请求同时发送到业务系统。 第一种方法:在容器中配置最大请求数,如果大于改请求数,则客户端阻塞。该方法有效的阻止了大量的请求同时访问业务系统
-
导致作业退出状态的Spring批处理条件流失败
null 鉴于以下MVE: 执行代码时,“Continue”流运行良好,但“Completed”流总是以失败的作业状态退出。 如何使作业在状态已完成的情况下完成?换句话说,我在流的编码上做错了什么?
-
如何处理spark结构化流媒体中的小文件问题?
我的项目中有一个场景,我正在使用spark-sql-2.4.1版本阅读Kafka主题消息。我能够使用结构化流媒体处理一天。一旦收到数据并进行处理后,我需要将数据保存到hdfs存储中的各个拼花文件中。 我能够存储和读取拼花文件,我保持了15秒到1分钟的触发时间。这些文件的大小非常小,因此会产生许多文件。 这些拼花地板文件需要稍后通过配置单元查询读取。 那么1)该策略在生产环境中有效吗?还是会导致以后
-
如何在Python中处理流到Firebase信令服务器的视频
我在Javascript中这样做(并显示在我的HTML中): 然而,我如何下载/流式传输这个视频,并对视频进行块式处理,理想情况下是在Python脚本中处理?
-
Kafka-具有批处理数据的事件与流之间的差异
附加了一批数据的事件和偶尔发送数据的Kafka流有什么根本区别?它们可以互换使用吗?什么时候该用第一个,什么时候该用后一个?你能提供一些简单的用例吗? 注意:在这个问题的评论中有一些信息,但我想要一个更全面的答案。
-
Flink SQL客户端如何区分批处理模式和流模式?
众所周知,Flink有两个核心API(数据流/数据集),但当我使用Flink Sql客户端提交作业时,我不需要选择流或批处理模式。所以,Flink SQL客户机是如何决定使用批处理模式和流模式的。我在官方文件中没有找到答案。所以,我想知道Flink SQL客户端如何区分批处理模式和流模式?
-
spring控制器如何处理应用程序/八位组流请求?
我用以下方法编写了一个spring控制器来处理回调http请求, 但是我得到错误:由处理程序执行导致的已解决异常:org.springframework.web.HttpMediatypeNotSupportedException:不支持内容类型'application/octet-stream' 我不能更改回调http请求,因为它们来自其他第三方服务,我如何更改控制器以正确获取请求参数?