
火花流:为什么处理几MB的用户状态的内部处理成本如此之高?

根据我们的实验,我们发现当状态变成超过一百万个对象时,有状态的Spark Streaming内部处理成本会花费大量时间。因此,延迟会受到影响,因为我们必须增加批处理间隔以避免不稳定的行为(处理时间
它与我们应用程序的细节无关,因为它可以通过下面的代码复制。
Spark内部处理/基础架构成本到底是什么,需要这么多时间来处理用户状态?除了简单地增加批处理间隔之外,还有什么选项可以减少流转时长吗?
我们计划广泛使用状态:在几个节点中的每一个节点上至少 100MB 左右,将所有数据保存在内存中,并且每小时只转储一次。
增加批处理间隔有帮助,但我们希望保持批处理间隔最小。
原因可能不是状态占用的空间,而是大对象图,因为当我们将列表更改为大基元数组时,问题就消失了。
只是一个猜测:它可能与Spark内部使用的org.apache.spark.util.SizeEstimator有关,因为它不时在分析时出现。
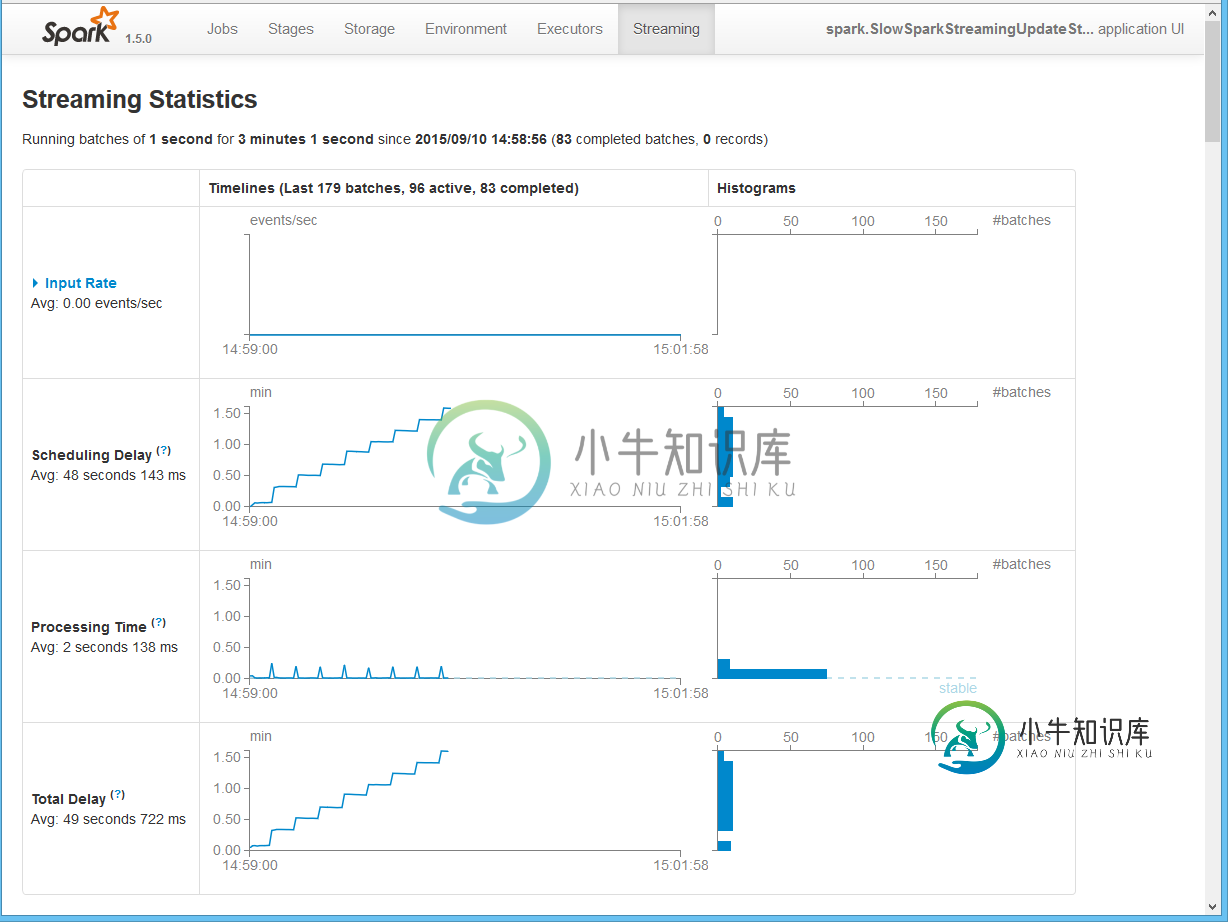
这是一个简单的演示,可以在现代iCore7上重现上面的图片:
- 小于15 MB的状态
- 根本没有流输入
- 最快可能(虚拟)'updateStateByKey'函数
- 批处理间隔1秒
- 检查点(Spark需要,必须有)到本地磁盘
- 在本地和纱线上进行了测试
代码:
package spark;
import org.apache.commons.lang3.RandomStringUtils;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.util.SizeEstimator;
import scala.Tuple2;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
public class SlowSparkStreamingUpdateStateDemo {
// Very simple state model
static class State implements Serializable {
final List<String> data;
State(List<String> data) {
this.data = data;
}
}
public static void main(String[] args) {
SparkConf conf = new SparkConf()
// Tried KryoSerializer, but it does not seem to help much
//.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
.setAppName(SlowSparkStreamingUpdateStateDemo.class.getName());
JavaStreamingContext javaStreamingContext = new JavaStreamingContext(conf, Durations.seconds(1));
javaStreamingContext.checkpoint("checkpoint"); // a must (if you have stateful operation)
List<Tuple2<String, State>> initialRddGeneratedData = prepareInitialRddData();
System.out.println("Estimated size, bytes: " + SizeEstimator.estimate(initialRddGeneratedData));
JavaPairRDD<String, State> initialRdd = javaStreamingContext.sparkContext().parallelizePairs(initialRddGeneratedData);
JavaPairDStream<String, State> stream = javaStreamingContext
.textFileStream(".") // fake: effectively, no input at all
.mapToPair(input -> (Tuple2<String, State>) null) // fake to get JavaPairDStream
.updateStateByKey(
(inputs, maybeState) -> maybeState, // simplest possible dummy function
new HashPartitioner(javaStreamingContext.sparkContext().defaultParallelism()),
initialRdd); // set generated state
stream.foreachRDD(rdd -> { // simplest possible action (required by Spark)
System.out.println("Is empty: " + rdd.isEmpty());
return null;
});
javaStreamingContext.start();
javaStreamingContext.awaitTermination();
}
private static List<Tuple2<String, State>> prepareInitialRddData() {
// 'stateCount' tuples with value = list of size 'dataListSize' of strings of length 'elementDataSize'
int stateCount = 1000;
int dataListSize = 200;
int elementDataSize = 10;
List<Tuple2<String, State>> initialRddInput = new ArrayList<>(stateCount);
for (int stateIdx = 0; stateIdx < stateCount; stateIdx++) {
List<String> stateData = new ArrayList<>(dataListSize);
for (int dataIdx = 0; dataIdx < dataListSize; dataIdx++) {
stateData.add(RandomStringUtils.randomAlphanumeric(elementDataSize));
}
initialRddInput.add(new Tuple2<>("state" + stateIdx, new State(stateData)));
}
return initialRddInput;
}
}
共有1个答案

-
我有一个用例,我必须以FIFO方式处理事件。这些是从机器生成的事件。每台机器每30秒生成一个事件。对于特定的机器,我们需要根据FIFO FASION对事件进行处理。 我们每天需要处理大约2.4亿个事件。对于如此大的规模,我们需要使用Kafka+火花流 从Kafka文档中,我了解到我们可以使用消息的关键字段将消息路由到特定的主题分区。这确保我可以使用机器id作为密钥,并确保来自特定机器的所有消息都进
-
当前设置:Spark流作业处理timeseries数据的Kafka主题。大约每秒就有不同传感器的新数据进来。另外,批处理间隔为1秒。通过,有状态数据被计算为一个新流。一旦这个有状态的数据穿过一个treshold,就会生成一个关于Kafka主题的事件。当该值后来降至treshhold以下时,再次触发该主题的事件。 问题:我该如何避免这种情况?最好不要切换框架。在我看来,我正在寻找一个真正的流式(一个
-
我有一个xlsx文件,大小为90MB,不是很大。 首先,我使用XSSFWorkbook来阅读它,我得到了一个OutOfMemory错误。好吧,我改为使用XSSF和SAX(事件API)来读取。 当我尝试编写xlsx文件时,文档 https://poi.apache.org/components/spreadsheet/how-to.html#sxssf 告诉“SXSSF刷新临时文件(每工作表一个临时
-
场景:我正在用spark streaming做一些测试。大约有100条记录的文件每25秒就出现一次。 问题:在程序中使用local[*]时,4核pc的处理时间平均为23秒。当我将相同的应用部署到16核服务器时,我期望处理时间有所改善。然而,我发现它在16个内核中也花费了同样的时间(我还检查了ubuntu中的cpu使用率,cpu得到了充分利用)。所有配置默认由spark提供。 问题:处理时间不应该随
-
我正在处理UDF中的空值,该UDF在数据帧(源自配置单元表)上运行,该数据帧由浮点数结构组成: 数据帧()具有以下架构: 例如,我想计算x和y的总和。请注意,我不会在以下示例中“处理”空值,但我希望能够在我的udf中检查、或是否。 第一种方法: 如果<code>struct是否为空,因为在scala中<code>浮点不能为空。 第二种方法: 这种方法,我可以在我的udf中检查是否为空,但我可以检查
-
给定:客户列表(带供应商和代理字段)、字符串代理、字符串供应商。 目标:检查是否有客户支持给定的代理和给定的供应商。 我有一个流需要过滤两次(两个值)。如果在第一次过滤后流是空的,我需要检查它并抛出异常。如果它不是空的,我需要通过第二个过滤器处理它(然后再次检查它是否不是空的)。 如果可能的话,我想避免将流收集到列表中(我不能使用任何匹配或计数方法,因为它们是终端) 目前我的代码看起来像: 在这个