《grafana》专题
-
Grafana-如何整合XDB和CollectD中的指标
我们已经使用XDB设置了CollectD来收集度量。问题在于整合例如来自cpu1、cpu2和cpu3的指标。在collectd(至少是5.2版)中,可以启用“聚合”插件来完成我需要的任务。但我们使用的是Debian 7,而惊奇-collectd仅在5.1版中可用。 你们知道如何用grafana编写这样的正则表达式,这样我就不需要为每个cpu指定每个指标(下面它不起作用): 从“.cpu-{0-3}
-
Grafana/XDB:不同客户端记录的值之和
我正在录制一系列的memory_used,例如使用的几个客户端的InphxDB数据库的Inphexdb-java客户端。数据看起来像这样: 我可以使用grafana轻松地将内存使用情况按标记分组,但是我找不到一种方法来汇总所有客户端的总内存消耗。当使用avg(使用内存)或sum(使用内存)时,值非常大且波动。我认为这是因为同一客户机的值可能会根据报告的时间间隔(不完全相同)求和多次。 在这种情况下
-
可以grafana组由多个列时,工作时与入侵数据库
当我使用作为数据源,在图指标定义中,我发现如果我在和标签后添加一列,(如:latency_scope,类型),数据响应是正确的,但图例显示未定义,仪表板上没有日期显示。 原始查询是这样的,但是,它不起作用。"选择latency_scope,uri,和(sum_count)从"延迟",其中$timeFilter组按时间($间隔),latency_scope,uri填充(0)顺序asc" grafan
-
 根据Grafana中的变量值显示或隐藏查询结果
根据Grafana中的变量值显示或隐藏查询结果我试图根据仪表板变量值在图形面板上显示/隐藏查询。 动机 在同一个图形面板(用于显示多个主机)上,我有两个查询: 和: 其中是一个计数器。 第一个是一个通常的比率,它更适合显示趋势,另一个更复杂一些,但显示所有选择。当然,我想为图表制作一个面板,但也有一些开关,如趋势/选择来分析两者。我引入了一个带有自定义值的grafana dashboard变量,但我不明白如何使用它来隐藏或显示特定的查询。 此
-
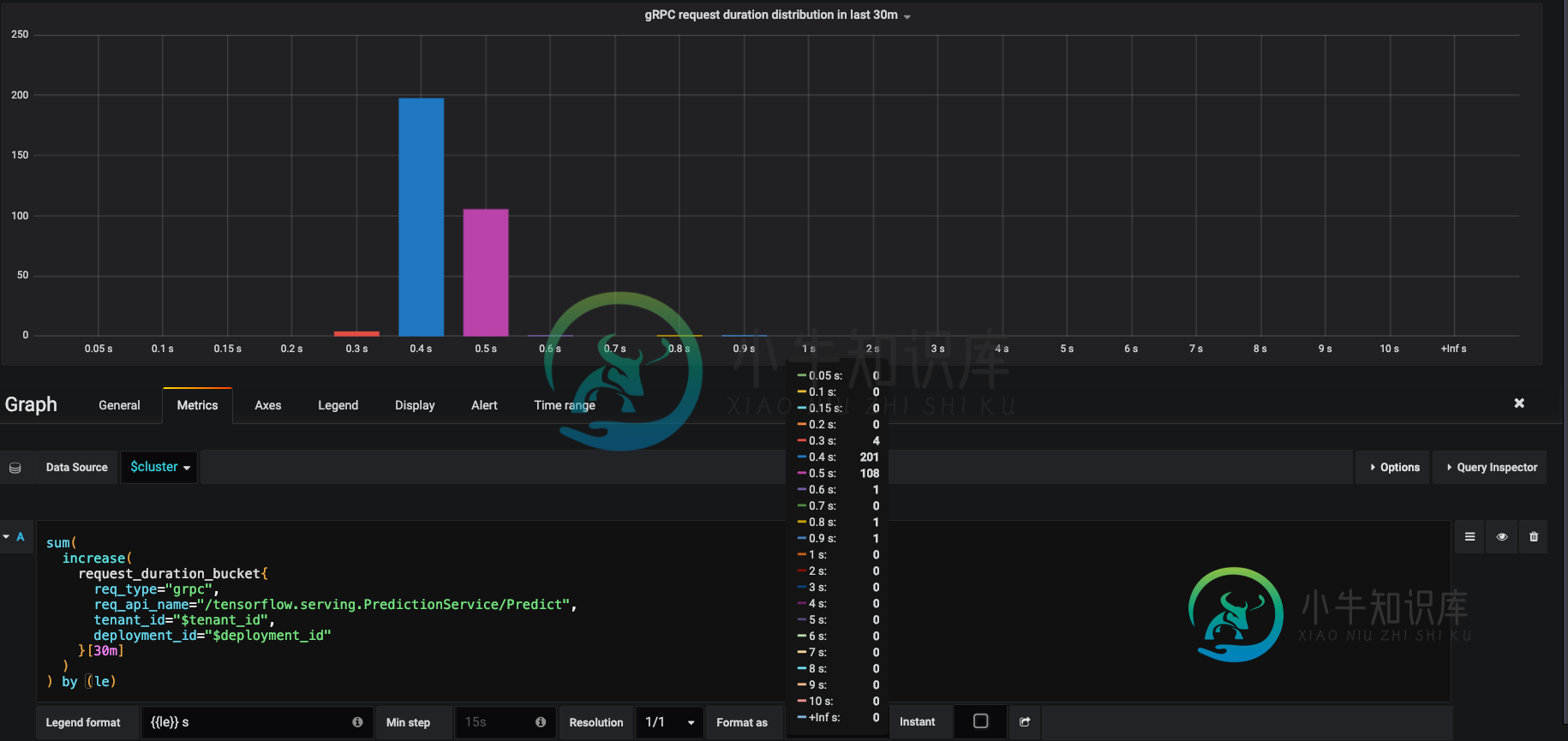 我应该如何解释这个grafana可视化普罗米修斯直方图桶热图?
我应该如何解释这个grafana可视化普罗米修斯直方图桶热图?我用grafana将普罗米修斯柱状图可视化为热图,下图显示了查询和结果图,我应该如何解释? 据我的攻击者说,在这段时间里我总共发送了300个请求,但当我把这些数字加在上面的图表上时,我永远无法得到确切的300, 而且看起来这些数字随着时间的推移而波动,我应该如何以有意义的方式解释这个图表? 如果我想让这些数字成为那个时间窗口中每个桶中的确切请求计数,我应该怎么做? 哦,对于模式,我选择了和的值。
-
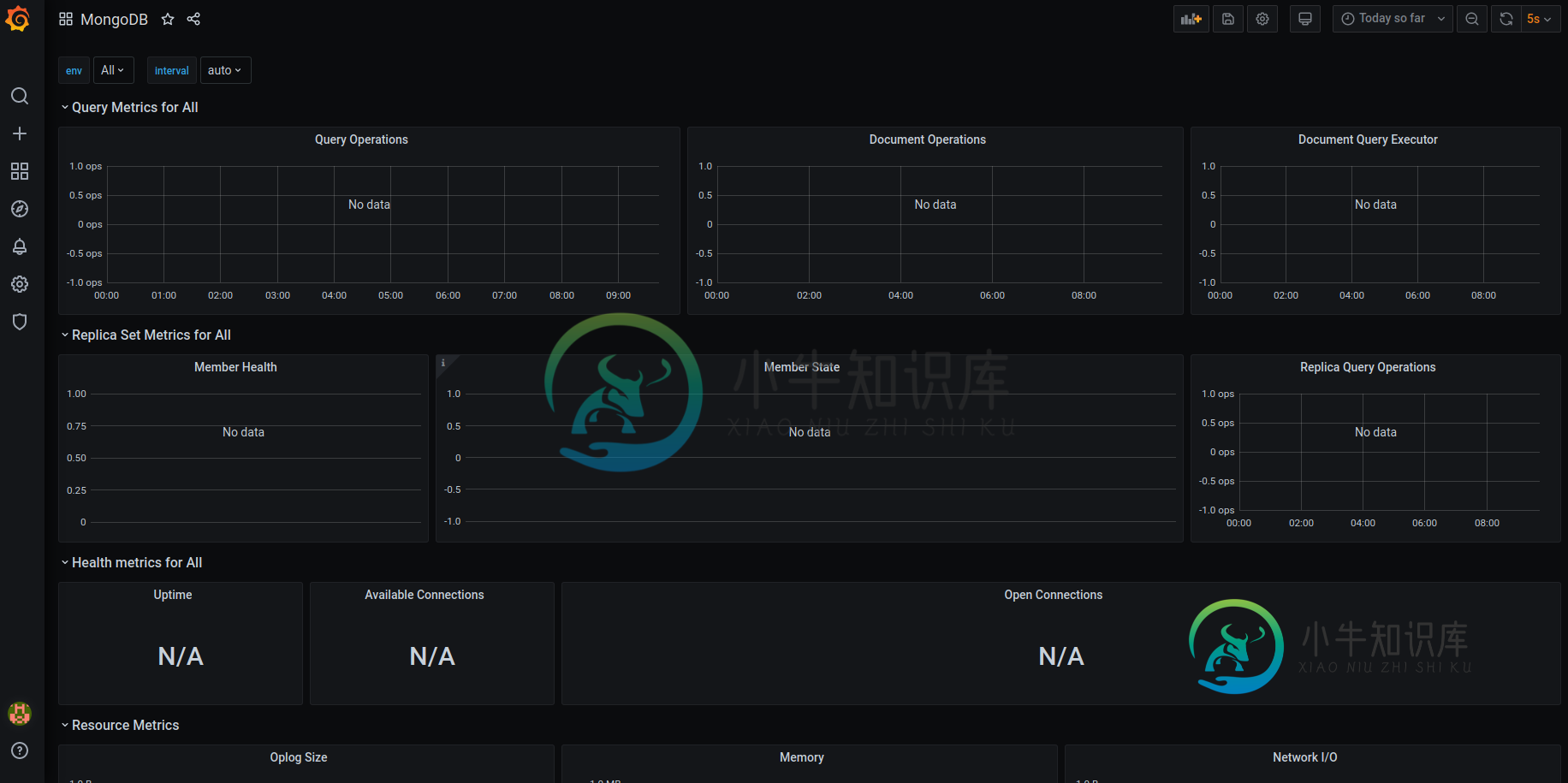 如何使用helm Bitnami/mongodb和kube-prometheus-stack设置mongodb grafana仪表板
如何使用helm Bitnami/mongodb和kube-prometheus-stack设置mongodb grafana仪表板我已经在我的k8s集群上安装了helm chart mongodb(https://github.com/bitnami/charts/tree/master/bitnami/mongodb)。 我还在我的k8s集群上安装了库贝-普罗米修斯-堆栈。(https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-p
-
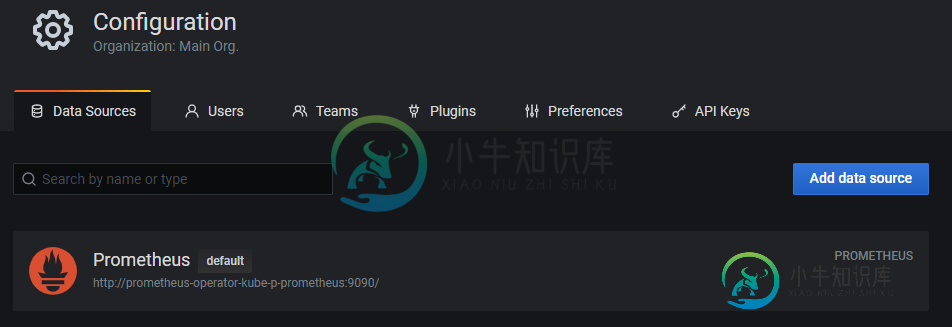 kube-prometheus-stack应用程序中的Grafana pod无法检测数据源的configmap
kube-prometheus-stack应用程序中的Grafana pod无法检测数据源的configmap我已经将kube-prometheus-stack(https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack)的一个实例安装到一个Rancher集群上,并使用自定义的values.yaml添加Grafana配置。 values.yaml的Grafana部分: 在安装之前,我还
-
在Grafana中创建自定义仪表板时出现问题(数据源是Prometheus)
我已经安装了普罗米修斯和格拉法纳来监视我的kubernetes集群,一切都很好。然后,我在Grafana中为我的应用程序创建了自定义仪表板。Prometheus中可用的度量如下,我在Grafana中添加了相同的度量: sum(irate(container_cpu_usage_seconds_total{namespace=“test”,pod_name=“my-app-65c7d6576b-5p
-
用度量的标号值作为grafana上的值
动机:我想呈现标签趋势图,而不是普罗米修斯格拉法纳的度量值。 我的用例是,我有一个简单的度量来表示Jenkins上的作业信息:在我的示例中,我运行ci-test,构建号为100,耗时10000 ms,结果是1,这意味着成功: 我想计算这份工作持续时间的趋势,并观察峰值。例如: 所表示的趋势持续时间将是[10000,10000,20000]或者在图形表示中类似于:我们可以在20000处观察到峰值--
-
Grafana-大计数器复位后的单统计
我们使用Grafana+Prometheus来监控我们的基础设施,最近我们添加了一些业务重点指标,我一直在跟踪的一个计数器上遇到问题。是会话时间计数器。基本上,每次会话结束时,我们都会增加用户在该会话中花费的时间。因此,如果一个用户使用该软件花费2M,计数器将增加120000毫秒。有几天,这种方法非常有效,但自从昨天我们在一个实例计数器和其他实例计数器之间出现了很大的差异,并且由于部分服务被重新启
-
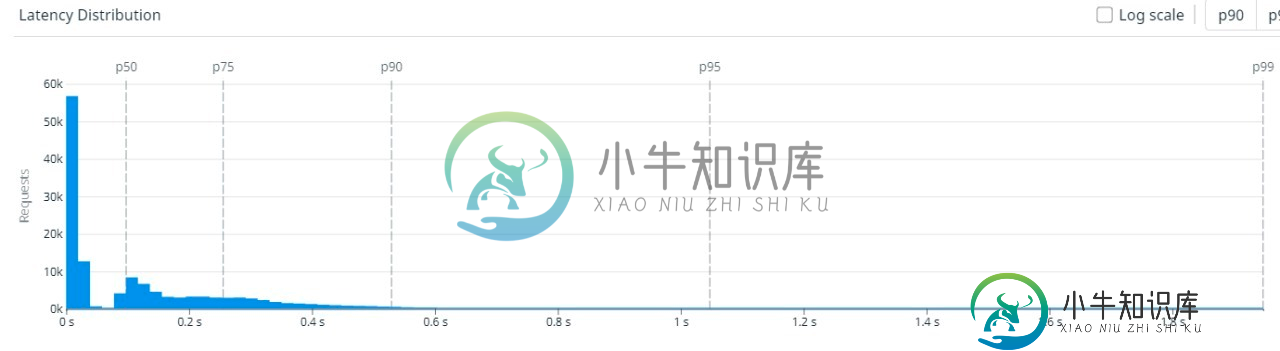 Prometheus Grafana创建延迟分布图
Prometheus Grafana创建延迟分布图如何基于普罗米修斯查询对Grafana进行时延分配?
-
如何使用Prometheus存储Grafana可视化的数据
在Python和函数的帮助下,我能够从URL中获取数据。数据包含一个实例列表,其中每个实例都有instance_id、状态等指标。 我的问题是,我有没有办法将这些指标上传到普罗米修斯?我查看了pushgateway功能,但不确定这是否是进行数据推送和存储的正确方法。 我目前向普罗米修斯推送数据的工作如下: 但是,我不确定我应该推动什么公制类型(仪表,摘要或其他东西?) 下面是我希望推送的实例数据示
-
ES在运维监控领域的其他玩法 - Grafana
Grafana是一个开源的指标量监测和可视化工具。常用于展示基础设施的时序数据和应用程序运行分析。Grafana的dashboard展示非常炫酷,绝对是运维提升逼格的一大利器。 官方在线的demo可以在这里找到: http://play.grafana.org/ grafana的套路基本上跟kibana差不多,都是根据查询条件设置聚合规则,在合适的图表上进行展示,多个图表共同组建成一个dashbo
-
监控篇 - Telegraf + InfluxDB + Grafana(下)
上一小节主要讲解了 Telegraf(StatsD) + InfluxDB + Grafana 的搭建和基本用法,并创建了请求量和响应时间这两种图表。本节讲解几个高级用法: 如何将 Grafana(监控)跟 ELK(日志)结合起来。 Grafana 监控报警。 脚本一键生成图表。 7.2.1 Grafana + ELK 在观察 Grafana 监控时,我们发现某个 api 接口的响应时间突然有一个
-
监控篇 - Telegraf + InfluxDB + Grafana(上)
本节将会讲解如何使用 Telegraf(StatsD) + InfluxDB + Grafana 搭建一套完整的监控系统。 7.1.1 Telegraf(StatsD) + InfluxDB + Grafana 简介 Telegraf 是一个使用 Go 语言开发的代理程序,可收集系统和服务或者其他来源(inputs)的数据,并将其写入 InfluxDB(outputs)数据库,支持多种 input