
我应该如何解释这个grafana可视化普罗米修斯直方图桶热图?

我用grafana将普罗米修斯柱状图可视化为热图,下图显示了查询和结果图,我应该如何解释?
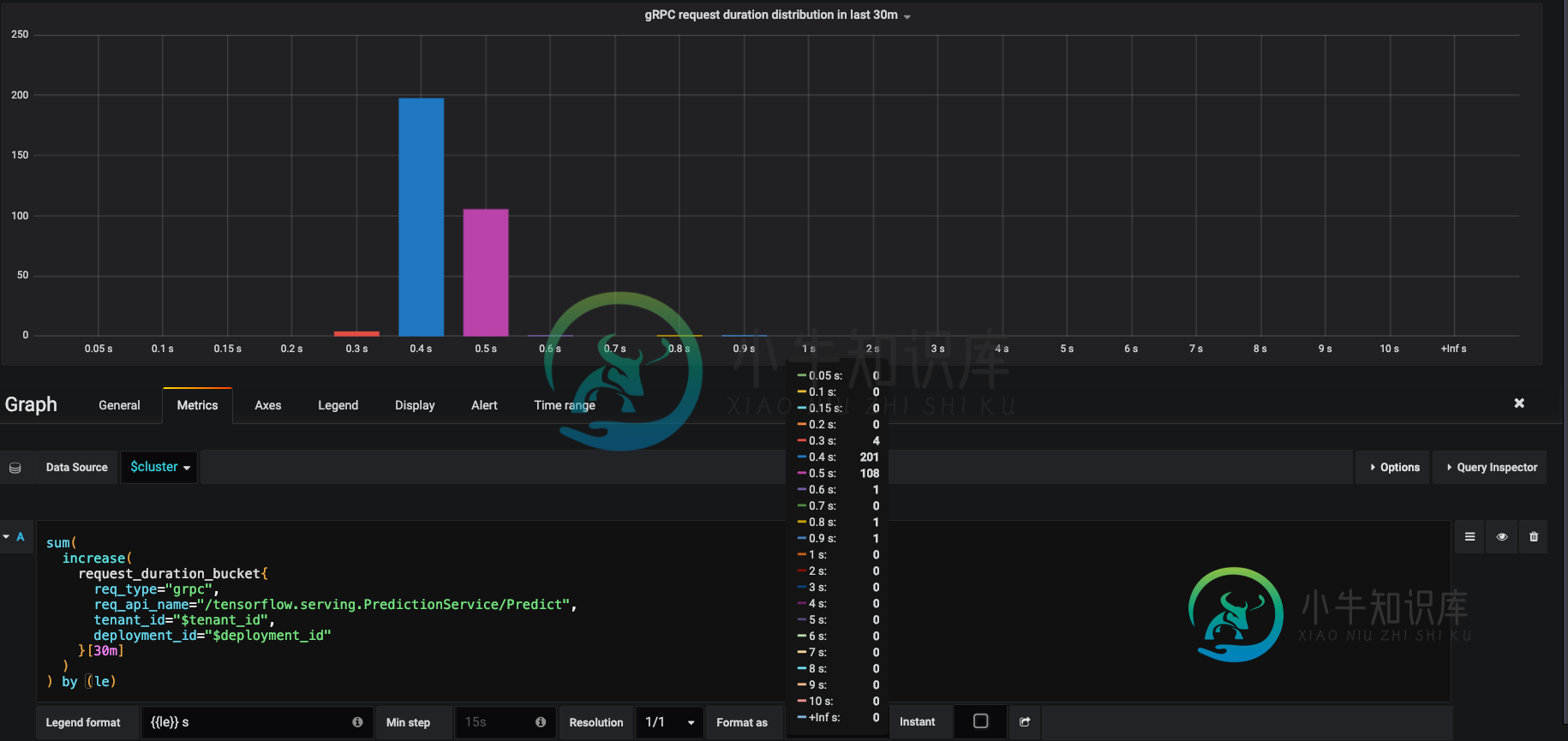
据我的攻击者说,在这段时间里我总共发送了300个请求,但当我把这些数字加在上面的图表上时,我永远无法得到确切的300,
而且看起来这些数字随着时间的推移而波动,我应该如何以有意义的方式解释这个图表?
如果我想让这些数字成为那个时间窗口中每个桶中的确切请求计数,我应该怎么做?
哦,对于X轴模式,我选择了Series和Current的值。
共有1个答案

你不能总是从普罗米修斯那里得到一个精确的增长率/价值,这是有原因的。其中之一是失败的刮取,即由于服务速度慢、普罗米修斯速度慢或网络问题,偶尔刮取会失败或超时。
另一个原因是收集的样本从来都不是完全分开的scrape_interval:总是会有几毫秒或几秒钟的延迟。所以(举一个极端的例子)如果你只有两个样本相隔63秒,你怎么能知道过去1分钟的精确增长呢?是两个价值观的区别吗?是那个差值调整到60秒(即/63*60)吗?
话虽如此,普罗米修斯通过只看严格在要求的时间范围内的样本,进一步把自己限制在一个角落里。请解释一下:一个理智的人会如何计算柜台在过去30分钟内的增长?他们可能会把计数器现在的值和30分钟前的值减去。即在PromQL术语中(在必要时调整计数器复位):
request_duration_bucket - request_duration_bucket offset 30m
相反,普罗米修斯所做的(假设scrape_间隔1m和理想的时间序列,采样间隔正好1m)基本上是这样的:
(request_duration_bucket - request_duration_bucket offset 29m) / 29 * 30
也就是说,增加时间超过29分钟,并将其外推到30分钟。由于自我强加的限制,与手头问题的性质无关。
请注意,这适用于平稳且持续增加的计数器。例如,如果你的计数器每分钟增加500,那么在29分钟内增加并外推到30是完全正确的。但对于跳跃和拟合增加的任何东西(这是大多数现实生活中的计数器),如果在实际采样的29分钟内发生,则会略微高估增加(精确到1/29),或者严重低估增加(如果在未包含在采样的1分钟内发生)。如果在覆盖较少样本的范围内计算速率/增加,则情况更糟。例如,如果您的范围平均只包括5个样本,则高估值将为20%,即1/(5-1),并且(每个)您的增加值将在5个样本中的1分钟内完全消失。
我发现解决这个限制的唯一方法是(再次假设1m的scrape_interval)对普罗米修斯的外推进行逆向工程:
increase(request_duration_bucket[31m]) / 31 * 30
但这需要你意识到你的scrape_间隔并进行调整,而且非常脆弱(如果你改变scrape_间隔你所有的精心调整都会失败)。
或者,如果您同意每次重新启动实例时的增量都降至零:
clamp_min(request_duration_bucket - request_duration_bucket offset 30m, 0)
实际上,我确实有一个普罗米修斯的补丁,用于添加实际上表现得更像您期望的那样(如上所述)的函数:https://github.com/prometheus/prometheus/issues/3806
-
我是格拉法纳和普罗米修斯的新手。我使用docker compose设置了prometheus、grafana、alertmanager、nodeexporter和cadvisor。yml来自本帖https://github.com/vegasbrianc/prometheus 从https://grafana.com/dashboards/893进口Grafana仪表板#893 但是仪表板不工作,
-
我将我的GKE API服务器升级到1.6,并正在将节点升级到1.6,但遇到了一个障碍... 我有一个prometheus服务器(版本1.5.2),运行在一个由Kubernetes部署管理的pod中,其中两个节点运行版本1.5.4Kubelet,一个新节点运行版本1.6。 但普罗米修斯仍然得到401。 更新:就像乔丹所说的kubernetes认证问题。在这里看到新的、更集中的问题;https://s
-
我可以通过默认和dns服务名从入口吊舱(以及所有其他)访问服务器: 图表创建的活动入口列表: 现役资源一览表: 提前感谢! Helm和Kubernetes的版本:Helm 3.0.3/Kubernetes 1.15.5(Mac的Docker,MacOS Catalina)
-
在我的应用程序中,我为每个国家的websocket ping时间设置了直方图,每个国家一个直方图。在Grafana中,我通过以下查询得到了几个我最感兴趣的国家的平均ping时间图 这非常有效。我得到了每个国家的图表。现在我想把所有其他国家的平均值加在同一张图表上。 这是失败的。当我在Prometheus控制台的Prometheus查询中尝试该查询时,我得到一个值NaN。如果我接受相同的查询并删除a
-
我用格拉法纳来展示普罗米修斯的度量。 但是当我重启普罗米修斯服务器时,grafana将不会绘制之前刮掉的数据。 如何让格拉法纳从普罗米修斯那里收集所有的数据?
-
我的各种docker容器导出prometheus度量,但是我们的prometheus安装只需要从一个endpoint提取所有度量。不幸的是,这是无法改变的。因此,我需要在一个点上聚合所有度量,从普罗米修斯安装可以刮取度量。 此外,如果这个程序或脚本能够提供关于如何处理由不同endpoint导出的相同度量的额外逻辑,那就太好了。例如,如果我只是将不同的度量站点连接在一起,Prometheus在解释度