
Grafana Phlare 是一个用于聚合持续分析 (Continuous Profiling) 数据的开源项目,它可以和 Grafana 完全集成,与其他可观察信号相关联。
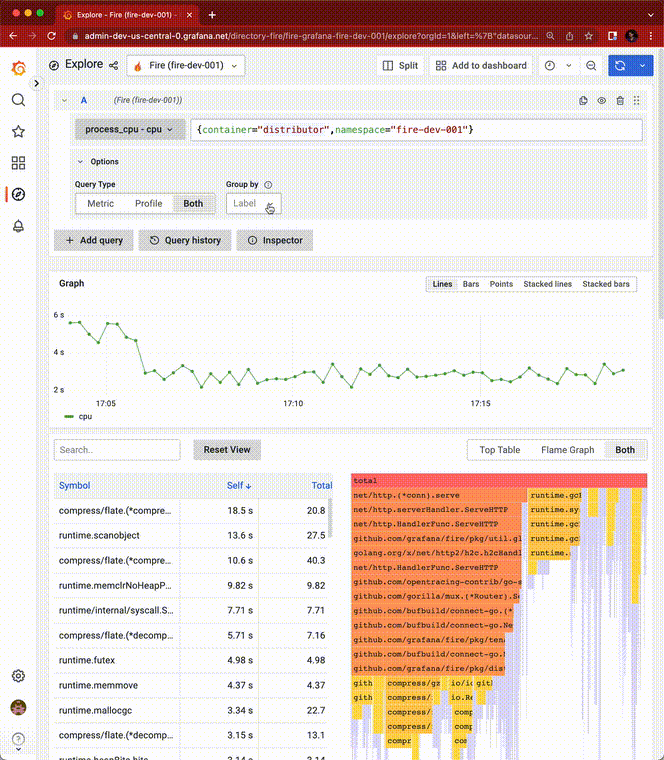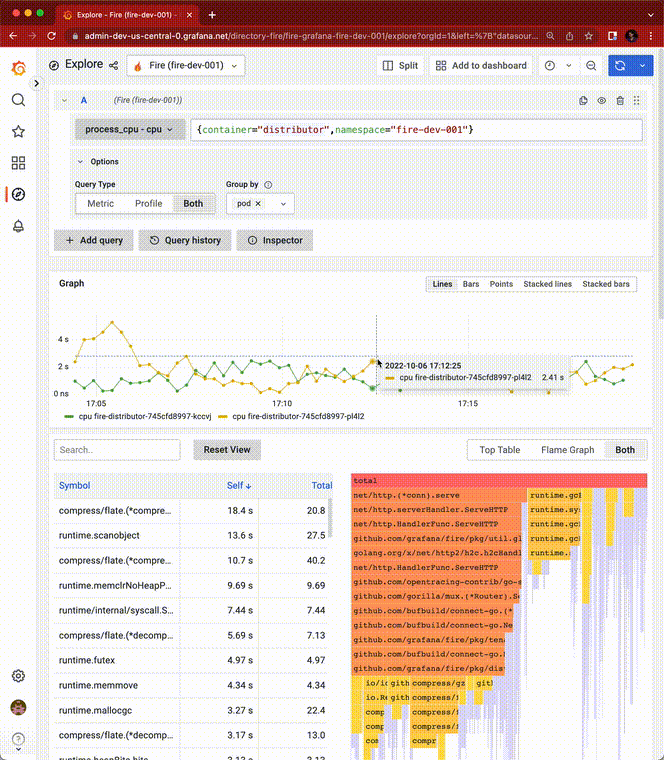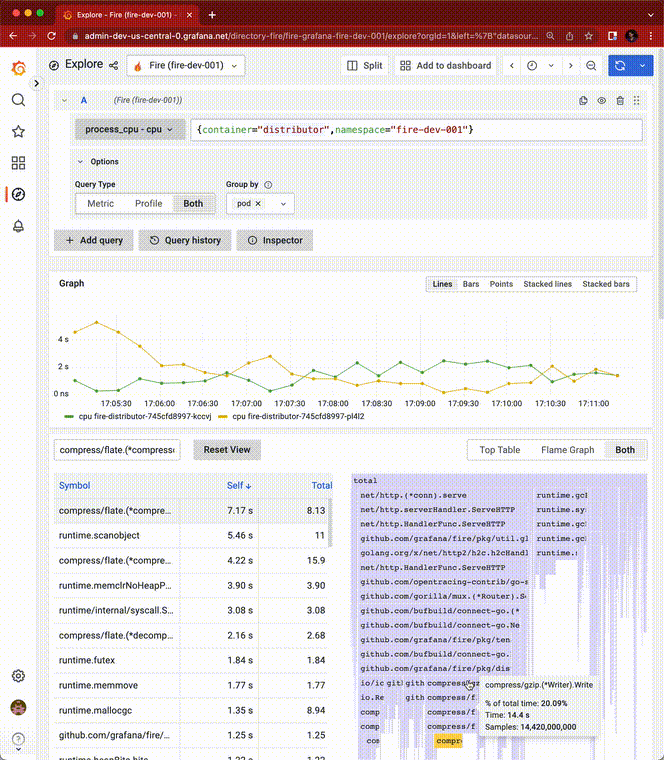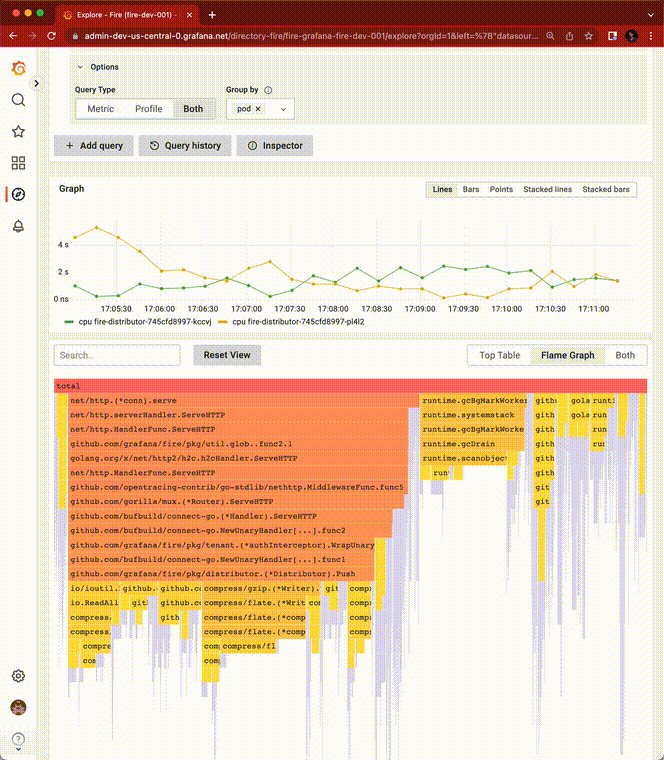
Phlare 核心功能
- 易于安装:使用其单片模式,只需一个二进制文件即可启动并运行 Grafana Phlare,无需其他依赖项。在 Kubernetes 上,单个 helm chart 允许以不同的模式进行部署。
- 水平可扩展性: 支持在多台机器上运行 Grafana Phlare,开发者可以轻松扩展数据库以处理工作负载生成的分析量。
- 高可用性: Grafana Phlare 复制传入的配置文件,确保在机器发生故障时不会丢失数据。这意味着可以在不中断配置文件获取和分析的情况下推出。
- 价格低廉、耐用的配置文件存储: Grafana Phlare 使用对象存储进行长期数据存储,使其能够利用这种无处不在、经济高效、高耐用性的技术。它兼容多种对象存储实现,包括 AWS S3、Google Cloud 存储、Azure Blob 存储、OpenStack Swift,以及任何与 S3 兼容的对象存储。
- 原生多租户: Grafana Phlare 的多租户架构使用户能够将数据和查询与独立的团队或业务部门隔离开来,从而使这些组织可以共享同一个数据库。
Phlare 运行流程
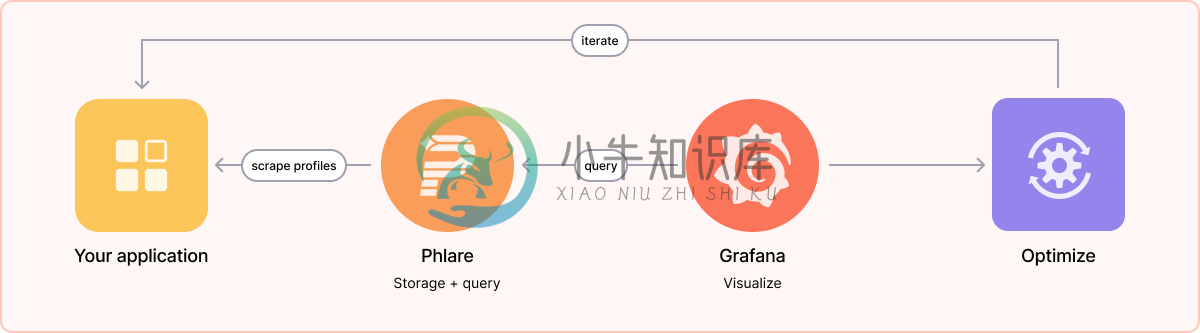
Phlare 架构
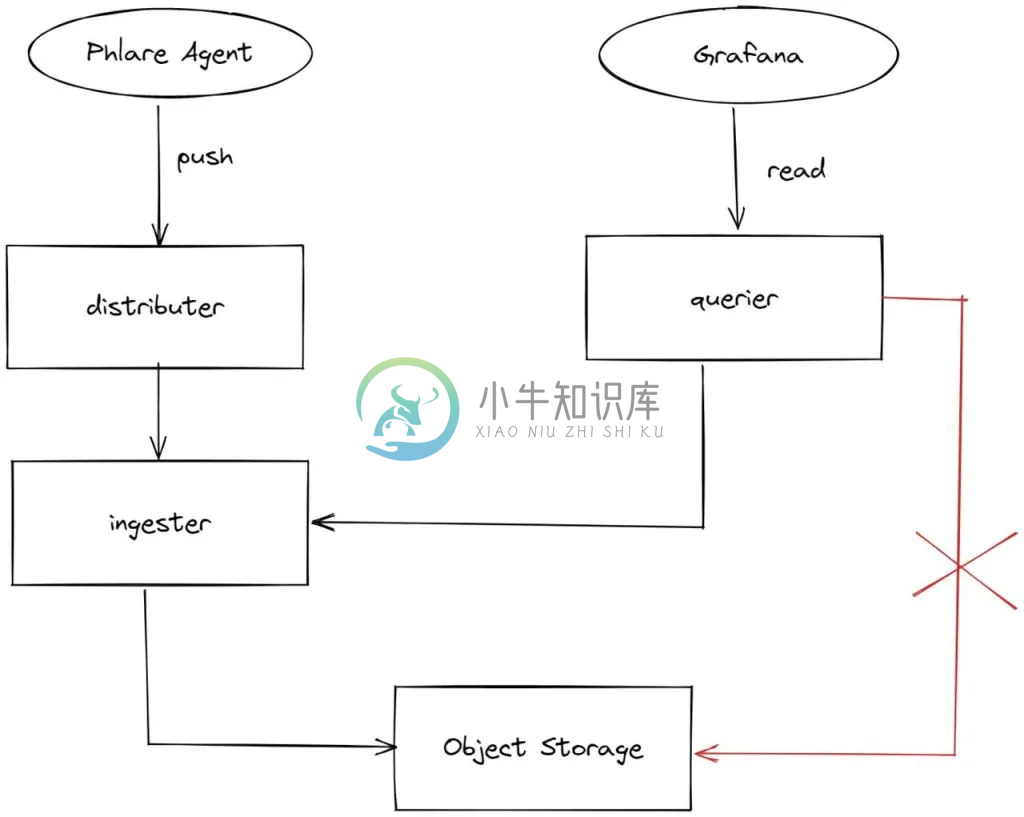
-
Grab the Cluster Monitoring Quickstart Kubernetes Manifests! 获取集群监控快速入门Kubernetes清单! Kubernetes Cluster Monitoring Quickstart on GitHub GitHub上的Kubernetes集群监控快速入门 介绍 (Introduction) Along with tracing
-
based on:serverless-kinesis-streams, but auto create Kinesis streams 在尝试了使用 Kinesis Stream 处理数据之后,我发现它并不能做什么。接着,便开始找寻其它方式,其中一个就是:Amazon Kinesis Firehose Amazon Kinesis Firehose 是将流数据加载到 AWS 的最简单方式。它可以
-
问题内容: 在许多使用MongoDB的入门示例中,您将看到类似以下的代码: 如果MongoDB与任何其他数据库系统一样,并且操作通常在时间上很昂贵。 所以,我的问题是这样的:只需执行一次,将返回值分配给某个全局模块即可,模块中具有各种功能就可以进行各种与数据库相关的工作(将文档插入集合,更新文档等)。 ),然后由应用程序的其他部分调用它们(从而重新使用该值),然后,在应用程序完成后,才执行。 换句
-
有时候,对于我们的决定只要有一点点的数据支持就够了。一点点的变化,可能就决定了我们产品的好坏。我们可能会因此而作出一些些改变,这些改变可能会让我们打败巨头。 这一点和 Growth 的构建过程也很相像,在最开始的时候我只是想制定一个成长路线。而后,我发现这好像是一个不错的 idea,我就开始去构建这个 idea。于是它变成了 Growth,这时候我需要依靠什么去分析用户喜欢的功能呢?我没有那么多的
-
在ISO 8601中,持续时间的格式为PT5M(5分钟)或PT2H5M(2小时5分钟)。我有一个JSON文件,其中包含这种格式的值。我想知道spark是否可以提取分钟的持续时间。我尝试将其读取为“DateType”,并使用“minutes”函数获取分钟数,结果返回空值。 示例json 目前,我正在将其作为字符串读取并使用“regex_extract”函数。我想知道一种更有效的方法。 https:/
-
笔试+3轮面试,笔试题比较开放,主要考察一些基本的概念,业务一面:首先自我介绍,面试官就简历提问,接着会跟你一个具体的案例让你回答如何识别黑产用户,附加口述一道智力测试题,最后是反问,整体面试很轻松,由于反问阶段表现得很好,所以一面后三分钟就通知结果了。 二面应该是部门leader面,更多的还是深挖简历的内容,真的很细很细,面完以后感觉表现一般,然后hr通知结果待定,基本没戏了。
-
9.20一面hr面 1.自我介绍 2.实习的收获 3.在校成绩以及相关情况 4.实习中有什么做的不足的地方 5.性格的优缺点 6.拉家常 7.反问 没想到一面竟然是hr面 #面经##4399##4399面经##数据分析师#
-
云端业务和数据已接入小米生态云的生态链企业,可以在和小米签署保密协议之后,派工程师入驻小米,以小米内部业务使用数据的流程、方式使用数据;生态链企业和小米join的数据在小米的环境里训练模型并搭建API服务,小米会协助完成生态链企业对小米数据的需求。 后续会在生态云上提供API自助服务。
-
Discover数据分析一面 - Phone Interview - 全英文 手机开了自动拦截垃圾电话,前面几个电话没接到之后才反应过来关了。(被假中国海关的诈骗电话骚扰无数次) 1. 自我介绍 2. 最喜欢的课程,为什么? 3. 怎么知道Discover和这个工作的? 4. 有在信用卡领域的工作经验吗?(没有,只知道刷卡😂) 5. 对简历一个项目详细介绍 6. SQL where和group