《grafana》专题
-
Grafana OnCall
Grafana OnCall 是一种开源事件响应管理工具,旨在帮助团队改进协作并更快地解决事件。Grafana OnCall 的一些核心优势包括: 支持广泛的监控系统: Grafana OnCall 支持与许多监控系统的集成,包括 Grafana、Prometheus、AlertManager、Zabbix 等。 减少警报噪音:自动警报分组有助于避免警报风暴并减少事件期间的噪音。当满足解析条件时,
-
Grafana Faro
Grafana Faro 是用于收集有关 Web 应用程序前端运行状况数据的开源函数库,开发者将其提供的 Grafana Faro Web SDK 嵌入到前端应用程序,该程序就会自动开始收集日志、错误和性能指标,然后添加元数据以便找到有用的条目,并将其转发到 Grafana 代理(需启用集成的应用程序代理接收器),然后它可以将这些数据发送到 Prometheus、Grafana Loki 或 Gr
-
python - 使用 Grafana+Prometheus 生态统计 django、flask、fastapi 的 rps等指标是如何实现的?
Grafana+Prometheus 是定时主动访问 django、flask、fastapi 的相关接口来获取 rps 指标 但是我们部署 django、flask、fastapi 服务的时候,往往是多个进程,比如 10 个进程(master-slave),请求会被转发到任意一个进程,而 rps 这些指标是记录在进程内,这就会导致 rps 统计的不是整体的 rps,而是某个进程的 rps?
-
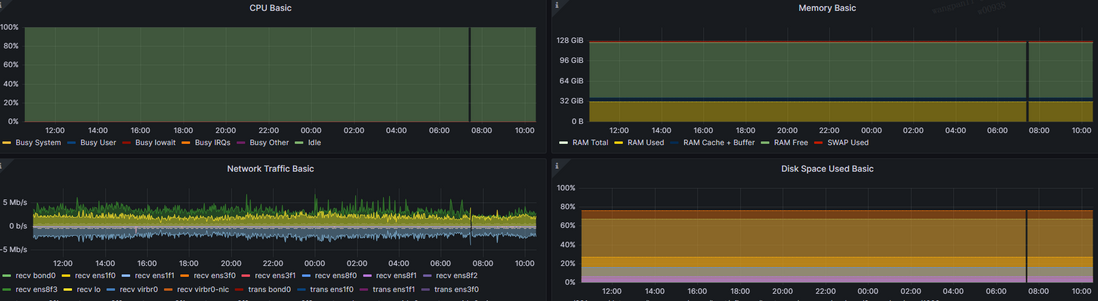 prometheus和grafana出现数据上的真空状态(多台,但不是全部)?
prometheus和grafana出现数据上的真空状态(多台,但不是全部)?用prometheus和grafana监控服务器,发现同一时间出现多台服务器(不是所有)数据上的真空状态,而且不止是windows服务器,linux也有这种现象。请大佬指点迷津,可能是什么原因造成了这种多台真空 下面是其中一台的情况 看了其他服务器,发现有的从来没有这种真空,就排除了可能是监控业务的问题
-
javascript - grafana如何与前端页面交互?
如题,目前通过iframe组件将grafana展示在前端页面中,现想要实现:用户输入设备名并选择时间区间后展示响应时间内某设备的数据(某值的折线图),请问如何配置grafana以及前端代码实现此功能? 目前iframe中相关链接只有类似这样的: localhost:3000/d-solo/afd33dcf-75ea-77bc-a4d1-32237d284c94/new-dashboard?orgI