《搜索树》专题
-
如何使用单元格值搜索行索引
我正在使用google电子表格API v4 for java。 我的电子表格看起来像这样- 我想查找带有用户“User2”和时间银行(空值)的行索引。之后,我想使用此行索引在该行中添加时间值。是否可以在不知道范围或索引的情况下逐行搜索单元格值? 在上面的示例中,当它与条件(User='User2'和Time='')匹配时,它应该只返回最后一行索引。甚至更好的是,是否存在查找和替换API,它将查找行
-
Lucene查询返回空字符串索引搜索
下面的lucene查询返回空字符串请帮忙,提前谢谢
-
弹性搜索java(spring)在索引中的问题
我已经将弹性搜索1.7.1与spring应用程序集成在一起。我有一个cron作业,它在每次运行时更新弹性搜索的索引。我遵循了github上的各种示例代码来使其工作。首先,我为索引目的自动连接了ElasticSearchOperations: 然后以以下方式执行内部循环索引 当我第一次运行它时,它就像预期的那样工作。我已经在config文件夹中的elasticsearch.yml中将cluster重
-
在弹性搜索中创建索引时出错
我是弹性搜索的新手,我正在尝试使用下面的映射创建索引,我在网上找到了这些映射,并使用kibana作为我的客户机,它抛出错误。 “类型”:“映射程序解析异常”,“原因”:“根映射定义有不受支持的参数:[local_test:{u all={enabled=false},properties={amount={type=long},user_id={type=keyword},recurtive={t
-
C#创建二叉搜索树的方法
本文向大家介绍C#创建二叉搜索树的方法,包括了C#创建二叉搜索树的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#创建二叉搜索树的方法。分享给大家供大家参考。具体如下: 希望本文所述对大家的C#程序设计有所帮助。
-
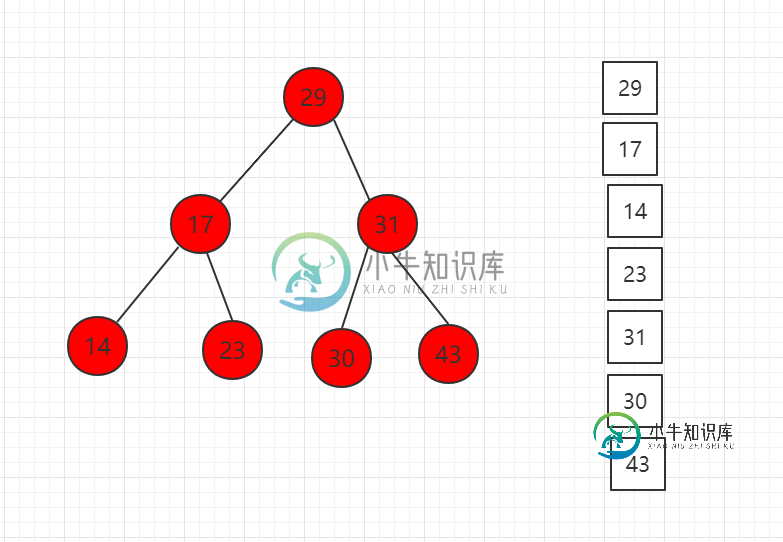 二分搜索树深度优先遍历
二分搜索树深度优先遍历主要内容:src/runoob/binary/Traverse.java 文件代码:二分搜索树遍历分为两大类,深度优先遍历和层序遍历。 深度优先遍历分为三种:先序遍历(preorder tree walk)、中序遍历(inorder tree walk)、后序遍历(postorder tree walk),分别为: 1、前序遍历:先访问当前节点,再依次递归访问左右子树。 2、中序遍历:先递归访问左子树,再访问自身,再递归访问右子树。 3、后序遍历:先递归访问左右子树,再访问自身节
-
从二叉搜索树中删除元素
我在做作业,实现自己的二叉查找树。问题是,我们有自己的节点实现,它的父节点是不可直接访问的。 我一直在寻找答案,但我不想完全照搬解决方案,尽管如此,我似乎仍然没有得到正确的答案。我错过了一些元素没有被删除的情况。 你能帮帮我吗?我做错了什么? 这是删除方法: 节点使用通用接口 只有比较的方法。它看起来像这样 我在remove中使用了另一种方法,它设置节点的父节点的子节点,具体取决于它的左子节点还是
-
二进制搜索树的递归深度
这是作业,不要贴代码。求你了,谢谢你。 我被指派创建一个计算BST中特定的深度的方法。 为此,我需要a方法。因此,要递归地找到它,我需要创建一个助手方法。 我知道我需要在树中搜索包含我要查找的数据的节点。为此,我编写了以下代码: 然而,这是行不通的,因为每次进行递归调用时,将保持;本质上,它是在重置深度值。我不知道如何在调用之间保持的值。
-
使用文本打印二叉搜索树
我想以这种格式打印二叉查找树: 我想我必须获得树的深度,然后,对于每个级别,在每个元素前后打印一些空格。 我不知道如何继续。 节点类:
-
查找树是否为二元搜索树
这种方法在确定树是否为BST时是错误的吗?节点的左子树仅包含键小于节点键的节点。节点的右子树仅包含键大于节点键的节点。左右子树也必须是二叉搜索树。我的代码是:
-
6.17.AVL平衡二叉搜索树实现
现在我们已经证明保持 AVL树的平衡将是一个很大的性能改进,让我们看看如何增加过程来插入一个新的键到树。由于所有新的键作为叶节点插入到树中,并且我们知道新叶的平衡因子为零,所以刚刚插入的节点没有新的要求。但一旦添加新叶,我们必须更新其父的平衡因子。这个新叶如何影响父的平衡因子取决于叶节点是左孩子还是右孩子。如果新节点是右子节点,则父节点的平衡因子将减少1。如果新节点是左子节点,则父节点的平衡因子将
-
36. 二叉搜索树与双向链表
NowCoder 题目描述 输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。 解题思路 // java private TreeNode pre = null; private TreeNode head = null; public TreeNode Convert(TreeNode root) { inOrder(ro
-
在平衡二叉树中搜索项目
如果我有一个平衡的二叉树,并且我想在其中搜索一个项目,那么大的oh时间复杂度会是O(n)吗?在二叉树中搜索一个项目,不管它是否平衡,会改变O(n)的大时间复杂性吗?我知道如果我们有一个平衡的BST,那么搜索一个项目就等于BST的高度so O(log n),但是普通的二叉树呢?
-
递归二叉搜索树删除方法
首先,这是家庭作业,所以把它放在外面。 我应该用特定的方法实现二叉查找树: void insert(字符串)、boolean remove(字符串)和boolean find(字符串)。 我已经能够成功地编程和测试插入,并找到方法,但我有困难与删除。 我的程序中发生的事情是,删除实际上并没有从树中删除任何东西,我相信这是因为它只引用当前节点的本地创建,但我可能错了。我认为我可以实现我需要测试的不同
-
二进制搜索树的删除方法
我正在一个实验室工作,该实验室要求我为二进制搜索树创建一个删除方法。这是我的remove方法的代码。 运行代码时得到的输出是: 移除90后的树。70 80 85 98 100 120 移除70. 80 85 98 100 120后的树 移除85后的树。80 98 100 120 移除98后的树。80 100 120 移除80后的树。100 120 移除120后的树。100 移除100后的树。100