《聚类》专题
-
dbscan 基于密度的空间聚类算法
参考文献:百度百科 http://baike.baidu.com 我的算法库:https://github.com/linyiqun/lyq-algorithms-lib 算法介绍 说到聚类算法,大家如果有看过我写的一些关于机器学习的算法文章,一定都这类算法不会陌生,之前将的是划分算法(K均值算法)和层次聚类算法(BIRCH算法),各有优缺点和好坏。本文所述的算法是另外一类的聚类算法,他能够克服
-
第 10 章 K-Means(K-均值)聚类算法
聚类 聚类,简单来说,就是将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好。它是一种无监督的学习(Unsupervised Learning)方法,不需要预先标注好的训练集。聚类与分类最大的区别就是分类的目标事先已知,例如猫狗识别,你在分类之前已经预先知道要将它分为猫、狗两个种类;而在你聚类之前,你对你的目标是未知的,同样以动物为例,对于一个动物集来
-
八、无监督学习第二部分:聚类
聚类是根据一些预定义的相似性或距离(相异性)度量(例如欧氏距离),将样本收集到相似样本分组中的任务。 在本节中,我们将在一些人造和真实数据集上,探讨一些基本聚类任务。 以下是聚类算法的一些常见应用: 用于数据减少的压缩 将数据汇总为推荐系统的再处理步骤 相似性: 分组相关的网络新闻(例如 Google 新闻)和网络搜索结果 为投资组合管理分组相关股票报价 为市场分析建立客户档案 为无监督特征提取构
-
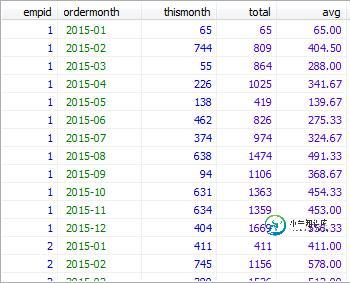 mysql滑动聚合/年初至今聚合原理与用法实例分析
mysql滑动聚合/年初至今聚合原理与用法实例分析本文向大家介绍mysql滑动聚合/年初至今聚合原理与用法实例分析,包括了mysql滑动聚合/年初至今聚合原理与用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了mysql滑动聚合/年初至今聚合原理与用法。分享给大家供大家参考,具体如下: 滑动聚合是按顺序对滑动窗口范围内的数据进行聚合的操作。下累积聚合不同,滑动聚合并不是统计开始计算的位置到当前位置的数据。 这里以统计最近三个月中
-
Apache Flink,事件时间聚合-水印是否与聚合密钥相关联?
当我们进行基于事件时间的聚合时,有一个实时的数据流--某个键的事件的水印会触发其他键的窗口操作吗? id为2的事件是否会触发id为1的12:00-12:10的时间窗口?或者只有在12:20下一个id为1的事件到达时才会发生?
-
Elasticsearch排序术语聚合热门子聚合中字段后的存储桶
我想根据top hits聚合中第一个元素所拥有的属性,从terms聚合中订购Bucket。 我的尽力而为查询如下(有语法错误): 有人知道如何做到这一点吗? 例子: 按“a”分组,按“id”(desc)排序存储桶,并按“b”(desc)排序最热门的内容,将给出:
-
自动热键:如何在不聚焦另一个控件的情况下取消聚焦控件(取消聚焦所有控件)?
我正在写一个自动热键脚本,它可以摆弄一些Photoshop窗口和控件。 我需要能够解除当前焦点控件(比如Edit3)的焦点,这样之后就没有控件有焦点了(我可以解释为什么必要时我需要这么做,但这似乎无关紧要,我只需要解除所有控件的焦点)。 AHK的ControlFocus命令不提供这样的选项。 我尝试使用这样的Windows消息: 但它什么都没用。相比之下,另一种方法的效果与预期一致,并将重点放在控
-
 聚类算法有哪些,优缺点是什么?
聚类算法有哪些,优缺点是什么?本文向大家介绍聚类算法有哪些,优缺点是什么?相关面试题,主要包含被问及聚类算法有哪些,优缺点是什么?时的应答技巧和注意事项,需要的朋友参考一下 基于层次的聚类 做法是将每个对象都看做一个类,计算两两之间距离最小的对象归为一类,然后重复这样的操作直至成为一个类,这种方式是采用贪心的方法,一步错步步错,时间复杂度过高,可解释性比较好 基于划分的聚类(k-Means) 原则是保证簇内的数据距离尽可能小,
-
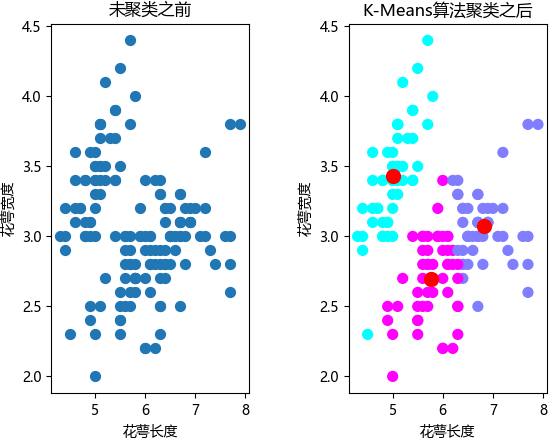 K-means聚类算法的应用以及实现
K-means聚类算法的应用以及实现主要内容:算法应用场景,Sklearn使用K-means算法,总结K-means 聚类算法属于无监督学习,它会将相似的对象归到同一个簇中,该算法原理简单,执行效率高,并且容易实现,是解决聚类问题的经典算法。 尽管如此,任何一款算法都不可能做到完美无瑕,K-measn 算法也有自身的不足之处,比如 K-means 需要通过算术平均数来度量距离,因此数据集的为维度属性必须转换为数值类型,同时 K-means 算法使用随机选择的方式来确定 K 的数量和初始化质心 ,因
-
C#图像颜色聚类高效方法实例
本文向大家介绍C#图像颜色聚类高效方法实例,包括了C#图像颜色聚类高效方法实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#图像颜色聚类高效方法。分享给大家供大家参考。具体分析如下: 图像颜色聚类的方法有很多,但是对于视频监控而言,现有方法很难满足实时性的要求,这里介绍一种位屏蔽压缩的方法实现颜色聚类,可以满足实时性的要求。 位屏蔽法就是在3D的RGB真彩空间中近似均匀采样的颜色压缩
-
带有数据分片和聚类的mariadb复制
我们建立了三个节点的mariaDB galera集群,基本上是一个多主集群,在集群中的节点之间同步复制数据,最终实现了集群中任意节点的读/写操作。然而,这并没有解决我们的问题。由于mariadb有不同的口味,如mariadb maxscale用于分片,我们还可以在galera集群中应用异步复制。同时,我们还可以利用galera集群上的ReaWrite拆分器和schemaRouter进行负载分配。如
-
Elasticsearch聚合不适用于嵌套类型字段
我无法使elasticsearch聚合+筛选器处理嵌套字段。数据模式(相关部分)如下所示: 本质上,“RB”对象包含一个名为“project”的嵌套字段,该字段包含另外两个字段--“name”和“age”。我正在运行的查询: 该查询应该生成与日期筛选器匹配的前10个项目(project.name字段),按其年龄中值排序,忽略数据库中提及次数少于5次的项目。中位数应仅用于匹配筛选器(日期范围)的项目
-
通过非聚类键对结果进行排序
我们使用Cassandra的用例是显示一篇博客文章的前10名最近访问者。以下是Cassandra表定义 现在,为了显示给定博客帖子的前10名最近访问者,需要在时间戳desc上有一个明确的“order by”子句。因为visted_ts不是Cassandra中集群列的一部分,所以我们无法完成这项工作。visited_ts不是集群列的一部分的原因是为了避免记录重复(读为重复)访问者。主键的设计方式是为
-
java.lang.类异常:com.mongodb.client.internal.聚合IterableImpl不能强制java.util.ArrayList
我有以下文件。我需要用下面的集合与requestParam系统匹配,如果requestParam与电子邮件系统匹配,则需要获得结果值。上下快速移动系统 这里请求Param是系统 我已经尝试了下面的语法,得到了java.lang.ClassCastExctive:com.mongodb.client.internal.Aggregate IterableImpl不能转换为java.util.Arra
-
什么是耦合和凝聚力?
本文向大家介绍什么是耦合和凝聚力?相关面试题,主要包含被问及什么是耦合和凝聚力?时的应答技巧和注意事项,需要的朋友参考一下 组件之间依赖关系强度的度量被认为是耦合。一个好的设计总是被认为具有高内聚力和低耦合性。 面试官经常会问起凝聚力。它也是另一个测量单位。更像是一个模块内部的元素保持结合的程度。 必须记住,设计微服务的一个重要关键是低耦合和高内聚的组合。当低耦合时,服务对其他服务的依赖很少。这样