《雪花算法》专题
-
如果我在Java中省略花括号可以吗?
问题内容: 我已经搜索过了,但是找不到答案,无论出于什么原因,我都感到羞耻,无法问教授,因为那种感觉当成千上万的人盯着你看时… 无论如何,我的问题是使用括号的重要性是什么?如果我省略它们可以吗?例: 与 我知道它们都可以使用,但是如果省略括号(由于能见度,我倾向于做很多事情)会改变任何东西吗?正如我说的,我知道它有效,我测试了数十次,但是现在我的一些单项作业越来越大,出于某种原因,我出于非理性的恐
-
火花的Log4j2。log4j默认属性文件在哪里?
我在哪里可以找到默认的log4j配置文件的工人和驱动程序? 1) 目前Spark正在将执行器/工作者(stdout/stderr)级别的日志记录到工作文件夹,并将驱动程序级别的日志记录到日志文件夹。 我在哪里可以找到这个配置? 我尝试将Log4j2用于spark,而不是log4j。我正在尝试获取默认属性文件,以便可以将其中的一些内容复制到log4j2属性XML。 2) 另外,是否可以修改当前正在运
-
我正在检查棉花糖中的呼叫权限
当我运行app时,它在logcat中显示这个 java.lang.SecurityException:权限拒绝:从ProcessRecord{2dd511f 24656:com.marg.pharmanxt/u0a158}(PID=24656,UID=10158)中启动意图{act=android.Intent.action.call dat=tel:xxxxxxxxxcapt=2dd511f 2
-
火花连接器负载与sstableloader性能的关系
我现在有一个spark工作,它从HDFS中提取数据,并将数据转换为平面文件,以加载到Cassandra中。
-
如何运行火花壳与纱在客户模式?
我已经在一个15节点的Hadoop集群上安装了。所有节点都运行和最新版本的Hadoop。Hadoop集群本身是功能性的,例如,YARN可以成功地运行各种MapReduce作业。 我可以使用以下命令在节点上本地运行Spark Shell,而不会出现任何问题:。 你知道为什么我不能用客户端模式在纱线上运行Spark Shell吗?
-
在CDH 5.4中将火花连接在纱线簇上
-
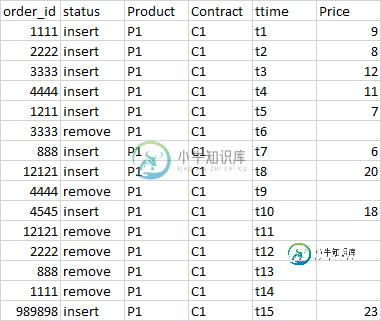 时间序列/刻度数据集的火花转换
时间序列/刻度数据集的火花转换我们在蜂巢中有一个表,它将每天结束时的交易订单数据存储为order_date。其他重要的列是产品、合同、价格(订单价格)、ttime(交易时间)状态(插入、更新或删除)价格(订单价格) 我们必须以滴答数据的方式从主表中构建一个图表表,其中包含从市场开盘到开盘的上午每行(订单)的最大和最小价格订单。i、 e对于给定的订单,我们将有4列填充为maxPrice(到目前为止的最高价格)、maxpriceO
-
 3.15 同花顺 C++二面,被锤了,希望能过
3.15 同花顺 C++二面,被锤了,希望能过1、C++的学习方式与遇到的问题 2、项目开发过程的收获 3、多线程开发的注意事项 4、多进程与多线程的优缺点及适应场景 5、共享内存原理、在虚存空间位置 6、extern的作用 7、extern “C”的作用 8、vector中插入一万个数据如何提高效率 9、再把这一万个数据清掉后内存如何变化 10、普通模板函数定义在哪里,为什么 11、普通模板函数定义在头文件里为什么链接器不报符号重定义 12
-
 同花顺(前端一面——30分钟,估计凉了)
同花顺(前端一面——30分钟,估计凉了)因为我个人的情况比较特殊,所以大部分都是问个人情况。楼主是211的,临近毕业才选择All in 前端,最近也是边学边面,所以面试官一直在问我的情况,很好奇,没有问太多前端的问题 1.自我介绍 2.项目深挖(挖了10分钟) 3.问了考研情况,问了挺细,为了考为什么不考,聊了人生 4.了解学习情况 5.让我写写代码来看看我的编写习惯 6.因为我简历写了一个简单的静态页面Git个人博客(很简陋, 有兴趣
-
 同花顺前端B2B一面(65min)二面(40min)凉经
同花顺前端B2B一面(65min)二面(40min)凉经全程问项目,一个八股没问。 1、听你经历做过后端,你一般后端用了哪些技术? 2、服务端渲染用的什么技术? 3、项目介绍一下? 4、项目中登录注册具体的实现? 5、注册中post传参的主要形式、数据格式?与get传参的区别? 6、axios二次封装了哪些东西? 7、响应拦截器可以做哪些操作? 8、项目三个角色权限如何控制? 9、路由跳转的方式?回退? 10、路由传参的方式?具体怎么实现 11、问了另
-
为什么泡菜比np.save花费更长的时间?
问题内容: 我想保存一个或数组。 我尝试与和一起使用,发现前者总是花费更少的时间。 我的实际数据要大得多,但在这里我仅展示一小段用于演示目的: 输出: 我的实际大小(字典中约有100,000个键)时差更加明显。 为什么在保存和加载时,泡菜比np.save花费的时间更长? 我什么时候应该使用? 问题答案: 因为只要书面对象不包含Python数据, numpy对象在内存中的表示方式比Python对象简
-
如何在python中操作火花数据帧?[重复]
有一个spark_df有许多重复如下: 现在我想将这个spark_df转换如下: 我在熊猫身上知道这一点。但是我正在努力学习火花,这样我就可以把它实施到大数据中。如果有人能帮忙,那就太好了。
-
在单独的机器上运行火花驱动器
目前,我正在群集模式(独立群集)下使用Spark 2.0.0,群集配置如下: 工作线程:使用了4个内核:总共32个,使用了32个内存:总共54.7 GB,使用了42.0 GB 我有4个奴隶(工人)和1台主机。火花盘有三个主要部件-主部件、驱动部件、工作部件(参考) 现在我的问题是,驱动程序正在其中一个工作节点中启动,这阻碍了我在其全部容量(RAM方面)中使用工作节点。例如,如果我在运行spark作
-
如何解码List的byte [] 到数据集 在火花?
问题内容: 我在我的项目中将spark-sql-2.3.1v和kafka与java8一起使用。我正在尝试将主题接收的byte []转换为kafka使用者方面的数据集。 这是详细信息 我有 我定义为 但是消息定义为 我试图定义为 我使用序列化将消息作为byte []发送到kafka主题。 我在Consumer上成功接收到消息字节[]。我正在尝试将其转换为数据集?? 怎么做 ? 出现错误: 线程“主”
-
 Python实现PS滤镜的万花筒效果示例
Python实现PS滤镜的万花筒效果示例本文向大家介绍Python实现PS滤镜的万花筒效果示例,包括了Python实现PS滤镜的万花筒效果示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现PS滤镜的万花筒效果。分享给大家供大家参考,具体如下: 这里用 Python 实现 PS 的一种滤镜效果,称为万花筒。也是对图像做各种扭曲变换,最后图像呈现的效果就像从万花筒中看到的一样: 图像的效果可以参考附录说明。具体Py