
时间序列/刻度数据集的火花转换

我们在蜂巢中有一个表,它将每天结束时的交易订单数据存储为order_date。其他重要的列是产品、合同、价格(订单价格)、ttime(交易时间)状态(插入、更新或删除)价格(订单价格)
我们必须以滴答数据的方式从主表中构建一个图表表,其中包含从市场开盘到开盘的上午每行(订单)的最大和最小价格订单。i、 e对于给定的订单,我们将有4列填充为maxPrice(到目前为止的最高价格)、maxpriceOrderId(最高价格的orderid)、minPrice和minPriceOrderId
这必须适用于每个产品、合同,即该产品、合同的最高和最低价格。
在计算这些值时,我们需要从聚合中排除所有已关闭的订单。i、 e迄今为止所有订单价格的最大值和最小值,不包括状态为“删除”的订单
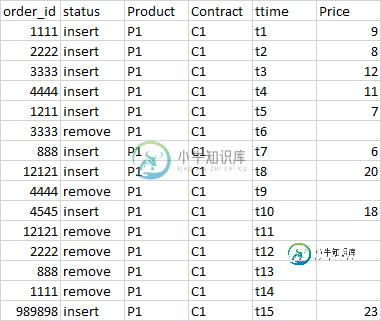
输出记录
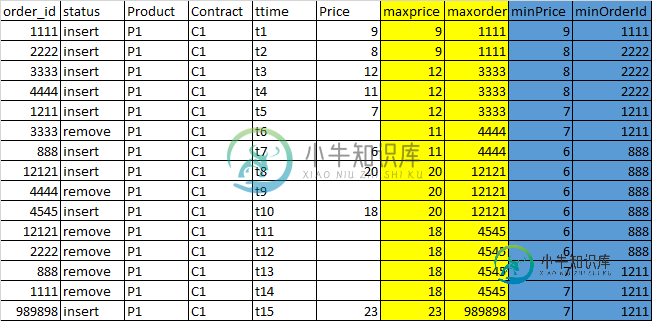
为了给出一个简单的SQL视图——问题用自连接解决,看起来像这样:在ttime上有一个有序的数据集,我们必须得到特定产品的最大和最小价格,为每一行(订单)签订合同从早上到订单时间。这将在批处理中为每个eod(order_date)数据集运行:
select mainSet.order_id, mainSet.product,mainSet.contract,mainSet.order_date,mainSet.price,mainSet.ttime,mainSet.status,
max(aggSet.price) over (partition by mainSet.product,mainSet.contract,mainSet.ttime) as max_price,
first_value(aggSet.order_id) over (partition by mainSet.product,mainSet.contract,mainSet.ttime) order by (aggSet.price desc,aggSet.ttime desc ) as maxOrderId
min(aggSet.price) over (partition by mainSet.product,mainSet.contract,mainSet.ttime) as min_price as min_price
first_value(aggSet.order_id) over (partition by mainSet.product,mainSet.contract,mainSet.ttime) order by (aggSet.price ,aggSet.ttime) as minOrderId
from order_table mainSet
join order_table aggSet
ON (mainSet.produuct=aggSet.product,
mainSet.contract=aggSet.contract,
mainSet.ttime>=aggSet.ttime,
aggSet.status <> 'Remove')
用火花书写:
我们从spark sql开始,如下所示:
val mainDF: DataFrame= sparkSession.sql("select * from order_table where order_date ='eod_date' ")
val ndf=mainDf.alias("mainSet").join(mainDf.alias("aggSet"),
(col("mainSet.product")===col("aggSet.product")
&& col("mainSet.contract")===col("aggSet.contract")
&& col("mainSet.ttime")>= col("aggSet.ttime")
&& col("aggSet.status") <> "Remove")
,"inner")
.select(mainSet.order_id,mainSet.ttime,mainSet.product,mainSet.contract,mainSet.order_date,mainSet.price,mainSet.status,aggSet.order_id as agg_orderid,aggSet.ttime as agg_ttime,price as agg_price) //Renaming of columns
val max_window = Window.partitionBy(col("product"),col("contract"),col("ttime"))
val min_window = Window.partitionBy(col("product"),col("contract"),col("ttime"))
val maxPriceCol = max(col("agg_price")).over(max_window)
val minPriceCol = min(col("agg_price")).over(min_window)
val firstMaxorder = first_value(col("agg_orderid")).over(max_window.orderBy(col("agg_price").desc, col("agg_ttime").desc))
val firstMinorder = first_value(col("agg_orderid")).over(min_window.orderBy(col("agg_price"), col("agg_ttime")))
val priceDF= ndf.withColumn("max_price",maxPriceCol)
.withColumn("maxOrderId",firstMaxorder)
.withColumn("min_price",minPriceCol)
.withColumn("minOrderId",firstMinorder)
priceDF.show(20)
音量统计:
平均计数700万条记录每组(产品、合同)的平均计数=60万条
这项工作持续了几个小时,只是没有完成。我尝试过增加记忆和其他参数,但没有成功。作业被卡住了,很多时候,我的内存问题容器因为超出内存限制而被纱线杀死。使用4.9 GB的4.5 GB物理内存。考虑助推火花。纱线遗嘱执行人。memoryOverhead
另一种方法:
对最低的组列(product和contract)进行重新分区,然后按时在分区内排序,这样我们就可以按时收到mapPartition函数所订购的每一行。
在分区级别维护集合(键为order_id,价格为值)的同时执行map分区,以计算最大和最小价格及其订单。
当我们收到订单时,我们将继续从收款中删除状态为“删除”的订单。一旦收集被更新为一个给定的行中,我们可以计算最大值和最小值从收集和返回更新的行。
val mainDF: DataFrame= sparkSession.sql("select order_id,product,contract,order_date,price,status,null as maxPrice,null as maxPriceOrderId,null as minPrice,null as minPriceOrderId from order_table where order_date ='eod_date' ").repartitionByRange(col("product"),col("contract"))
case class summary(order_id:String ,ttime:string,product:String,contract :String,order_date:String,price:BigDecimal,status :String,var maxPrice:BigDecimal,var maxPriceOrderId:String ,var minPrice:BigDecimal,var minPriceOrderId String)
val summaryEncoder = Encoders.product[summary]
val priceDF= mainDF.as[summary](summaryEncoder).sortWithinPartitions(col("ttime")).mapPartitions( iter => {
//collection at partition level
//key as order_id and value as price
var priceCollection = Map[String, BigDecimal]()
iter.map( row => {
val orderId= row.order_id
val rowprice= row.price
priceCollection = row.status match {
case "Remove" => if (priceCollection.contains(orderId)) priceCollection -= orderId
case _ => priceCollection += (orderId -> rowPrice)
}
row.maxPrice = if(priceCollection.size > 0) priceCollection.maxBy(_._2)._2 // Gives key,value tuple from collectin for max value )
row.maxPriceOrderId = if(priceCollection.size > 0) priceCollection.maxBy(_._2)._1
row.minPrice = if(priceCollection.size > 0) priceCollection.minBy(_._2)._2 // Gives key,value tuple from collectin for min value )
row.minPriceOrderId = if(priceCollection.size > 0) priceCollection.minBy(_._2)._1
row
})
}).show(20)
对于较小的数据集,它运行良好并在20分钟内完成,但我发现对于23个工厂的记录(有17个不同的产品和合同),结果似乎不正确。我可以看到来自mappartition的一个分区(输入分割)的数据正在进入另一个分区,从而将值弄乱。
--
--
非常感谢你的帮助,因为我们被困在这里了。
共有2个答案

用于重新分区数据的方法repartitionByRange对这些列表达式上的数据进行分区,但进行范围分区。您需要的是对这些列进行哈希分区。
将方法更改为重新分区并将这些列传递给它,它应该确保相同的值组最终在一个分区中。

编辑:这里有一篇关于为什么许多小文件是坏的
为什么压缩不良的数据是坏的?压缩不良的数据对Spark应用程序不利,因为它的处理速度非常慢。继续我们前面的例子,任何时候我们想要处理一天的事件,我们都必须打开86,400个文件来获取数据。这大大降低了处理速度,因为我们的Spark应用程序实际上花费了大部分时间来打开和关闭文件。我们通常希望Spark应用程序将大部分时间用于实际处理数据。接下来,我们将进行一些实验,以显示使用适当压缩的数据与使用较差压缩的数据时html" target="_blank">性能的差异。
我敢打赌,如果您正确地将源数据划分为您要加入的内容,并删除所有这些窗口,您最终会得到一个更好的地方。
每次点击partitionBy,都是在强制进行洗牌,每次点击orderBy,都是在强制进行昂贵的排序。
我建议你看看DatasetAPI,并学习一些面向O(n)时间计算的GroupBy和phaMapGroup/减少/滑动。您可以在一次通过中获得您的最小/最大值。
此外,听起来您的驱动程序由于许多小文件问题而内存不足。尽量压缩源数据,并对表进行适当分区。在这种特殊情况下,我建议按订单日期(可能是每天?)进行分区然后对产品和合同进行子划分。
这里有一个片段,我花了大约30分钟来写,它的运行可能比你的窗口函数好得多。它应该在O(n)时间内运行,但它不能弥补如果您有许多小文件的问题。如果有东西不见了,告诉我。
import org.apache.spark.sql.{Dataset, Encoder, Encoders, SparkSession}
import scala.collection.mutable
case class Summary(
order_id: String,
ttime: String,
product: String,
contract: String,
order_date: String,
price: BigDecimal,
status: String,
maxPrice: BigDecimal = 0,
maxPriceOrderId: String = null,
minPrice: BigDecimal = 0,
minPriceOrderId: String = null
)
class Workflow()(implicit spark: SparkSession) {
import MinMaxer.summaryEncoder
val mainDs: Dataset[Summary] =
spark.sql(
"""
select order_id, ttime, product, contract, order_date, price, status
from order_table where order_date ='eod_date'
"""
).as[Summary]
MinMaxer.minMaxDataset(mainDs)
}
object MinMaxer {
implicit val summaryEncoder: Encoder[Summary] = Encoders.product[Summary]
implicit val groupEncoder: Encoder[(String, String)] = Encoders.product[(String, String)]
object SummaryOrderer extends Ordering[Summary] {
def compare(x: Summary, y: Summary): Int = x.ttime.compareTo(y.ttime)
}
def minMaxDataset(ds: Dataset[Summary]): Dataset[Summary] = {
ds
.groupByKey(x => (x.product, x.contract))
.flatMapGroups({ case (_, t) =>
val sortedRecords: Seq[Summary] = t.toSeq.sorted(SummaryOrderer)
generateMinMax(sortedRecords)
})
}
def generateMinMax(summaries: Seq[Summary]): Seq[Summary] = {
summaries.foldLeft(mutable.ListBuffer[Summary]())({case (b, summary) =>
if (b.lastOption.nonEmpty) {
val lastSummary: Summary = b.last
var minPrice: BigDecimal = 0
var minPriceOrderId: String = null
var maxPrice: BigDecimal = 0
var maxPriceOrderId: String = null
if (summary.status != "remove") {
if (lastSummary.minPrice >= summary.price) {
minPrice = summary.price
minPriceOrderId = summary.order_id
} else {
minPrice = lastSummary.minPrice
minPriceOrderId = lastSummary.minPriceOrderId
}
if (lastSummary.maxPrice <= summary.price) {
maxPrice = summary.price
maxPriceOrderId = summary.order_id
} else {
maxPrice = lastSummary.maxPrice
maxPriceOrderId = lastSummary.maxPriceOrderId
}
b.append(
summary.copy(
maxPrice = maxPrice,
maxPriceOrderId = maxPriceOrderId,
minPrice = minPrice,
minPriceOrderId = minPriceOrderId
)
)
} else {
b.append(
summary.copy(
maxPrice = lastSummary.maxPrice,
maxPriceOrderId = lastSummary.maxPriceOrderId,
minPrice = lastSummary.minPrice,
minPriceOrderId = lastSummary.minPriceOrderId
)
)
}
} else {
b.append(
summary.copy(
maxPrice = summary.price,
maxPriceOrderId = summary.order_id,
minPrice = summary.price,
minPriceOrderId = summary.order_id
)
)
}
b
})
}
}
-
我有一个时间序列,列出了几个月交易历史中期货合约的成交价格数据。我希望有一个图表(折线图),显示时间序列中最近4周内每周滴答数据的交易历史(该序列不断更新) X轴将显示周一至周五的日期,图表上任何时候都会有4条单独的线详细说明刻度数据。我已经设法做到这一点,使用一些代码,绘制最后一笔交易的每一天,但我需要的是滴答数据绘图,而不是仅仅一个数据点,每天为每一行。 这是一张Excel图表(!)在我试图用
-
我有一个Spark dataframe,如下所示: 在此数据Frame中,features列是一个稀疏向量。在我的脚本,我必须保存这个DF文件在磁盘上。这样做时,features列被保存为文本列:示例。如您所料,在Spark中再次导入时,该列将保持字符串。如何将列转换回(稀疏)向量格式?
-
我正在使用JFreeChart制作一个条形图与时间。由于某些原因,在这些图表上,x轴上的刻度标签变为“…”偶尔地似乎有足够的空间来扩展标签,但它只是切断了整个事情。我怎样才能解决这个问题。 我试着用图片按钮上传一张图片,但它似乎不起作用。 下面是与我的项目设置相似的代码。奇怪的是,它的行为不同于我的建筑。在我的上面,不是说“侯......”,而是说“......”。请忽略评论和所有其他未编辑的东西
-
Spark streaming以微批量处理数据。 使用RDD并行处理每个间隔数据,每个间隔之间没有任何数据共享。 但我的用例需要在间隔之间共享数据。 > 单词“hadoop”和“spark”与前一个间隔计数的相对计数 所有其他单词的正常字数。 注意:UpdateStateByKey执行有状态处理,但这将对每个记录而不是特定记录应用函数。 间隔-1 输入: 输出: 火花发生3次,但输出应为2(3-1
-
我的理解是Spark 1之间的一个重大变化。x和2。x是从数据帧迁移到采用更新/改进的数据集对象。 但是,在所有Spark 2. x文档中,我看到正在使用,而不是。 所以我问:在Spark 2. x中,我们是否仍在使用,或者Spark人员只是没有更新那里的2. x文档以使用较新的推荐的?
-
使用jfreechart fx渲染带有垂直刻度标签的时间序列图表时,标签意外地与域轴重叠,有时在调整大小时会发生更改。我无法用Swing或纯Java2D重现这一点,如图所示。我欢迎任何指导。