《scala》专题
-
使用dataframe scala创建一个以时间戳为文件名的csv文件
我有一个数据框架,数据如下。 我想将上面的数据帧写入csv文件,其中将使用当前时间戳创建文件名。 但此代码工作不正常。给出以下错误 有没有更好的方法来实现这一点,使用scala和火花?此外,即使我试图创建文件与时间戳代码是创建一个目录与时间戳和在该目录内的csv与数据创建一个随机名称.我怎么能有时间戳文件名到这些csv文件,而不是创建一个目录?
-
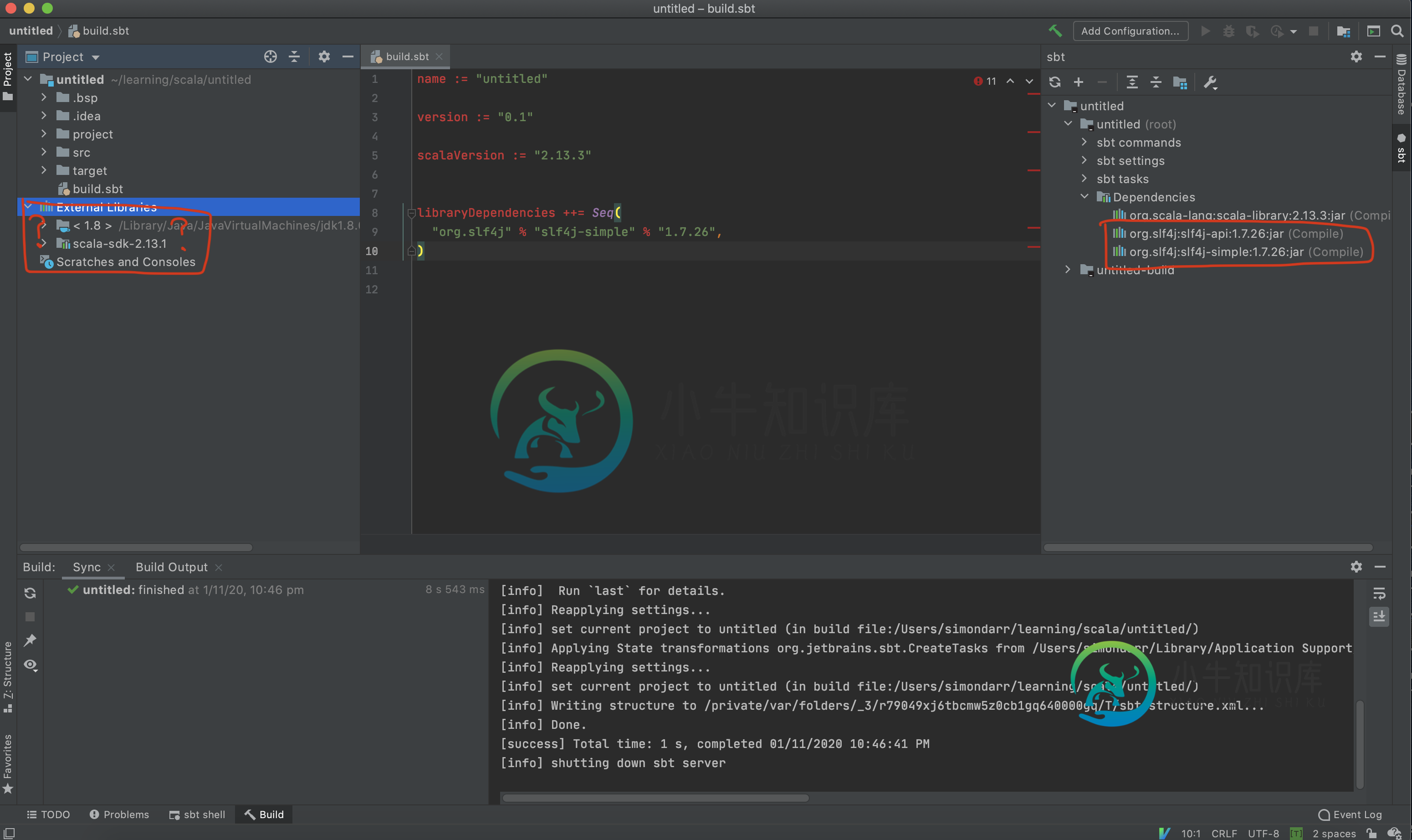 Scala的构建。IntelliJ未识别sbt
Scala的构建。IntelliJ未识别sbt我的身材有问题。未使用IntelliJ(旗舰版2020.2.3)正确提取sbt文件。我使用IntelliJ向导(文件)创建了一个新的Scala sbt项目 sbt工具窗口选择外部依赖项,但我的项目“外部依赖项”根本不包含库,即使在我刷新项目之后。还有我的身材。sbt文件中有很多错误,比如IntelliJ无法正确识别它,但我已经安装了Scala插件,所以我不知道还能做什么? 在这里,您可以看到我已经
-
Spark应用程序如何从DataFrame(Scala)创建CSV文件?
我的下一个问题并不新鲜,但我想了解如何一步一步地解决它。 在Spark应用程序中,我创建了数据帧。我们把它叫做df。Spark版本:2.4.0 如何从这个DataFrame创建文件并将csv文件放入服务器中的特定文件夹? 例如,这段代码正确吗?我注意到有些人使用或来完成这项任务。但我不明白在我的情况下哪一个会更好。 当我尝试使用下一个代码时,它会引发错误: 我以root用户身份运行Spark应用程
-
你怎么写一个数据帧/RDD与自定义分隔符(ctrl-A分隔)文件在火花scala?
我正在处理poc,我需要在其中创建数据帧,然后将其保存为ctrl分隔的文件。下面是我创建中间结果的查询 将结果保存在文本文件中 输出: 它将数据保存为逗号分隔,但我需要将其保存为ctrl-A单独我尝试了选项(“分隔符”、“\u0001”),但它似乎不受dataframe/rdd的支持。 有什么帮助的功能吗?
-
 有没有办法在spark 3.0.1中使用名称不同于part*的scala导出csv或其他文件?
有没有办法在spark 3.0.1中使用名称不同于part*的scala导出csv或其他文件?我用scala在spark中创建了一个二维立方体。数据来自两个不同的数据帧。名称是“borrowersTable”和“loansTable”。它们是使用“createOrReplaceTempView”选项创建的,这样就可以对它们运行sql查询。目标是在两个维度(性别和部门)上创建多维数据集,汇总图书馆的图书借阅总数。使用命令 我创建了具有以下结果的立方体: 然后使用命令 <代码>立方体。写格式(
-
如何在spark SCALA中重命名AWS中的spark数据帧输出文件
我将spark数据帧输出保存为带有分区的scala中的csv文件。我在齐柏林飞艇上就是这样做的。 现在文件保存在预期的分区文件夹结构中。 现在,我的要求是重命名所有零件文件并将其保存在一个目录中。文件名将作为文件夹结构的名称。 例如,我有一个文件保存在文件夹/数据分区=日本/分区年=1971/part-00001-87a61115-92c9-4926-a803-b46315e55a08.c000.
-
将bootstrap.css文件链接到Play framework中的scala.html页面
我有一个bootstrap.css文件位于 C:\Users\comp\Play\u Framework\test1\public\stylesheets\bootstrap.css 我需要将此链接到位于的我的登录页面 C:\用户\comp\Play_Framework\test1\app\视图\cal_login.scala.html 我已经尝试这个在我的超文本标记语言页面 link rel="
-
在火花scalaGroupByKey($"coll")和GroupBy($"coll")之间的区别
当我使用DF的列名作为参数时,与使用和有什么根本区别? 哪一个是省时的,每一个的确切含义是什么?当我通过一些例子时,请有人详细解释一下,但这是令人困惑的。
-
为什么spark 2.2中仍然存在DataFrame,甚至DataSet在scala中也提供了更高的性能?[副本]
DataSet提供了比数据帧最好的性能。DataSet提供编码器和类型安全,但数据帧仍在使用中,是否有任何特定场景仅在该场景中使用数据帧,或者是否有任何功能在数据帧上工作而在数据集中不工作。
-
jongo/jackson在java中反序列化scala.option
为那些像我一样被困的人找到了解决问题的办法!:为了处理用于jackson反序列化的第三方java或scala对象,您可以使用mixin(但需要重新配置jackson映射器或用户模块),也可以简单地创建一个名为MyClassDeserializer的类,该类扩展JsonDeserializer并使用@JsonDeserialize(使用=MyClassDeserializer.class)注释。 例
-
如何使用scala[复制]排列Spark中的行和列
我想从文本文件中获取以下格式: 要将其转换为没有第一行和最后一行的数据帧,我跳过了第一行和最后一行,但随后我变成了一行和onw列中的其余文本如何排列这些行?我还有一个数据框架的模式
-
如何在Spark结构化流媒体中使用Scala Case类映射Kafka源
我尝试在spark中使用结构化流媒体,因为它非常适合我的用例。然而,我似乎找不到将Kafka传入的数据映射到case类的方法。根据官方文件,我可以做到这一点。 mobEventDF有这样一个模式 有没有更好的方法?如何将其直接映射到下面的Scala Case类中?
-
是合理的,扩展AnyVal的Scala Symbol类有什么好处吗?
似乎scala有一个问题。符号是它的两个对象,符号和它所基于的字符串。 为什么不能通过定义Sym来消除这个额外的对象,例如: 诚然,对象分配对性能的影响可能很小,但与那些对Scala有更深入了解的人一起发表的评论将很有启发性。特别是,以上是否通过引用相等提供了有效的映射? 上面简单的“Sym”的另一个优点是,在以地图为中心的应用程序中,有许多字符串键,但字符串命名了许多完全不同的事物,可以定义类型
-
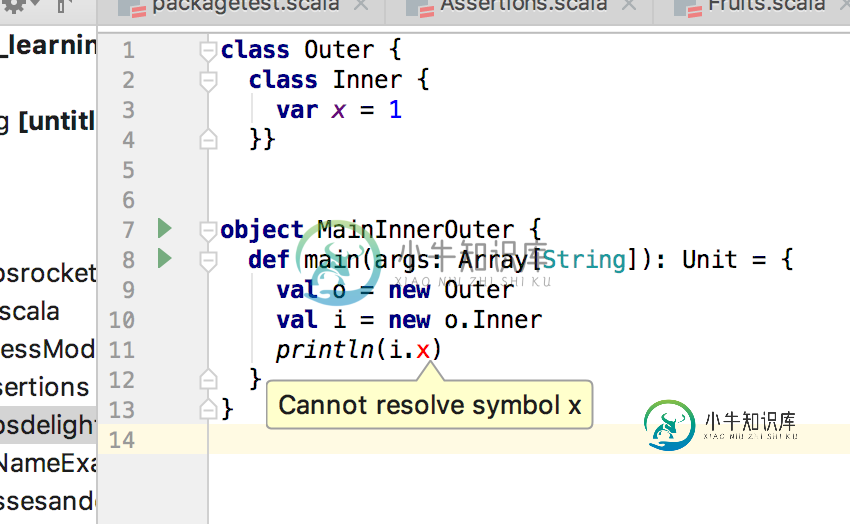 如何在scala中访问内部类元素
如何在scala中访问内部类元素我有一个简单的内部类变量,如何在scala中访问它?
-
如何为Scala Spark ETL设置本地开发环境以在AWS Glue中运行?
我希望能够在我的本地IDE中编写,然后将其部署到AWS Glue作为构建过程的一部分。但是我很难找到构建AWS生成的骨架所需的库。 aws java sdk glue不包含导入的类,我在其他任何地方都找不到这些库。虽然它们一定存在于某个地方,但它们可能只是这个库的Java/Scala端口:aws glue libs AWS的模板scala代码: 以及构建。sbt我已经开始为本地构建做准备: AWS