《scala》专题
-
AspectJ编译时编织与Scala
是否有可能拥有一个Scala Maven项目,并在Scala类中编译时编织AspectJ方面? 我已经能够使加载时编织工作,但到目前为止没有成功的编译时。
-
Scala对象的序列化
我正在遵循scala对象序列化的基本示例。但是,当运行下面的单元测试时 我有个例外: org.scalatest.assertions$assertionshelper java.io.NotSerializableException:在java.io.ObjectOutputStream.WriteObject0(ObjectOutputStream.java:1184)在java.io.Obj
-
当联接列不同时,使用Spark Scala动态联接数据流
在scala spark中连接不同数据帧时动态选择多列 从上面的链接,我能够让连接表达式工作,但如果列名不同,我们不能使用Seq(columns)而需要动态地连接它。这里的left_ds和right_ds是我想加入的数据流。下面我想要连接列id=acc_id和“acc_no=number”
-
在Scala Spark中连接不同数据帧时动态选择多列
我有两个火花数据帧和。在连接这两个数据流的同时,是否有一种方法可以动态地选择输出列?在内部连接的情况下,下面的定义输出来自df1和df2的所有列。 DfJoinResult.Schema(): 我查看了等选项,但它不允许从两个DF中选择列。有没有一种方法可以动态地传递列以及我们想要在我的中从中选择的数据帧详细信息?我使用的是Spark2.2.0。
-
Spark:数据帧聚合(Scala)
我正在考虑将dataset1分解为每个“T”类型的多个记录,然后与DataSet2连接。但是你能给我一个更好的方法,如果数据集变大了,它不会影响性能吗?
-
在Scala中使用Spark数据集执行类型化联接
我喜欢Spark数据集,因为它们在编译时会给我带来分析错误和语法错误,还允许我使用getter而不是硬编码的名称/数字。大多数计算都可以通过DataSet的高级API完成。例如,通过访问Dataset类型对象的执行agg、select、sum、avg、map、filter或groupBy操作要比使用RDD行的数据字段简单得多。 但是其中缺少join操作,我读到我可以像这样执行join操作 我使用的
-
使用scala spark中的第一列连接两个数据集
-
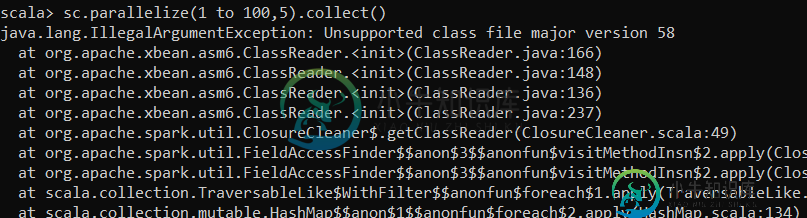 在scala[closed]中使用sc.parallelize()
在scala[closed]中使用sc.parallelize()嗨,我是scala的新手,正在尝试使用sc.parallalize(),结果遇到了所附的错误。
-
找不到带有Scala编解码器的Datastax Cassandra驱动程序
DataStax驱动程序Cassandra版本:3.3.2 Scala版本:2.12.4 我正在为Cassandra的datastax java驱动程序中的mappingmanager创建一个scala包装器。 null 为什么它总是从Scala.Collection.Mutable.ArrayBuffer“转换”?解决这个问题的方法是什么?
-
如何并行运行Scalaz任务
我有一大堆Scalaz任务。创建方式如下: 我希望这些任务并行运行。以随机顺序打印数字,不要花5秒钟(每个任务有50个任务和100毫升睡眠)。 但是,很明显,每个任务需要100毫秒,所有任务都需要5秒钟,并且创建的列表是有序的。 如何并行运行它们?任务在哪里运行线程?
-
scala中的逆变
我是Scala的新手。我在想整个逆变关系是如何运作的。我了解协方差和不变量的概念,我也知道如何在实践中实现它们。我还理解了逆变(协方差的反向)的概念,以及它是如何在Scala中的Function1特性中实现的。它为您提供了一种抽象,而无需为不同的类重新定义Function1实现。但是,我还是不完全明白,奇怪吗?现在,我就快到了…我如何用逆变来解决下面的问题: 上面的例子摘自http://blog.
-
将Eithers与Scala“for”语法一起使用
-
Kafka Streams如何在scala中从kafka消息中获取TimeStamp
我正在运行一个简单的Kafka streams应用程序,它将使用Node JS记录的信息带到一个Kafka主题。 还需要注意的是,时间戳只是一个数字,表示自1970年6月以来的秒数。 我使用scala中的Kafka流来使用这些数据。 例如。 然而,我不确定如何将时间戳(我从nodeJS发送的)提取到这个流中。 例如,如果我尝试做这样的事情 这会导致错误“无法解析符号流”。我在想我该怎么解决这个问题
-
什么是java/scalakafka流相当于KSQL加入WHERE子句?
假设我有两个Kafka流(Kafka流scala库,版本2.2.0): 以及他们的加入: KSQL中WHERE子句的等价物是什么?(参见最新订单流)了解流API?使用stream3是个好主意。滤器这种方法的效率是否与KSQL创建的流相同?
-
Java/Scala Kafka制作人不向主题发送消息
我在向我的Kafka主题发送序列化XML时遇到问题。每当我运行我的代码时,我都不会收到任何异常或错误消息,但我仍然无法在Kafka主题中看到我的任何消息。 我的Kafka制作人设置如下: 当我运行代码时,我得到: 知道怎么做吗?提前谢谢!