《xpath》专题
-
使用布尔值与Python lxml执行不同的XPath表达式
我试图使用python脚本和lxml从网站上获取天气数据。风速数据将被拉出并附加到一个列表中,以便以后进行操作。我可以很好地获得我需要的信息,当它被格式化时: 我当前的代码使用Python检查span类是否等同于“nowind”,然后执行if和else语句,但只执行else语句。我当前的代码如下所示: 我想用一个XPath表达式来解决这个问题,该表达式将产生一个布尔值,而不是我当前的解决方案。如有
-
C#Selenium函数获取用户输入并单击包含“ ”的xpath文本?
我正在编写一个函数,它应该接受一个字符串,并单击包含匹配该字符串的文本的html元素。 但是在某些情况下,元素的文本包含特殊字符 ,我的函数无法找到元素。
-
用br从文本中查找xpath
我有这个html代码 任何人都知道如何从文本中获得div,如果可能的话,不要使用contains,因为它们不准确。 谢谢你。
-
包含文本的div的Xpath
我正在使用selenium在html页面上执行测试。我只能使用xpath来定位元素。我试图创建一个xpath,它允许我定位所有包含文本的div,这样我就可以用findElements保留这些WebElement的引用,不管它是什么,只要它不是空的。所以我有了这个xpath: //div[5]/div/div[2]
-
用什么XPath1表达式对多行文本进行不区分大小写的匹配?
我有一些html标记,其中包含许多标签,如下所示: 我试图基于文本字符串“一个二个三个四”访问selenium测试中的元素。我希望能够匹配以上两个例子。
-
使用XPath,如何在没有前面的文本的情况下在标记处获得精确的匹配?
第二个项包含xpath表达式应该忽略的项,因为它在下拉项div中的span节点上方包含一个文本。 我尝试了很多XPath表达式,我开始认为只有使用XPath我才能选择我想要的项。我知道,如果我在编程中连接两个或多个XPaths(例如C#或Java),并用连字符给出一个子字符串,最后找到我需要的索引,我将能够找到所需的节点,但考虑到我将处理的信息量,它不可能是执行的。我们的想法是只使用xpath,也
-
XPATH为HTML标记编写压缩文本前后的空格,即空格、text空格?
null
-
Selenium XPATH如何从input id标记下面的Span标记获取文本
我有以下html片段: 我已经用以下XPath找到了该元素: 谢谢,里亚斯
-
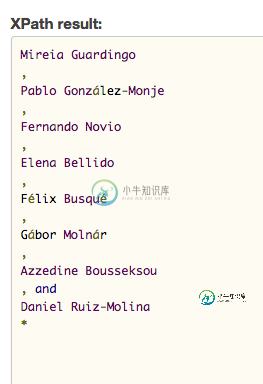 无效的选择器错误:使用xpath和Selenium从多个跨中Webscraping不同类型的文本
无效的选择器错误:使用xpath和Selenium从多个跨中Webscraping不同类型的文本我正试图以以下格式刮出一个逗号分隔的作者列表[重要]: 第一个最后,第一个最后,第一个最后*,第一个最后 我正在讨论的html部分非常复杂,但是我已经成功地测试了一个xpath,该xpath生成了我想要的文本和符号。 但是,当我在python代码中使用该公式时,我会得到一个错误。
-
用于div标记的Xpath排除span标记并返回文本
下面的HTML代码需要xpath 仅供参考:xpath将具有排除邮政编码的div text(),以便返回剩余的div和span文本。有时postalCode不在这个div标记中。因此,如果它存在,跳过它,如果不返回整个div标记文本。
-
PHP DOM/XPath检查元素span类值
在curl请求中,我有一个html表,其结构如下所示。现在,我只想提取包含带有空类的span元素的表行,而不是包含class=“subcomponent”的表行。我成功地尝试了Xpath来查找带有空类的元素,但是如何获取整个,甚至是包含Version和partnumber的特定节点。提前谢了。 我的PHP代码
-
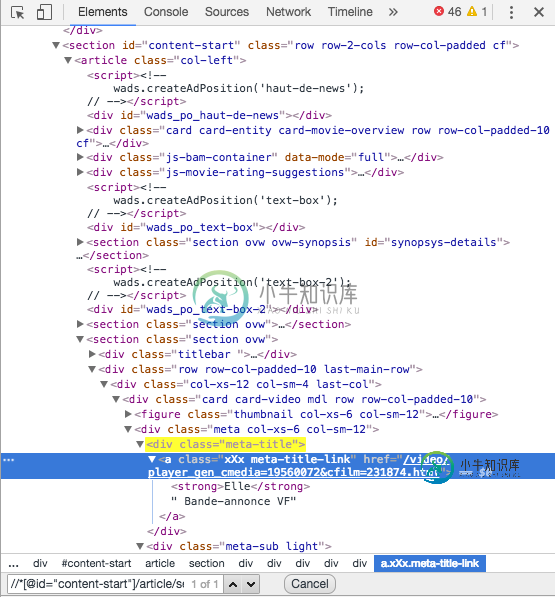 使用xpath(python3)的href属性为空
使用xpath(python3)的href属性为空使用python3中的chrome和xpath,我试图提取这个web页面上“href”属性的值。“href”属性包含到我感兴趣的电影预告片(法语中的“bande-annonce”)的链接。 首先,使用xpath,“a”标记似乎是“span”标记。实际上,使用以下代码: 我得到这样的结果:
-
XPath:从子节点获取父节点
-
使用text()检索包含的xpath文本
上面的XPath查询捕获了我正在查看的特定部分中的所有文本,这很棒。但是,我只需要知道testuser是否在那个部分。
-
使用xpath或css查询从span检索文本
我需要从以下span元素中检索文本,而不需要将其拆分为文本部分。 我想检索一个没有破损的文本块。我正在使用这个xpath测试器http://www.freeformatter.com/xpath-tester.html