
使用xpath(python3)的href属性为空

使用python3中的chrome和xpath,我试图提取这个web页面上“href”属性的值。“href”属性包含到我感兴趣的电影预告片(法语中的“bande-annonce”)的链接。
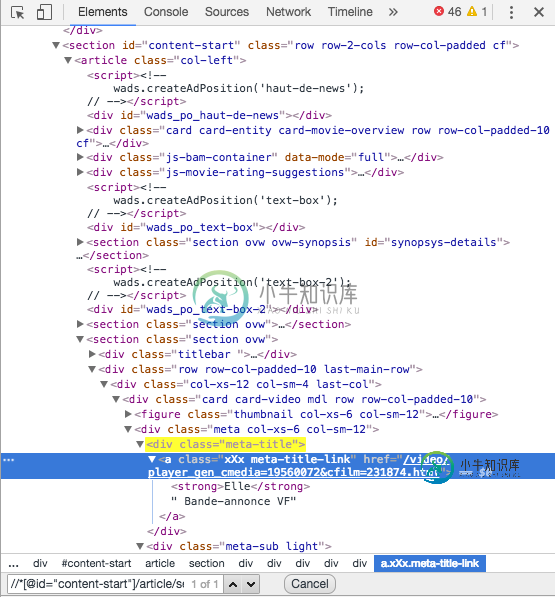
首先,使用xpath,“a”标记似乎是“span”标记。实际上,使用以下代码:
response_main=urllib.request.urlopen("http://www.allocine.fr/film/fichefilm_gen_cfilm=231874.html")
htmlparser = etree.HTMLParser()
tree_main = etree.parse(response_main, htmlparser)
tree_main.xpath('//*[@id=\"content-start\"]/article/section[3]/div[2]/div/div/div/div[1]/*')
我得到这样的结果:
[<Element span at 0x111f70c08>]
response_main=urllib.request.urlopen("http://www.allocine.fr/film/fichefilm_gen_cfilm=231874.html")
htmlparser = etree.HTMLParser()
tree_main = etree.parse(response_main, htmlparser)
tree_main.xpath('//*[@id=\"content-start\"]/article/section[3]/div[2]/div/div/div/div[1]/span/@href')
tree_main.xpath('//*[@id=\"content-start\"]/article/section[3]/div[2]/div/div/div/div[1]/span/@*')
['ACrL3ZACrpZGVvL3BsYXllcl9nZW5fY21lZGlhPTE5NTYwMDcyJmNmaWxtPTIzMTg3NC5odG1s meta-title-link']
共有1个答案

使用JavaScript动态生成的必需链接。使用urllib.request,您只能获得初始的HTML页面源代码,而在执行所有JavaScript之后,您需要HTML。
您可以使用Selenium+ChromeDriver来获取动态生成的内容:
from selenium import webdriver as web
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait as wait
driver = web.Chrome("/path/to/chromedriver")
driver.get("http://www.allocine.fr/film/fichefilm_gen_cfilm=231874.html")
link = wait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//div[@class='meta-title']/a[@class='xXx meta-title-link']")))
print(link.get_attribute('href'))
-
XPath正在firebug中进行测试,我已经尝试了、,到目前为止还没有结果
-
我需要点击下面的href元素,它存在于类似的href元素中。 有人能给我提供xpath来点击上面的href链接吗?提前谢谢你的帮助
-
我已经掌握了XPath的基本知识,但在确定以下内容是否可以在使用XPath的C代码中实现时遇到了一些困难(或者我是否需要将其转移到其他代码中,正如我目前所做的那样)。 我有一个XML文档,它由以下结构组成: 其中有多个设置参数值。现在我需要做的只是检索那些包含name属性某些值的setParameter节点。我可能有这些值的可能匹配列表,但它们不会是完全匹配,它们将是节点的name属性必须包含的值
-
检索给定节点resp的所有属性名(而不是属性值!)的Xpath表达式看起来如何。xml标签? 假设以下XML文档: Xpath//title/@*会选择“eng,fr,easyreading”,但哪个Xpath会选择“lang,lang,type”?
-
我是Selenium的新手,需要能够使用属性和文本对以下元素进行xpath。 我正在使用 但我还需要它带有属性,以便将其缩小到单个元素。
-
问题内容: 试图在页面上找到链接。 我的正则表达式是: 但似乎失败了 我该如何更改我的正则表达式以处理未置于a标签首位的href? 问题答案: 可靠的HTML正则表达式很困难。这是使用DOM的方法: 上面将找到并输出字符串中所有元素的“outerHTML”。 要 获取 节点的所有文本值,请执行以下操作 要 检查 是否属性存在,你可以做 为了 获得 该你做的属性 要 更改 的属性,你会怎么做 要 删