《xpath》专题
-
如何使用xpath解析嵌套的html标签
这是我的示例html代码。 使用HtmlXpath Selector我需要解析html文件。 def parse(自己,响应):edxData=HtmlXpath Selector(响应) 首先,我需要获取所有包含 edxData.xpath 的标记('//h2[@class = “标题课程-标题”]') 在该标签内,我需要检查标签值。 然后需要解析带有类名字幕课程 - 字幕复制 - 详细信息的d
-
Scrapy-使用xPathSelector提取嵌套的“img src”
我对使用Scrapy或python进行这方面的工作比较陌生。我想从几个不同的链接中提取,但我在使用HTMLXPathSelector表达式(语法)时遇到了问题。我已经查看了大量的文档以获得适当的语法,但还没有找到解决方案。 下面是一个链接示例,我试图从中提取“img src”: 我正试图从中提取img src url的页面 我想我已经弄清楚了x.select语句的语法,但由于我对这种语法/方法是新
-
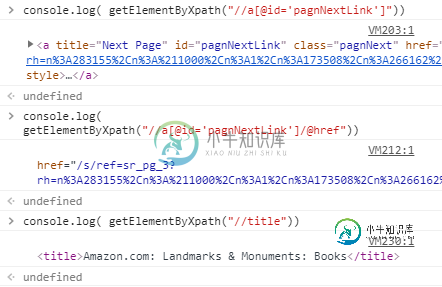 使用lxml,xpath和css选择器的Python脚本也返回空列表
使用lxml,xpath和css选择器的Python脚本也返回空列表我试图使用xpath和lxml从html标签中抓取下一页的href链接。但是xpath返回空列表,而它是单独测试的,它似乎可以工作。 我尝试了css选择器和xpath,它们都返回空列表。 代码返回空值,而xpath似乎工作正常。 我在这里尝试了两种方法,但似乎都不起作用。 我正在使用一个代理服务器,用于访问链接,它似乎可以工作,因为“文档”变量正被HTML内容填充。我已经检查了链接,我在正确的页面
-
Selenium驱动程序按钮Xpath
按钮超文本标记语言代码我将如何编写命令来单击按钮的xpath? Xpath是 是吗
-
如何在不考虑div索引的情况下识别XPath?
我正在编写一个从站点中抓取信息的python代码,但我必须首先去掉一些cookies弹出窗口。要单击右侧按钮,我需要它们的XPath(据我所知)。问题是XPath的一部分每次都发生变化,我不知道如何找到它们,因为它们实际上没有任何属性,比如ID之类的。 这是按钮的HTML: 这是我现在使用的命令: 这是XPath: 变量每次都变,所以我改变了14。
-
在python中使用lxml和xpath获取空列表
所以我有这个代码,它应该得到亚马逊上任何商品的价格。然而,我得到的不是价格,而是一个空清单。 这以前对我有用。我将感谢任何帮助。提前感谢。
-
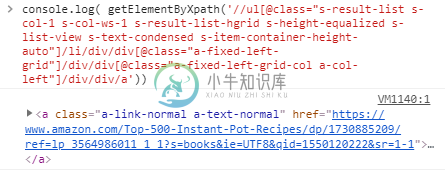 使用lxml的Python脚本,xpath返回空列表
使用lxml的Python脚本,xpath返回空列表我尝试使用xpath和lxml从html标记中提取href链接。但是xpath返回空列表,而它是单独测试的,并且似乎可以工作。 代码返回空值,而xpath似乎工作正常。 我使用一个代理服务器来访问链接,它似乎可以工作,因为“doc”变量正在填充html内容。我已经检查了这些链接,现在正处于获取此xpath的正确页面上。 这是我试图从中获取数据的链接:https://www.amazon.com/s
-
lxml xpath返回一个空列表
如果我跑: 我会得到一张空名单。我猜它与名称空间有关,但我不知道如何修复它。
-
Xpath不返回值lxml Python
我正在做一个项目,我试图让lxml从不同网页上的不同表格中提取股票数据。当我运行程序试图打印我试图提取的值时,我得到了空括号 以下是我称之为的方式: 以及: 我已经从XPath中删除了tbody,就像一些类似的问题所建议的那样。任何帮助或建议将不胜感激,谢谢!
-
Python lxml xpath返回带有文本的列表中的转义字符
在上周之前,我使用Python的经验非常局限于我们网络上的大型数据库文件,突然间,我开始尝试从html表中提取信息。 经过大量阅读,我选择在Python2.7中使用lxml和xpath来检索相关数据。我使用以下代码检索了一个字段: 产生了以下清单: 我认识到CR/LF和制表符转义字符,我想知道如何避免它们?
-
有人能建议我为您创建动态xpath吗https://jpetstore.cfapps.io/catalog/categories/FISH
在这里,我能够创建动态xpath驱动程序。findElement(By.xpath(“//div[@id='Catalog']//parent::td//previous sibling::td//a//following::td//a”))。单击();驾驶员findElement(By.xpath(“//div[@id='Catalog']//parent::a//following::a[co
-
Selenium从XPath返回span元素的空列表
我正在尝试通过检查网页并识别我要提取的内容的XPath来刮取一些web元素。对于某些元素,我得到了预期的结果,而对于其他元素,我没有得到预期的结果。请参阅下面的可复制示例: 上载我要分析的页面: 然后,我使用XPath语言标识想要查看的元素的路径: 为了提取我希望的值,我现在在文章列表中查找元素time和span。最终的结果是一个时间表列表,但也是一个空的阅读时间列表。我尝试使用不同的版本而不是,
-
Selenium WebDriver:使用XPath单击SVG中的元素
我有一个带有几个圆形和矩形元素的SVG对象。使用webdriver,我可以单击主svg对象,但不能单击其中的任何元素。问题似乎只出在点击(或任何鼠标交互)上,因为我可以使用getAttribute()返回宽度、ID、x/y、text等值,用于它下面的任何内容。 下面是HTML的一个示例: 以及WebDriver试图右键单击矩形元素(失败)的示例: 但这会起作用,并返回一个值: 当WebDriver
-
在XPath中。//和//*有什么区别?
只需在Xpath中添加即可--它突出显示--各种页面元素----它表示什么? 下面是用于Gmail密码字段的XPaths。的意义是什么? >
-
在Selenium WebDriver测试中使用页面对象时定义Xpath时出现问题
硒新手在这里。。。我正在尝试创建我的第一个测试框架。 考试网站:https://www.phptravels.net/ 测试用例: 打开浏览器,进入网页 页面加载完成后,点击我的账户- 我在我的页面对象类中使用了xpath,脚本将只运行到启动网页为止。它无法单击登录链接。 我已经尝试包含一个隐式等待,假设加载页面所花费的时间比平常长。即便如此,问题依然存在。 你能帮我理解什么是正确的xpath吗?