
使用lxml,xpath和css选择器的Python脚本也返回空列表

我试图使用xpath和lxml从html标签中抓取下一页的href链接。但是xpath返回空列表,而它是单独测试的,它似乎可以工作。
我尝试了css选择器和xpath,它们都返回空列表。
代码返回空值,而xpath似乎工作正常。
import sys
import time
import urllib.request
import random
from lxml import html
import lxml.html
import csv,os,json
import requests
from time import sleep
from lxml import etree
username = 'username'
password = 'password'
port = port
session_id = random.random()
super_proxy_url = ('http://%s-session-%s:%s@zproxy.lum-superproxy.io:%d' %(username, session_id, password, port))
proxy_handler = urllib.request.ProxyHandler({
'http': super_proxy_url,
'https': super_proxy_url,})
opener = urllib.request.build_opener(proxy_handler)
opener.addheaders = \[('User-Agent', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36')]
print('Performing request')
page = self.opener.open("https://www.amazon.com/s/ref=lp_3564986011_pg_2/133-0918882-0523213?rh=n%3A283155%2Cn%3A%211000%2Cn%3A1%2Cn%3A173508%2Cn%3A266162%2Cn%3A3564986011&page=2&ie=UTF8&qid=1550294588").read()
pageR = requests.get("https://www.amazon.com/s/ref=lp_3564986011_pg_2/133-0918882-0523213?rh=n%3A283155%2Cn%3A%211000%2Cn%3A1%2Cn%3A173508%2Cn%3A266162%2Cn%3A3564986011&page=2&ie=UTF8&qid=1550294588",headers={"User-Agent":"Mozilla/5.0"})
doc=html.fromstring(str(pageR))
html = lxml.html.fromstring(str(page))
links = html.cssselect('#pagnNextLink')
for link in links:
print(link.attrib['href'])
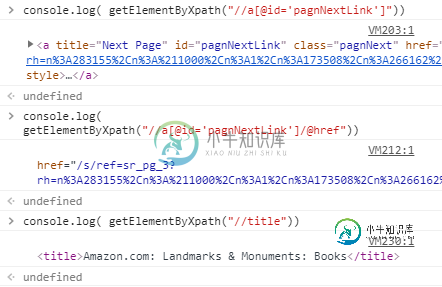
linkRef = doc.xpath("//a[@id='pagnNextLink']/@href")
print(linkRef)
for post in linkRef:
link="https://www.amazon.com%s" % post
我在这里尝试了两种方法,但似乎都不起作用。
我正在使用一个代理服务器,用于访问链接,它似乎可以工作,因为“文档”变量正被HTML内容填充。我已经检查了链接,我在正确的页面上获取这个xpath/csslink。
共有1个答案

更有经验的人可能会给你更好的建议与您的设置,所以我将简单地指出我所经历的:
当我使用请求时,我有时得到链接,有时没有。当没有时,响应表明它正在检查我不是机器人,并确保我的浏览器允许cookie。
使用硒,我在测试中得到了可靠的结果,尽管这可能不够快,或者出于其他原因是你的选择。
from selenium import webdriver
d = webdriver.Chrome()
url = 'https://www.amazon.com/s/ref=lp_3564986011_pg_2/133-0918882-0523213?rh=n%3A283155%2Cn%3A%211000%2Cn%3A1%2Cn%3A173508%2Cn%3A266162%2Cn%3A3564986011&page=2&ie=UTF8&qid=1550294588'
d.get(url)
link = d.find_element_by_id('pagnNextLink').get_attribute('href')
print(link)
带代理的Selenium(Firefox):
在Python中使用代理运行Selenium Webdriver
硒与代理(Chrome)-这里很好地覆盖:
https://stackoverflow.com/a/11821751/6241235
-
我尝试使用xpath和lxml从html标记中提取href链接。但是xpath返回空列表,而它是单独测试的,并且似乎可以工作。 代码返回空值,而xpath似乎工作正常。 我使用一个代理服务器来访问链接,它似乎可以工作,因为“doc”变量正在填充html内容。我已经检查了这些链接,现在正处于获取此xpath的正确页面上。 这是我试图从中获取数据的链接:https://www.amazon.com/s
-
如果我跑: 我会得到一张空名单。我猜它与名称空间有关,但我不知道如何修复它。
-
我正在做一个项目,我试图让lxml从不同网页上的不同表格中提取股票数据。当我运行程序试图打印我试图提取的值时,我得到了空括号 以下是我称之为的方式: 以及: 我已经从XPath中删除了tbody,就像一些类似的问题所建议的那样。任何帮助或建议将不胜感激,谢谢!
-
所以我有这个代码,它应该得到亚马逊上任何商品的价格。然而,我得到的不是价格,而是一个空清单。 这以前对我有用。我将感谢任何帮助。提前感谢。
-
在上周之前,我使用Python的经验非常局限于我们网络上的大型数据库文件,突然间,我开始尝试从html表中提取信息。 经过大量阅读,我选择在Python2.7中使用lxml和xpath来检索相关数据。我使用以下代码检索了一个字段: 产生了以下清单: 我认识到CR/LF和制表符转义字符,我想知道如何避免它们?
-
问题内容: 我在selenium测试中有以下xpath语句: 它达到了我想要的,但是我的测试在IE6中非常缓慢。有人知道我将如何做与CSS选择器相同的选择器吗?我想我了解如何执行上述操作,但text()=“ IPODate”部分除外。 以下是我要从中选择的表格示例: ....很多很多行 …还有很多行… 在此示例中,只有一行具有IPODate单元。 问题答案: CSS定位器用于其中包含文本IPODa