《xpath》专题
-
WebElements列表中的相对Xpath
在我收集了一个webelements列表之后,是否可以使用相对的xpath?如果是的话,最好的方法是什么? 这就是我所拥有的: list rows包含具有多列的单个行,我正在尝试找到在列中包含特定名称的行。在for循环中,我试图使用一个相对的xpath来查找一个元素,这可能吗?还是需要提供我用来查找行的整个xpath以及用于单个div的附加xpath? 我不能保证列的顺序,这就是为什么我必须这样做
-
无法为浏览器中的Pertical链接编写xpath
但是当我执行上面的脚本时,我会得到以下错误: Message:StaleElementReferenceException:Message:Element不再附加到DOM StackTrace:at fxdriver.cache.getElementat(资源://fxdriver/modules/web-element-cache.js:9351)at utils.getElementat(文件
-
尝试使用Apache Tika和XPath获取属性值
我尝试了以下不同的XPath:
-
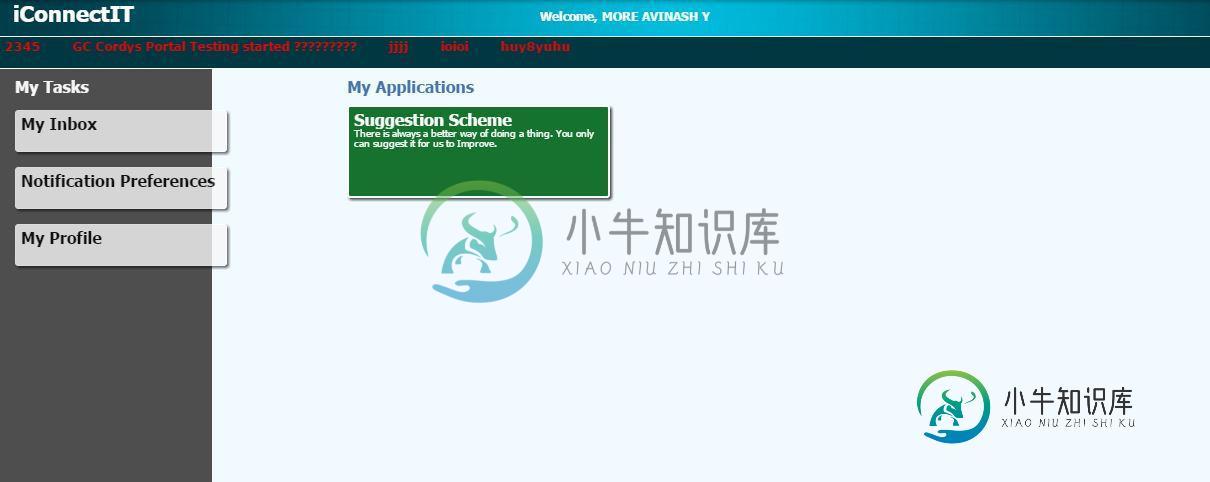 在Selenium3中使用xpath定位元素时出错
在Selenium3中使用xpath定位元素时出错我试图使用单击一个链接(看起来像是一个选项卡按钮),但出现错误。 这是片段: 我尝试了以下代码: 这是一个错误: 在屏幕截图中,你可以看到,我正在尝试点击建议方案按钮链接
-
Xpath查询-使用importXML函数Google Sheets for Gqueues页面,其中Xpath有@id字段
我是一个长期的读者,第一次海报。非常感谢过去所有的帮助。 我是Xpath和Google sheets importXML函数的新手。我很难正确使用Xpath查询语法。我希望使用importXML函数将已发布的Gqueues任务列表中的值导入到Google Sheets电子表格中。例如,第一个列表项是“为260 O'Farrell街发送合同”。我很难正确地编写Xpath,并且在Google Shee
-
XPath的function-available():为什么它的结果会随着样式表中的位置而变化,以及如何使用它来保护新的
在Java XSLT扩展(适用于Saxon 9.1.0.8)中,我编写了一个功能,首先创建一个新对象并在其上调用实例方法(在XSLT 1.0样式表中)。以下是一个显示出相同问题的缩短版本: 问题: > 我想用保护调用,但它似乎返回不同的结果,这取决于在样式表中调用它的位置(=而不是函数本身)。 结果是,使用会更改的行为:在没有(即作为)的情况下,它会按预期工作,而使用调用这是什么原因(既然这两者似
-
请放心,xpath不会响应xml值
我无法从resultDesc中找到文本: 我已经尝试了与命名空间,但我一直得到: 实际反应是: 我尝试过一些链接:https://github.com/rest-assured/rest-assured/wiki/Usage#xml-名称空间 是的,下面的内容可能有用,但我真的很感激能够理解手头的这个问题吗? https://stackoverflow.com/questions/28298851
-
无法使用带有Selenium/testNG的xpath节点获取yt频道名称
我的任务是打开浏览器,转到YT,输入搜索词“qtp”,单击“搜索”按钮。在结果页面上,我想获取频道名称。为了实现这一点,我使用Firebug应用程序来获取第1个3通道名称的以下路径: 当我使用Selenium/testNG执行以下代码时,我捕获了异常,该异常状态为“未找到元素”。我仅使用Selenium(没有TestNG)尝试了类似的代码,但仍然不起作用。使用WebDriver进行了尝试,仍然不起
-
Spring int xml:带节点函数的xpath表达式错误
我使用XMLSpy编写了以下XPath来确定最长字符串长度,它在XMLSpy中工作: 但是当我在spring integration中将相同的字符串放入xpath-expression时,它会出错: org.springframework.beans.factory.BeanCreationException:创建名为xpath MaxLengthExceptionMsg的bean时出错:bean
-
Xpath在camel路由中不工作
我的骆驼路线
-
Selenium WebDriver查找对象文本。xpath表达式的结果错误为:[object Text]。它应该是一个元素
我正在使用Selenium来验证网页中是否存在某些文本。这就是html的样子。 我能够识别该文本的唯一方法是通过XPath。 我无法使用常规的方法来标识这个元素,因为它返回的是对象文本而不是元素。 这是我得到的错误: 对此我们非常感谢您的帮助。
-
XPath-前一个同级包含一个元素检查
我有以下从一个网页简化的HTML... 需要以下XPath选择条件... col-md-3 div内的输入标记,该标记紧接在包含class=manditional的span的col-md-3 div之后 输入标记不应隐藏 上面HTML中的以下元素与搜索条件匹配 (请注意,ID中的数值是动态分配的,在搜索文档时我不会知道。) 在添加任何前一种兄弟检查之前,这是我的....
-
Selenium IDE/Xpath验证复选框仅当元素的标签包含特定文本时才选中
我正在寻找一些关于如何编写Xpath查询以验证特定复选框是否被选中的指导(嵌套在panel-body div中的div是复选框)。我试图做的是确保包含文本“evaluations”的相应标签的checkbox div包含类“Checked”。以下是我的HTML: 下面是我的XPath: 问题是,即使该框未选中,我的测试用例仍然通过,这表明我的xpath正在抓取其他元素。panel-body div
-
XPath中的文档结尾
我正试图解决这个问题,当需要使用XPath检测HTML文档的结尾时,我卡住了。 HTML为: 当时我的XPath是 但它无法检测到“title 4”,因为最后一个“div”没有“follows-sibling::h2”。只有文档的结尾是我无法使用XPath检测到的。 我需要处理'div'在'h2'和结尾之间的情况。 使用“preperate-sibling::h2[position()=last(
-
在DIV中获取Background-image属性的Xpath
可以使用什么Xpath来获取ID在(selenium webdriver)中提到的DIV标记的background-image CSS属性? 例如:(div id=“abc”,style=“width:538px!重要;height:242px!重要;background-image:url(http://test.com/images/abc.png);position:relative;bac