《tensorflow》专题
-
Keras tensorflow P100:cudaErrorNotSupported=71错误
抱歉如果这已经在其他地方报道过,我已经找了很长时间了,但没有成功。 使用P100 GPGPU使用keras tensorflow运行简单的mnist示例(可在github
-
Tensorflow:如何使用tf绘制小批量。火车来自cifar10的批次?
我正在尝试从cifar10二进制文件中绘制小批量。当实现下面显示的代码时(请参见[源代码]),机器(python 3.6)会不断显示消息(请参见[控制台])并停止。 有人能告诉我我的源代码有什么问题吗? 另外,我是tensorflow的新手。。 [源代码]-------------------------------------------------------------将tensorflow
-
有没有办法抑制TensorFlow打印的消息?
我认为这些信息在开始的时候真的很重要,但是后来就没有用了。它实际上使读取和调试的情况变得更糟。 I tensorflow/流执行器/dso加载器。cc:128]已成功打开CUDA库libcublas。所以8.0本地I tensorflow/流执行器/dso加载器。抄送:119]无法打开CUDA库libcudnn。所以LD_库路径:I tensorflow/stream_executor/cuda/
-
tensorflow和火炬。cuda可以找到GPU,但只有Keras找不到
我试过如何检查keras是否使用了tensorflow的gpu版本?答复但我只认出keras没有看到GPU。 我重新安装了整个需求,包括tensorflow gpu、keras模块,甚至CUDA。 我用的是Jupyter remote ipython。 下面的列表是我安装的模块版本 我检查了以下内容: 结果: =============已添加========== 此外,我还了解了如何从python
-
Tensorflow在GPT-2程序中未充分利用GPU
我正在运行大型模型(774M)的GPT-2代码。它用于通过交互式_条件_样本生成文本样本。林克:这里 因此,我给出了一个输入文件,其中包含自动选择生成输出的提示。此输出也会自动复制到文件中。简而言之,我不是在训练它,而是在使用模型生成文本。而且,我使用的是一个GPU。 我在这方面面临的问题是,代码没有充分利用GPU。 通过使用NVIDIASMI命令,我可以看到下图 https://imgur.co
-
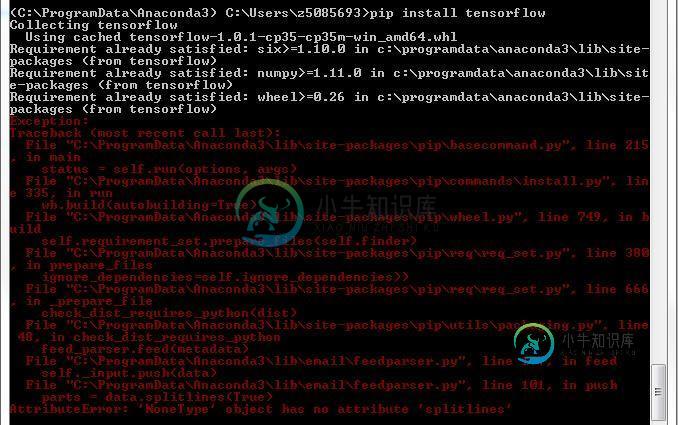 在windows中使用Pip Python 3.5 anaconda安装tensorflow
在windows中使用Pip Python 3.5 anaconda安装tensorflow我正在尝试在Windows 7 64位计算机上安装Tensorslow。 我已经用Python 3.5安装了Anaconda。 在那之后,我做了 这是成功的 成功完成 错误 我不能像安装其他软件包一样安装Tensorflow。我错过了什么基本的东西吗?
-
如何确保Keras使用带有tensorflow后端的GPU?
我已经在纸质空间云架构体系上创建了虚拟笔记本,后端有Tensorflow GPU P5000虚拟实例。当我开始训练我的网络时,它比我的MacBook Pro用纯CPU运行时引擎慢2倍。如何确保Keras NN在训练过程中使用GPU而不是CPU? 请在下面找到我的代码:
-
我无法导入tensorflow gpu
我已经成功地用安装了tensorflow,一切正常。 我也可以成功地用安装tenstorflow-gpu,但是我不能在我的python脚本中导入它: 我已经安装了CUDA v9。0并运行windows 10
-
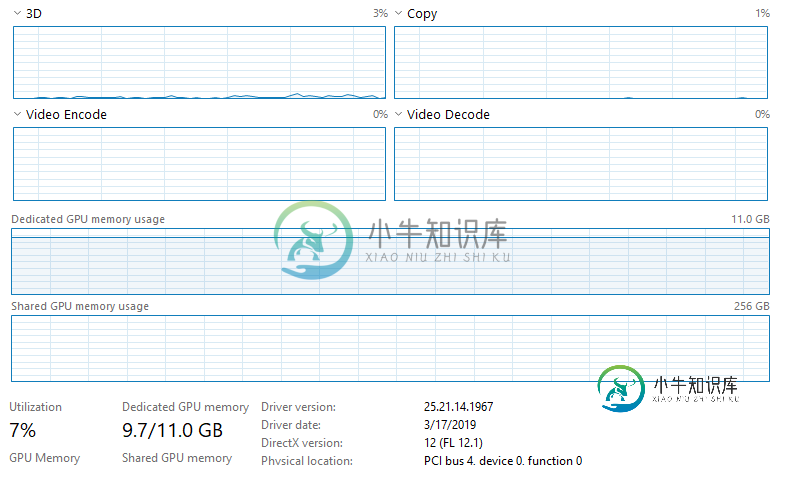 使用Keras和Tensorflow的NVIDIA GPU使用率低
使用Keras和Tensorflow的NVIDIA GPU使用率低请注意,CPU没有被利用,任务管理器上的任何其他内容都表明任何东西都没有被充分利用。我没有以太网连接,并且连接到Wifi(我不认为这会影响任何事情,但我不确定Jupyter是否会影响Wifi,因为它是通过web浏览器运行的)。我正在培训大量数据(~128GB),这些数据都加载到RAM(512GB)中。我运行的模型是一个完全卷积的神经网络(基本上是一个U型网络结构),具有566290个可训练参数。到
-
如何检查keras tensorflow后端是GPU还是CPU版本?[副本]
我知道在安装tensorflow时,您可以安装GPU或CPU版本。如何检查安装了哪一个(我使用linux)。 如果安装了GPU版本,如果GPU不可用,它会自动在CPU上运行吗?如果GPU可用,是否需要设置特定的字段或值来确保它在GPU上运行?
-
使用TensorFlow训练图像时使用GPU错误
当我在容器tensorflow/tensorflow:LastGPU中运行tensorflow映像训练作业时,它不工作。 错误消息: GPU info: nvidia-smi周一11月26 07:48:59 2018 ----------------------------------------------------------------------------- | NVIDIA-SMI
-
如何在TensorFlow图中添加条件?
问题内容: 假设我有以下代码: 该语句在计算中是否有效(我认为不是)?如果没有,如何在TensorFlow计算图中添加一条语句? 问题答案: 您是正确的,该语句在这里不起作用,因为该条件是在图构造时评估的,而大概您希望该条件取决于运行时馈入占位符的值。(实际上,它将始终采用第一个分支,因为`condition 0Tensor`,这在Python中是“真实的”。) 为了支持条件控制流,TensorF
-
将张量转换为Tensorflow中的numpy数组?
问题内容: 将Tensorflow与Python绑定一起使用时,如何将张量转换为numpy数组? 问题答案: 急切执行默认情况下 处于启用状态,因此只需调用Tensor对象即可。 有关更多信息,请参见NumPy兼容性。值得注意的是(来自文档), Numpy数组可以与Tensor对象共享内存。 对一个的任何更改都可能反映在另一个上。 大胆强调我的。副本可以返回也可以不返回,这是基于数据是在CPU还是
-
tensorflow.train.import_meta_graph不起作用?
问题内容: 我尝试简单地保存和恢复图形,但是最简单的示例无法按预期工作(在没有CUDA且使用python 2.7或3.5.2的Linux 64上使用0.9.0或0.10.0版完成此操作) 首先,我像这样保存图形: 这将创建一个非空文件“文件”,并将g1设置为看起来像正确的图形定义的文件。 然后,我尝试还原此图: 这可以正常工作,但不会返回任何内容。 任何人都可以提供必要的代码来简单地保存“ v4”
-
如何结合语言模型构建Tensorflow语音识别
如何将语言模型集成到tensorflow语音识别体系结构中? 在Tensorflow中建立字符级语音识别有很多例子(例如。https://github.com/nervanasystems/neon, https://github.com/buriburisuri/speech-to-text-wavenet),这很有趣,但实际上毫无用处,除非集成了语言模型。我找不到使用语言模型的示例。 如何集成