
使用Keras和Tensorflow的NVIDIA GPU使用率低

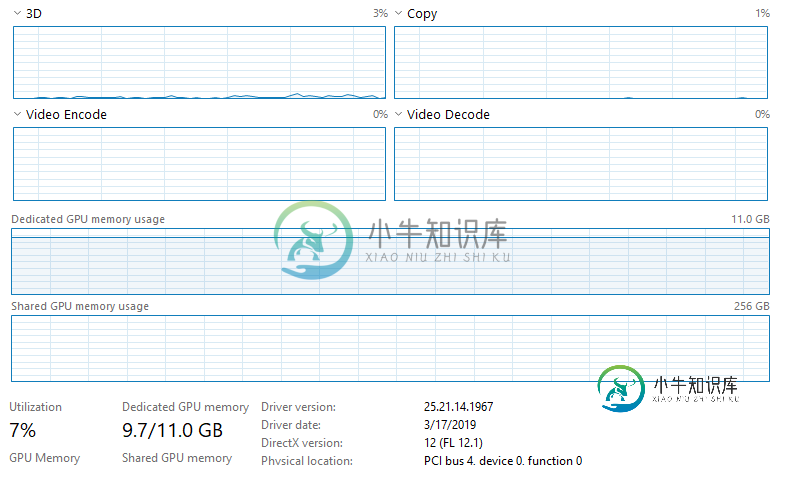
请注意,CPU没有被利用,任务管理器上的任何其他内容都表明任何东西都没有被充分利用。我没有以太网连接,并且连接到Wifi(我不认为这会影响任何事情,但我不确定Jupyter是否会影响Wifi,因为它是通过web浏览器运行的)。我正在培训大量数据(~128GB),这些数据都加载到RAM(512GB)中。我运行的模型是一个完全卷积的神经网络(基本上是一个U型网络结构),具有566290个可训练参数。到目前为止我尝试过的事情:1。将批处理大小从20增加到10000(将GPU使用率从~3-4%增加到~6-7%,大大缩短了培训时间)。2.将use_multiprocessing设置为True,并增加模型中的工作进程数。适合(无效果)。
我按照这个网站上的安装步骤:https://www.pugetsystems.com/labs/hpc/The-Best-Way-to-Install-TensorFlow-with-GPU-Support-on-Windows-10-Without-Installing-CUDA-1187/#look-at-the-job-run-with-tensorboard
请注意,此安装特别不安装CuDNN或CUDA。在过去,我在使用CUDA运行tenstorflow gpu时遇到了麻烦(尽管我已经有两年多没有尝试过了,所以使用最新版本可能会更容易),这就是我使用这种安装方法的原因。
这很可能是GPU没有得到充分利用(没有CuDNN/CUDA)的原因吗?这是否与专用GPU内存使用成为瓶颈有关?或者可能与我正在使用的网络架构有关(参数的数量等)?
如果您需要有关我的系统或我正在运行的代码/数据的更多信息来帮助诊断,请告诉我。提前谢谢!
编辑:我注意到任务管理器中有一些有趣的东西。批量大小为10000的历元大约需要200秒。在每个纪元的最后5秒,GPU的使用率增加到15-17%(从每个纪元前195年的6-7%上升)。不确定这是否有帮助,或者表明在GPU之外的某个地方存在瓶颈。
共有3个答案

一切都按预期工作;您的专用内存使用量几乎达到最大,TensorFlow和CUDA都不能使用共享内存-请参阅此答案。
如果您的GPU运行OOM,唯一的补救办法是获得一个具有更多专用内存的GPU,或者减小模型大小,或者使用下面的脚本来防止TensorFlow向GPU分配冗余资源(它确实倾向于这样做):
## LIMIT GPU USAGE
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # don't pre-allocate memory; allocate as-needed
config.gpu_options.per_process_gpu_memory_fraction = 0.95 # limit memory to be allocated
K.tensorflow_backend.set_session(tf.Session(config=config)) # create sess w/ above settings
您观察到的不寻常的使用增加可能是共享内存资源被临时访问,因为用尽了其他可用资源,特别是使用use_multiprocessing=True-但不确定,可能是其他原因

您确实需要安装CUDA/Cudnn以充分利用tensorflow的GPU。您可以通过以下方式再次检查软件包是否正确安装,以及tensorflow/keras是否可以使用GPU:
import tensorflow as tf
tf.config.list_physical_devices("GPU")
如果设备可用,则输出应该类似于[PhysicalDevice(name='/physical\u device:GPU:0',device\u type='GPU')]。
如果您已正确安装CUDA/Cudnn,则只需更改副本即可--

我首先会运行一个简短的“测试”来确保Tensorflow正在利用图形处理器。例如,我更喜欢萨尔瓦多·达利在那个相关问题中的回答
import tensorflow as tf
with tf.device('/gpu:0'):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
with tf.Session() as sess:
print (sess.run(c))
如果Tensorflow确实在使用您的GPU,您应该会看到打印的矩阵多应用程序的结果。否则,将出现一个相当长的堆栈跟踪,说明无法找到“gpu:0”。
如果一切顺利,我建议使用Nvidia的smi。exe实用程序。它可以在Windows和Linux上使用,AFAIK安装英伟达驱动程序。在windows系统上,它位于
C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi.exe
打开windows命令提示符并导航到该目录。那就跑啊
nvidia-smi.exe -l 3
这将显示一个类似的屏幕,每三秒钟更新一次。
在这里,我们可以看到关于GPU的状态和它们正在做什么的各种信息。在这种情况下,特别感兴趣的是“Pwr:用法/上限”和“挥发性GPU-Util”列。如果你的模型确实使用/a GPU,一旦你开始训练模型,这些列应该“瞬间”增加。
除非你有很好的冷却方案,否则你很可能会看到风扇速度和温度的增加。在打印输出的底部,您还应该看到一个名称类似于“python”或“Jupityr”的进程正在运行。
如果这不能提供关于缓慢训练时间的答案,那么我猜问题在于模型和代码本身。我认为这里的情况就是这样。特别是查看Windows任务管理器列表中的“专用GPU内存使用情况”Ping值基本处于最大值。
-
问题内容: 我使用keras版本2.0.0和tensorflow版本0.12.1构建了docker 镜像的gpu版本https://github.com/floydhub/dl- docker 。然后,我运行了mnist教程https://github.com/fchollet/keras/blob/master/examples/mnist_cnn.py,但意识到keras没有使用GPU。以下是
-
我的数据可以看作是10B条目的矩阵(100Mx 100),非常稀疏( 我的第一个想法是将数据扩展为密集的,也就是说,将所有10B条目写成一系列CSV,其中大多数条目为零。然而,这很快就压垮了我的资源(即使做ETL也压倒了熊猫,并导致postgres挣扎)。所以我需要使用真正的稀疏矩阵。 我怎样才能用Keras(和Tensorflow)做到这一点?虽然numpy不支持稀疏矩阵,但scipy和tens
-
Keras是紧凑,易于学习的高级Python库,运行在TensorFlow框架之上。它的重点是理解深度学习技术,例如为神经网络创建维护形状和数学细节概念的层。freamework的创建可以是以下两种类型 - 顺序API 功能API 在Keras中创建深度学习模型有以下 8 个步骤 - 加载数据 预处理加载的数据 模型的定义 编译模型 指定模型 评估模型 进行必要的预测 保存模型 下面将使用Jupy
-
我已经在纸质空间云架构体系上创建了虚拟笔记本,后端有Tensorflow GPU P5000虚拟实例。当我开始训练我的网络时,它比我的MacBook Pro用纯CPU运行时引擎慢2倍。如何确保Keras NN在训练过程中使用GPU而不是CPU? 请在下面找到我的代码:
-
TFLearn可以定义为TensorFlow框架中使用的模块化和透明的深度学习方面。TFLearn的主要动机是为TensorFlow提供更高级别的API,以促进和展示新的实验。 考虑TFLearn的以下重要功能 - TFLearn易于使用和理解。 TFLearn包括简单的概念,以构建高度模块化的网络层,优化器和嵌入其中的各种指标。 TFLearn包括TensorFlow工作系统的完全透明性。 TF
-
问题内容: 运行keras脚本时,得到以下输出: 这是什么意思?我是否正在使用GPU或CPU版本的Tensorflow? 在安装keras之前,我正在使用Tensorflow的GPU版本。 还显示和没有什么像。 运行[此stackoverflow问题]中提到的命令,将得到以下信息: 问题答案: 您正在使用GPU版本。您可以列出可用的tensorflow设备(也请检查此问题): 编辑: 使用tens