《kafka》专题
-
kafka 同时设置了 7 天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka 将如何处理?
本文向大家介绍kafka 同时设置了 7 天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka 将如何处理?相关面试题,主要包含被问及kafka 同时设置了 7 天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka 将如何处理?时的应答技巧和注意事项,需要的朋友参考一下 这个时候 kafka 会执行数据清除工作,时间和大小不论那个满足条件,都会清
-
KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
本文向大家介绍KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?相关面试题,主要包含被问及KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?时的应答技巧和注意事项,需要的朋友参考一下 1.在每个线程中新建一个KafkaConsumer 2.单线程创建KafkaConsumer,多个处理线程处理消息(难点在于是否要考虑消息顺序性,offset的提交方式)
-
使用 kafka 集群需要注意什么?
本文向大家介绍使用 kafka 集群需要注意什么?相关面试题,主要包含被问及使用 kafka 集群需要注意什么?时的应答技巧和注意事项,需要的朋友参考一下 集群的数量不是越多越好,最好不要超过 7 个,因为节点越多,消息复制需要的时间就越长,整个群组的吞吐量就越低。 集群数量最好是单数,因为超过一半故障集群就不能用了,设置为单数容错率更高。
-
kafka 有几种数据保留的策略?
本文向大家介绍kafka 有几种数据保留的策略?相关面试题,主要包含被问及kafka 有几种数据保留的策略?时的应答技巧和注意事项,需要的朋友参考一下 kafka 有两种数据保存策略:按照过期时间保留和按照存储的消息大小保留。
-
什么情况会导致 kafka 运行变慢?
本文向大家介绍什么情况会导致 kafka 运行变慢?相关面试题,主要包含被问及什么情况会导致 kafka 运行变慢?时的应答技巧和注意事项,需要的朋友参考一下 cpu 性能瓶颈 磁盘读写瓶颈 网络瓶颈
-
kafka中的broker 是干什么的?
本文向大家介绍kafka中的broker 是干什么的?相关面试题,主要包含被问及kafka中的broker 是干什么的?时的应答技巧和注意事项,需要的朋友参考一下 broker 是消息的代理,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉取指定Topic的消息,然后进行业务处理,broker在中间起到一个代理保存消息的中转站。
-
kafka工作原理?
本文向大家介绍kafka工作原理?相关面试题,主要包含被问及kafka工作原理?时的应答技巧和注意事项,需要的朋友参考一下 producer向broker发送事件,consumer从broker消费事件。 事件由topic区分开,每个consumer都会属于一个group。 相同group中的consumer不能重复消费事件,而同一事件将会发送给每个不同group的consumer。
-
Kafka 与传统消息系统之间有三个关键区别?
本文向大家介绍Kafka 与传统消息系统之间有三个关键区别?相关面试题,主要包含被问及Kafka 与传统消息系统之间有三个关键区别?时的应答技巧和注意事项,需要的朋友参考一下 (1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留 (2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据 提升容错能力和高可用性 (3).Kafka 支持实时的流式处理
-
聊一聊你对Kafka的Log Retention的理解
本文向大家介绍聊一聊你对Kafka的Log Retention的理解相关面试题,主要包含被问及聊一聊你对Kafka的Log Retention的理解时的应答技巧和注意事项,需要的朋友参考一下 kafka留存策略包括 删除和压缩两种 删除: 根据时间和大小两个方式进行删除 大小是整个partition日志文件的大小 超过的会从老到新依次删除 时间指日志文件中的最大时间戳而非文件的最后修改时间 压缩:
-
Kafka 分区数可以增加或减少吗?为什么?
本文向大家介绍Kafka 分区数可以增加或减少吗?为什么?相关面试题,主要包含被问及Kafka 分区数可以增加或减少吗?为什么?时的应答技巧和注意事项,需要的朋友参考一下 我们可以使用 bin/kafka-topics.sh 命令对 Kafka 增加 Kafka 的分区数据,但是 Kafka 不支持减少分区数。 Kafka 分区数据不支持减少是由很多原因的,比如减少的分区其数据放到哪里去?是删除,
-
Kafka消息是采用Pull模式,还是Push模式?
本文向大家介绍Kafka消息是采用Pull模式,还是Push模式?相关面试题,主要包含被问及Kafka消息是采用Pull模式,还是Push模式?时的应答技巧和注意事项,需要的朋友参考一下 Kafka最初考虑的问题是,customer应该从brokes拉取消息还是brokers将消息推送到consumer,也就是pull还push。在这方面,Kafka遵循了一种大部分消息系统共同的传统的设计:pro
-
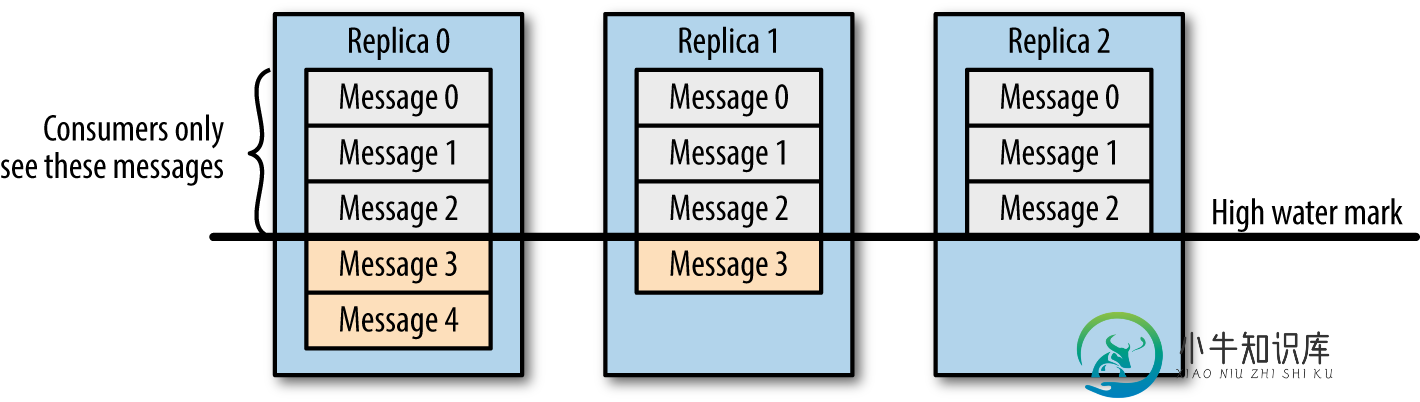 请谈一谈 Kafka 数据一致性原理?
请谈一谈 Kafka 数据一致性原理?本文向大家介绍请谈一谈 Kafka 数据一致性原理?相关面试题,主要包含被问及请谈一谈 Kafka 数据一致性原理?时的应答技巧和注意事项,需要的朋友参考一下 一致性就是说不论是老的 Leader 还是新选举的 Leader,Consumer 都能读到一样的数据。 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop 假设分区的副本为3,
-
Kafka中的HW、LEO、LSO、LW等分别代表什么?
本文向大家介绍Kafka中的HW、LEO、LSO、LW等分别代表什么?相关面试题,主要包含被问及Kafka中的HW、LEO、LSO、LW等分别代表什么?时的应答技巧和注意事项,需要的朋友参考一下 HW:High Watermark 高水位,取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置上一条信息。 LEO:LogEndOffset 当前日志
-
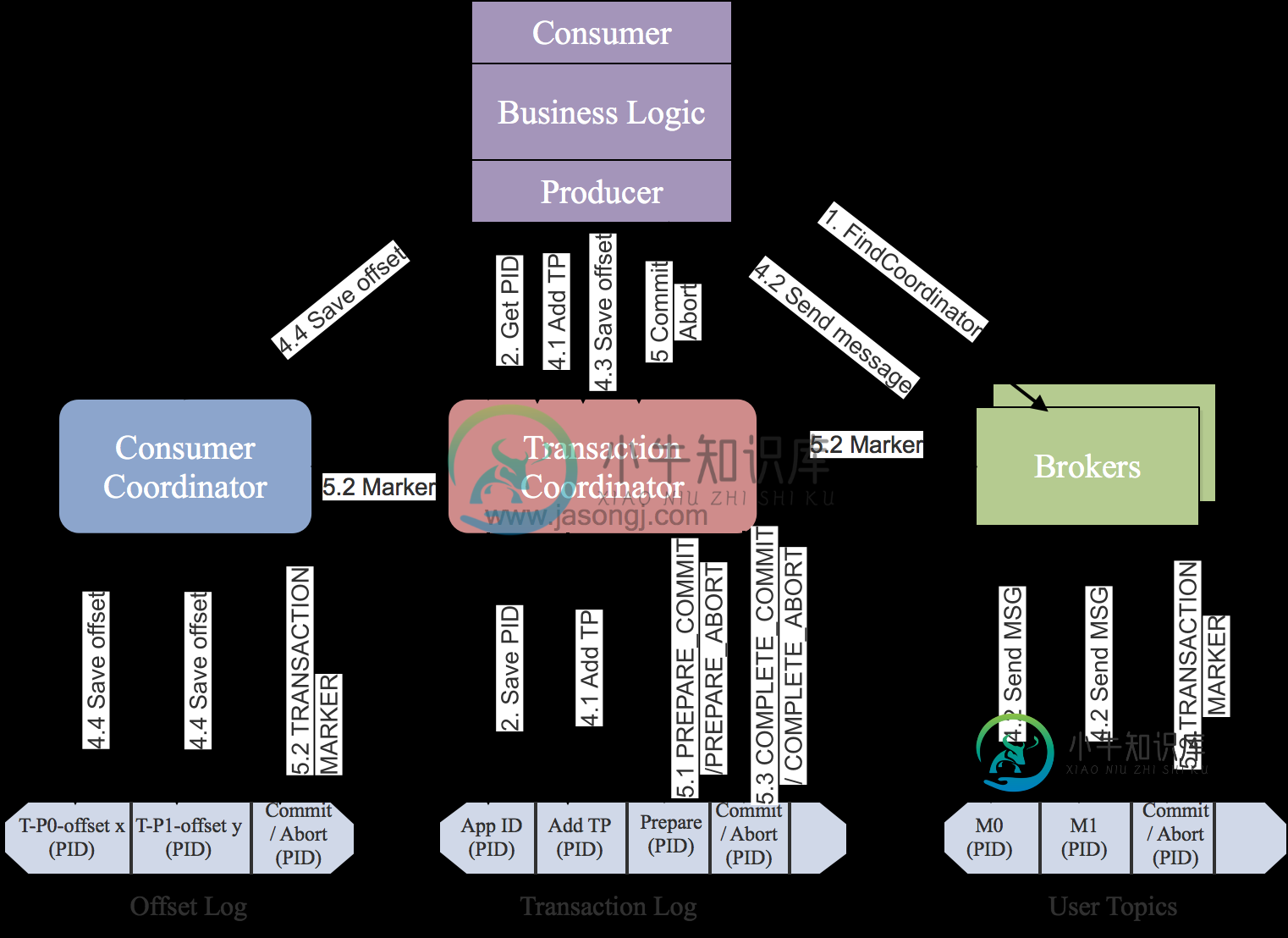 谈谈你对 Kafka 事务的了解?
谈谈你对 Kafka 事务的了解?本文向大家介绍谈谈你对 Kafka 事务的了解?相关面试题,主要包含被问及谈谈你对 Kafka 事务的了解?时的应答技巧和注意事项,需要的朋友参考一下 为什么要提供事务机制 Kafka事务机制的实现主要是为了支持 即正好一次语义 操作的原子性 有状态操作的可恢复性 《Kafka背景及架构介绍》一文中有说明Kafka在0.11.0.0之前的版本中只支持和语义,尚不支持语义。 但是在很多要求严格的场景
-
Kafka生产者客户端中使用了几个线程来处理?分别是什么?
本文向大家介绍Kafka生产者客户端中使用了几个线程来处理?分别是什么?相关面试题,主要包含被问及Kafka生产者客户端中使用了几个线程来处理?分别是什么?时的应答技巧和注意事项,需要的朋友参考一下 2个,主线程和Sender线程。主线程负责创建消息,然后通过分区器、序列化器、拦截器作用之后缓存到累加器RecordAccumulator中。Sender线程负责将RecordAccumulator中