《kafka》专题
-
将自定义Java对象发送到Kafka主题
问题内容: 我有我的自定义Java对象,希望利用JVM的内置序列化将其发送到Kafka主题,但是序列化失败并出现以下错误 org.apache.kafka.common.errors.SerializationException:无法将com.spring.kafka.Payload类的值转换为value.serializer中指定的org.apache.kafka.common.serializ
-
Kafka KStreams-处理超时
问题内容: 我试图用一个批量一些 KTable 值,并送他们。似乎30秒钟超出了使用者超时间隔,在此间隔之后,Kafka认为该使用者已失效并释放了分区。 我尝试提高 轮询 和 提交间隔 的频率来避免这种情况: 不幸的是,这些错误仍在发生: (很多) 其次是: 显然,我需要更频繁地将心跳发送回服务器。怎么样? 我的拓扑是: 该 KTable 是关键,每30秒分组值。在 Processor.init(
-
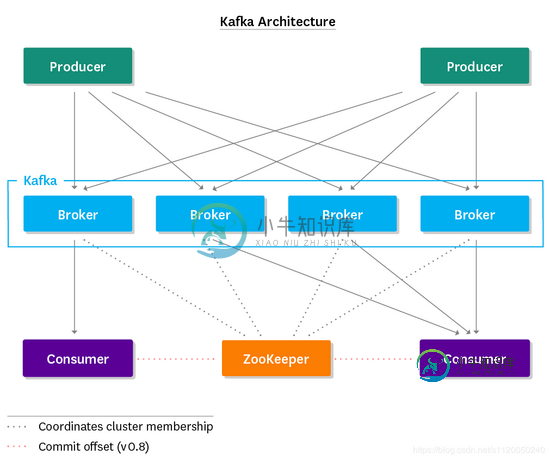 .NET Core下使用Kafka的方法步骤
.NET Core下使用Kafka的方法步骤本文向大家介绍.NET Core下使用Kafka的方法步骤,包括了.NET Core下使用Kafka的方法步骤的使用技巧和注意事项,需要的朋友参考一下 安装 CentOS安装 kafka Kafka : http://kafka.apache.org/downloads ZooLeeper : https://zookeeper.apache.org/releases.html 下载并解压 启动
-
Kafka连接->S3拼花文件Bytearley
我正在尝试使用Kafka-connect来消耗Kafka的消息并将它们写入s3拼花文件。所以我写了一个简单的生产者,它用byte[]生成消息 我的Kafka连接配置是: 这是我得到的错误: 原因:java。lang.IllegalArgumentException:Avro架构必须是记录。在org。阿帕奇。拼花地板阿夫罗。AvroSchemaConverter。转换(AvroSchemaConve
-
从Kafka连接到S3的拼花输出
我看到Kafka Connect可以以Avro或JSON格式写入S3。但是没有Parket支持。添加这个有多难?
-
将Kafka中的Avro直接转换为拼花地板到S3
我有以Avro格式存储的Kafka主题。我想使用整个主题(在收到时不会更改任何消息)并将其转换为Parket,直接保存在S3上。 我目前正在这样做,但它要求我每次消费一条来自Kafka的消息,并在本地机器上处理,将其转换为拼花文件,一旦整个主题被消费,拼花文件完全写入,关闭写入过程,然后启动S3多部分文件上传。或《Kafka》中的阿夫罗- 我想做的是《Kafka》中的阿夫罗- 注意事项之一是Kaf
-
Kafka-connect文件接收器连接器以拼花文件格式写入
我正在寻找Kafka连接连接器,将写从Kafka到本地文件系统的拼花文件格式。我不想使用hdfs或s3接收器连接器进行同样的操作。
-
 flink的Kafka水印策略在我的应用程序中不起作用
flink的Kafka水印策略在我的应用程序中不起作用我使用flink版本1.13.0 当我试图使用flink doc的Kafka水印策略时,这似乎不起作用,窗口处理功能将不会运行。 我想知道,在Kafka中,水印的时间戳将使用消费时间还是生产时间? 我的消费者代码如下: 并像这样使用窗口: 拓扑图是这样的:
-
将KafkaFlink到S3并重试
我是Flink的新手,我需要从Kafka读取数据,通过使用一些API有条件地丰富这些数据(如果记录属于X类),然后写入S3。 我用上面的逻辑制作了一个你好世界Flink应用程序,它就像一个魅力。 但是,我用来充实的API没有100%的正常运行时间SLA,所以我需要设计一些带有重试逻辑的东西。 以下是我找到的选项, 选项1)进行指数重试,直到从API获得响应,但这会阻塞队列,所以我不喜欢这样 选项2
-
Flink Kafka:在没有收到消息的时间间隔后,优雅地关闭Flink消费来自Kafka源的消息
我已将flinkkafkaconsumer作为源添加到我的streamexecutionenvironment中。我想在特定时间内没有收到新消息时关闭/阻止flink使用数据(类似于kafka polltime)。目前它正在无限期运行,并阻止执行移动到下一步(验证消息)。请建议是否有任何解决方法。 注意:我从反序列化中尝试了endofstream,但它无法工作,因为流实际上是不确定的。 提前谢谢。
-
使用Kafka作为EventStore时恢复Flink中的状态一致性
我将微服务实现为事件源聚合,而事件源聚合又被实现为Flink FlatMapFunction。在基本设置中,聚合从两个kafka主题读取事件和命令。然后,它将新事件写入第一个主题并处理第三个主题的结果。因此,Kafka充当事件存储。希望这张图能有所帮助: 由于Kafka没有选中点,因此命令可能会被重放两次,而且输出事件似乎也可以在主题中写入两次。 在重复消息的情况下如何恢复状态?聚合是否可以知道其
-
Java-是否可以将Spring Cloud Stream Kafka和RabbitMQ用于同一应用程序
我们有一个应用程序已经在使用带有RabbitMQ的Spring Cloud Stream,该应用程序的一些endpoint正在向Rabbit MQ发送消息。现在我们希望新的endpoint开始向Kafka发送消息,希望现有endpoint继续使用带有Spring Cloud Stream的RabbitMQ。我不确定这是否可能,因为这意味着我们必须在pom.xml.中包含kafka和Rabbit绑定
-
通过读取kafka中的详细信息创建动态闪烁窗口
假设Kafka消息包含flink窗口大小配置。 我想阅读Kafka的信息,并在flink中创建一个全局窗口。 问题陈述: 我们可以使用BroadcastStream处理上述情况吗? 或 是否有其他支持上述情况的方法?
-
Kafka Conenct HDFS接收器以拼花格式保存数据
使用Kafka Connect HDFS Sink,我能够将avro数据写入Kafka主题并将数据保存在hive/hdfs中。 我正在尝试使用格式类以拼花文件格式保存数据 快速启动hdfs。属性如下 当我将数据发布到Kafka时,表在hive中创建,test\u hdfs\u parquet目录在hdfs中创建,但由于以下异常,Sink无法以parquet格式保存数据
-
如何配置Kafka Connect Worker以将大量消息流式传输到HDF
我当前的工作设置: NiFi将Avro消息(ConFluent Schema注册表参考)流式传输到Kafka(v2.0.0,20个分区,ConFluent v5.0.0),Kafka Connect Worker(HDFS接收器)将这些消息以Parket格式流式传输到HDFS,。 我的问题: 这个配置很好,但当我将配置更改为flush时。大小=1000000(因为70k条消息的最大大小为5-7MB