《kafka》专题
-
火花Kafka生产者可串行化
我想出一个例外: 在这个程序中,我尝试从hdfs路径读取记录,并将它们保存到Kafka中。问题是当我移除关于向Kafka发送记录的代码时,它运行得很好。我错过了什么?
-
已忽略log4j2自定义kafka Appender插件
我创建了一个自定义的Log4J2Kafka附加器,因为我需要以协议缓冲区格式发送消息。当我运行应用程序时,我看到以下警告。如何使自定义追加器覆盖默认追加器? 插件[kafka]已经映射到类org.apache.logging.log4j.core.appender.mom.kafka.kafkaappender,忽略了类com.abc.appender.kafkaappender 注意:我阅读了h
-
Camel:检测Kafka错误IP
我正在将Kafka配置为RouteBuilder中的源。我的目标是处理Kafka断线问题。我的RouteBuilder如下: 我提供了错误的主机和端口,并期望看到一个异常。但是,在日志中没有看到异常,并且没有调用onException处理。知道我做错了什么吗? 通过在本地运行https://github.com/apache/camel/blob/master/examples/camel-exa
-
Kafka比较键的连续值
我们正在构建一个应用程序来从传感器获取数据。数据流传输到Kafka,消费者将从Kafka发布到不同的数据商店。每个数据点都有多个表示传感器状态的属性。 在其中一个消费者中,我们希望仅当值发生更改时才将数据发布到数据存储。例如,如果有温度传感器,每10秒轮询一次数据,我们希望收到如下数据: 在上述情况下,只应发布第一条记录和第三条记录。 为此,我们需要某种方法来比较键的当前值与具有相同键的先前值。我
-
Kafka Stream自动从新主题读取?
有什么方法可以让我的Kafka Stream应用程序自动从新创建的主题中读取? 即使主题是在流应用程序已经运行时创建的? 类似于在主题名称中使用通配符,如下所示: 现在,我有多个客户端将数据(都使用相同的模式)发送到它们自己的主题,我的流应用程序从这些主题中读取数据。然后,我的应用程序进行一些转换,并将结果写入单个主题。 虽然所有的客户都可以写同一个主题,但一个没有偏见的客户也可以代表其他人写。所
-
压缩后的Kafka主题可以用作键值数据库吗?
在许多文章中,我读到压缩的Kafka主题可以用作数据库。然而,当查看Kafka API时,我找不到允许我根据键查询主题值的方法。 那么,压缩的Kafka主题可以用作(高性能、只读)键值数据库吗? 在我的架构中,我希望为组件提供一个紧凑的主题。我想知道该组件是否需要在其本地数据库中具有该主题的副本,或者它是否可以将该压缩主题用作键值数据库。
-
Kafka Topic-过滤和分派消息
我们的软件解决方案为每个客户收集数据(“事件”)<一些客户(一小部分约3%)要求将这些数据输入“他们的系统”(他们需要为此服务付费)<我们需要发送这些事件的目标系统可能是: AWS S3 Azure存储 Splunk 数据狗 未来会有更多的目标系统... 上面的所有目标系统都有众所周知的Kafka Connect接收器连接器,因此我们的想法是使用这些连接器来导出数据。 所有客户事件都转到一个“输入
-
当发件人类型为kafka时,跟踪不显示在zipkin中
当我创建spring.Zipkin.sender.type=web时,Zipkin dashboard中显示了跟踪,这里有没有我缺少的东西。
-
使用KafkaStreams处理主题时,如何从主题中获取上一条消息
我一直在使用covid19api持有的数据实现Kafka生产者/消费者和流。 我试图从endpoint中提取每天的案例https://api.covid19api.com/all.然而,这个服务——以及这个API中的其他服务——拥有自疾病开始以来的所有数据(确诊、死亡和恢复病例),但积累了数据,而不是日常病例,这就是我最终要实现的。 使用transformValues和StoreBuilder(正
-
加入外键Kafka流
假设我有三个Kafka主题,其中充满了表示不同聚合中发生的业务事件的事件(事件源应用程序)。这些事件允许构建具有以下属性的聚合: 用户:usedId,名称 应用程序的模块:moduleId,name 授予用户应用程序模块:grantId、userId、moduleId、作用域 现在,我想创建一个包含所有授权的流,其中包含用户和产品的名称(而不是id)。我想这么做: 通过按用户ID对事件进行分组,为
-
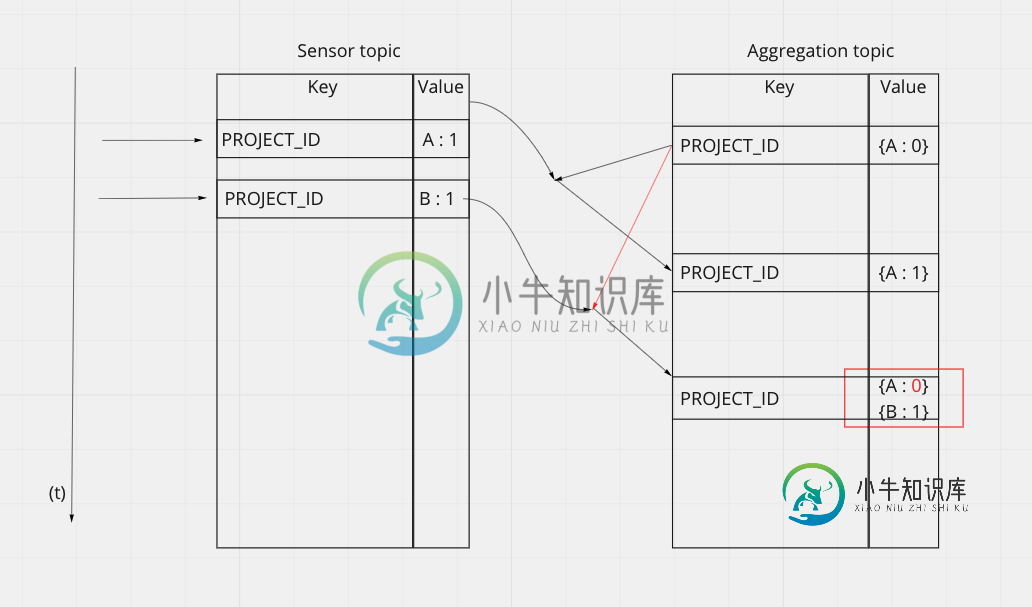 Kafka聚合事件
Kafka聚合事件我有一个条目主题,其中我从传感器接收数据。通常,我收到的数据如下所示: 为了稍后在拓扑中进行一些计算,我需要构建一个映射,其中包含从每个捕获者接收到的所有最后值。 关键字:项目id值:{ 为了做到这一点,我在传感器主题和聚合主题之间进行了连接,连接的结果是聚合主题中的post。 ------ 传感器(KStream)-| -------聚合(KTable)---| 更新:以下是实现这种连接的jav
-
如何在Kafka流应用程序中迭代GlobalKTable或KTable
我有一个Kafka流应用程序,有两个数据源:事件和用户。 我有4个主题:事件,用户,用户2,用户事件 Users2与Users相同,用于演示GlobalKTable。 Events主题使用时间戳模式,因此当到达时间戳字段日期时,KStream将接收事件记录。 此时,我想为用户KTable中的每个用户ID以及新的事件ID创建一个用户事件记录;但我不知道如何遍历GlobalKTable或KTable来
-
洛格萨什和Kafka
我的服务器机器上运行单节点kafka。我使用以下命令创建主题“bin/kafka-topics.sh--创建--zookeeper本地主机:2181--复制因子1--分区1--主题测试”。我有两个logstash实例正在运行。第一个从一些java应用程序日志文件中读取数据,并将其注入kafka。它工作得很好,我可以使用“bin/kafka-console-consumer.sh——zookeepe
-
理解Kafka Streams中处理器实现中的事务
在使用Kafka Streams的处理器API时,我使用了如下内容: 实际上,我在这里做的是每分钟从状态存储发送一个状态到下沉(在init()方法中使用context.schedule())。我不明白的是: 我向前发送的[Key,Value]对,然后执行commit(),从状态存储中获取。它是根据我的特定逻辑从许多非连续输入[键,值]对中聚合的。每个这样的输出[键,值]对都是来自输入的几个非有序[
-
Kafka流窗口加入保留
我们正在使用kafka streams的windows join连接2个流,我们想知道: 为什么KS要在内部主题上增加24小时?例如,我们有一个1小时的窗口,但内部主题保留25小时。我们可以将其配置为不添加这些24小时吗 [更新] 例如,我们创建JoinWindow如下: 虽然我可以看到内部主题(JOINTHIS和OUTEROTHER)是用 这是刚刚在我的机器上的一个空代理(使用confluent