《kafka》专题
-
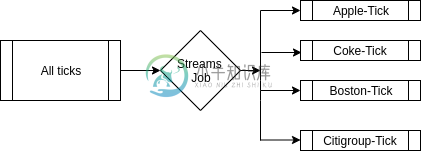 分散Kafka流中的消息
分散Kafka流中的消息我试图找出最好的方式将我的数据扇出到单独的占位符中,以供其他处理的数据使用 用例我正在接收Kafka主题中几个脚本(约2000只股票)的股票数据。我希望能够单独在所有脚本上运行KPI(KPI就像应用于输入数据以获取KPI值的公式)。 我能想到的选项 > 将所有刻度数据保存在一个主题中,并使用Custom分区器按脚本名称对其进行分区。这有助于保持低主题计数和系统易于管理。但是所有消费者都需要丢弃大量
-
将消息从一个Kafka集群流式传输到另一个
我目前正在尝试轻松地将消息从一个Kafka集群上的主题流式传输到另一个集群(远程)- 所以假设WordCount演示在另一台PC上的一个Kafka-Instance上,而不是我自己的PC上。我也有一个Kafka-Instance在我的本地机器上运行。 现在我想让WordCount演示在包含应该计算单词的句子的Topic(“远程”)上运行。 然而,计数应该写入我本地系统上的Topic而不是“远程”T
-
 Kafka连接:主题显示的事件数是预期的3倍
Kafka连接:主题显示的事件数是预期的3倍我们正在使用Kafka Connect JDBC将表同步到数据库(Debezium非常适合,但不可能)。 Sync通常运行良好,但似乎存储在主题中的事件/消息数量是预期的3倍。 这可能是什么原因? 一些附加信息 目标数据库包含确切的消息数(主题中的消息数/3)。 大多数主题分为3个分区(键通过SMT设置,使用DefaultPartitioner)。 JDBC源连接器 JDBC接收器连接器 奇怪的主
-
我可以从Lambda函数中使用AWS MSK kafka主题吗?
我认为使用lambda来消费到达AWS MSK Kafka集群中某个主题的消息很简单,但我无法从AWS文档中找到这样做的方法。在某种程度上可能吗?
-
使用Kafka连接转换Kafka消息有意义吗?
我们的基础设施中有融合平台。核心是,我们使用kafka代理来分发事件。许多设备会生成Kafka主题的事件(每种类型的事件都有一个Kafka主题),事件在谷歌的protobuf中序列化。我们有confluent的模式注册表来跟踪protobuf模式。 我们需要的是,对于一些事件,我们需要应用一些转换,然后将转换输出发布到其他一些Kafka主题。当然,Kafka流是实现这一点的一种方法,如本例中所示。
-
 如何在Amazon MSK上运行Kafka骆驼连接器
如何在Amazon MSK上运行Kafka骆驼连接器背景:我按照这个链接设置了AWS MSK,并测试了生产者和消费者,它的设置和工作正常。我能够通过两个单独的EC2实例发送和接收消息,这两个实例都使用同一个Kafka集群(我的MSK集群)。现在,我想建立一条从Eventhubs到AWS Firehose的数据管道,其形式如下: Azure Eventhub- 我能够成功地做到这一点,没有使用MSK(通过常规的老Kafka),但由于未说明的原因,需要
-
Kafka连接:使用debezium从Postgres到主题的流媒体变化
我对Kafka和Kafka Connect世界很陌生。我正在尝试使用Kafka(在MSK上)、Kafka Connect(使用PostgreSQL的Debezium连接器)和RDS Postgres实例来实现CDC。Kafka Connect在我们部署在AWS中的集群中的K8 pod中运行。 在深入研究所使用的配置的细节之前,我将尝试总结问题: 连接器启动后,它会按预期向主题发送消息(snahps
-
Apache Kafka与MongoDB-4.0的官方MongoDB源连接器
我有一个要求,我必须捕获MongoDB ChangeStream(插入/更新等)事件并采取一些操作(保存到OracleDB)。我想到了这个似乎不错的设计:
-
如何克服Kafka连接器启动时的非法访问错误
是否需要手动设置此?这不是默认设置的。 我使用的是docker图像confluentinc/cp-kafka:5.0.1。我在连接器应用程序中使用的connect-api版本是org.apache.kafka:connect-api:2.0.0。我在Kubernetes内部运行我的设置。
-
无法生成kafka-connect-jdbc源代码
命令失败,我无法构建kafka-connect-jdbc源代码。我的意图是修改kafka-connect-jdbc源代码。 我遵循了说明https://github.com/confluentinc/kafka-connect-jdbc/issues/456和https://github.com/confluentinc/kafka-connect-jdbc/wiki/faq 所有这些都不能解决问
-
Kafka合流图书馆民意测验与消费的差异
我在这里查看了Confluent Kafka库中的消费者实现,感觉它们在功能上是相同的,只是在返回的内容方面有所不同。 Poll()调用consumer()来查看是否有消息准备好要拾取,如果是,则调用OnMessage事件。versour,consumer,将消息保存在它的一个参数中,并返回一个布尔值。我觉得不同之处在于实现上,功能上是相同的https://github.com/confluent
-
用docker容器链接Kafka和HDFS
我使用的示例是:https://clubhouse.io/developer-how-to/how-to-set-up-a-hadoop-cluster-in-docker/ 我首先用:docker-compose up-d开始HDFS 然后我用debezium网站上的图片启动了动物园管理员Kafka和mysql。https://debezium.io/documentation/referenc
-
Kafka连接S3动态S3文件夹结构创建?
可以看到AWS MSK的主题CDC偏移正在消耗。不会抛出任何错误。但是,在AWS S3中,没有为新数据创建文件夹结构,也没有存储JSON数据。 问题 连接器是否应该在看到主题的第一个JSON数据包时动态创建文件夹结构? 除了配置awscli凭据、connect.properties和s3-sink.properties之外,是否还需要设置其他设置才能正确连接到S3存储桶? 关于安装文档的建议比Co
-
从Kafka流解析JSON RDD时的Java执行
我正在尝试使用Spark stream库从kafka读取一个json字符串。该代码能够连接到kafka broker,但在解码消息时失败。代码的灵感来自 https://github.com/killrweather/killrweather/blob/master/killrweather-examples/src/main/scala/com/datastax/killrweather/kaf
-
需要从Kafka主题中读取记录,一旦读取了50条记录,就调用一个API,该API在一个请求中接受50条记录
我需要从Kafka主题中读取记录,一旦读取了50条记录,就调用一个API,该API在一个请求中接受50条记录。 当应用程序没有任何存储数据库时,有什么建议如何实现它吗? 我能够阅读Kafka主题中的记录,寻找如何将记录排队直到计数达到50的建议。