《kafka》专题
-
Spark Stream Kafka挂在JavaStreamingContext.start上,不创建Spark作业
OS:Red Hat Enterprise Linux Server 6.5版JRE:Oracle 1.8.0.144-b01 spark-streaming2.11:2.1.0 spark-streaming-kafka-0-102.11:2.1.0 Spark stream Kafka jar由Spark提交-提交到独立的Spark集群,并运行良好几天。但是最近,我们发现没有为流生成新的作业,
-
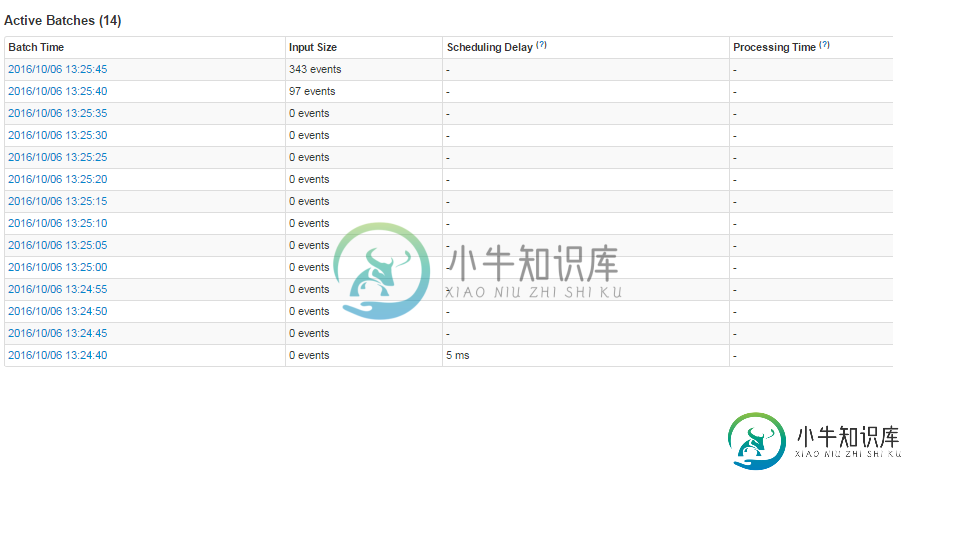 火花流与Kafka-从检查点重新启动
火花流与Kafka-从检查点重新启动我们正在构建一个使用Spark Streaming和Kafka的容错系统,并且正在测试Spark Streaming的检查点,以便在Spark作业因任何原因崩溃时可以重新启动它。下面是我们的spark过程的样子: Spark Streaming每5秒运行一次(幻灯片间隔),从Kafka读取数据 Kafka每秒大约接收80条消息 我们想要实现的是一个设置,在这个设置中,我们可以关闭spark流作业(
-
重新启动Spark Structured Streaming Job会消耗数百万条Kafka消息并死亡
我们有一个运行在Spark2.3.3上的Spark流应用程序 基本上,它开启了一条Kafka流: 我们尝试: > spark.streaming.backpressure.enabled=true以及spark.streaming.backpressure.initialrate=2000和spark.streaming.kafka.maxratePerpartition=1000和spark.s
-
用于kafka avro解码器消息的spark数据集编码器
错误:错误:(49,9)找不到存储在数据集中的类型的编码器。导入spark.implicits支持基元类型(Int、String等)和产品类型(case类)。_在以后的版本中将增加对序列化其他类型的支持。.map(msg=>{
-
使用Spark Streaming时限制Kafka批大小
是否可以限制Kafka消费者返回Spark Streaming的批的大小? 我这么问是因为我得到的第一批记录有上亿条记录,处理和检查它们需要很长时间。
-
Spark结构化流式Kafka偏移管理
我正在研究为Spark结构化流在kafka中存储kafka偏移量,就像它为DStreams工作一样,除了结构化流,我也在研究同样的情况。是否支持结构化流?如果是,我如何实现? 我知道使用进行hdfs检查点,但我对内置的偏移量管理感兴趣。 我期待Kafka存储偏移量只在内部没有火花hdfs检查点。
-
kafka Max.Poll.Records在spark streaming中不起作用
我的spark streaming版本是2.0,kafka版本是0.10.0.1,Spark-Streaming-Kafka-0-102.11。我使用直接的方式来获取Kafka记录,我现在想限制我在一个批处理中获取的消息的最大数量。所以我设置了max.poll.records值,但它不起作用。spark中的消费者数就是Kafka中的分区数?所以spark流中的最大记录数是max.poll.reco
-
Kafka分区是如何在火花流与Kafka共享的?
我想知道Kafka分区是如何在从executor进程内部运行的SimpleConsumer之间共享的。我知道高水平的Kafka消费者是如何在消费者群体中的不同消费者之间分享利益的。但是,当Spark使用简单消费者时,这是如何发生的呢?跨计算机的流作业将有多个执行程序。
-
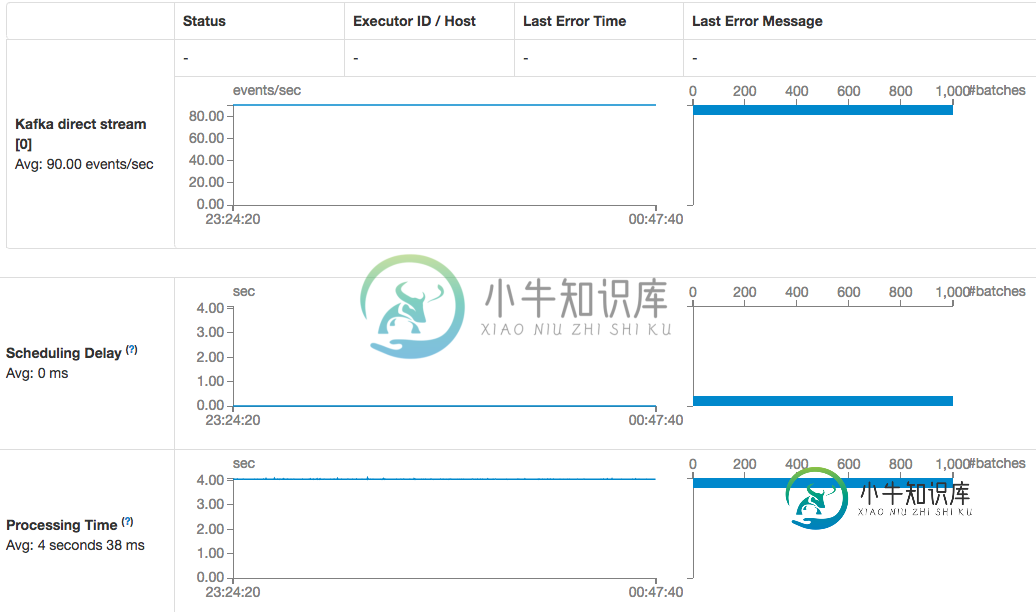 火花流Kafka直接消费者消费速度下降
火花流Kafka直接消费者消费速度下降我使用的是运行在AWS中的spark独立集群(spark and spark-streaming-kafka version 1.6.1),并对检查点目录使用S3桶,每个工作节点上没有调度延迟和足够的磁盘空间。 没有更改任何Kafka客户端初始化参数,非常肯定Kafka的结构没有更改: 也不明白为什么当直接使用者描述说时,我仍然需要在创建流上下文时使用检查点目录?
-
火花流从Kafka源返回到检查点或重绕
当streaming Spark DStreams作为来自Kafka源的消费者时,可以检查Spark上下文,因此当应用程序崩溃(或受到的影响)时,应用程序可以从上下文检查点恢复。但如果应用程序“意外地部署了错误的逻辑”,您可能想要倒回到最后一个主题+分区+偏移量,以重播某个Kafka主题的分区偏移量位置的事件,这些位置在“错误逻辑”之前正常工作。当检查点生效时,流式应用程序如何被重绕到最后的“好点
-
spark kafka集成检查点重用
我使用http://spark.apache.org/docs/latest/streaming-kafka-integration.html中的方法2,我使用检查点,当我必须更改代码和重新部署代码时,有时检查点会抛出异常,如果出于某种原因,我必须删除检查点目录,我如何重用检查点目录文件夹从kafka获取消息,我认为检查点目录存储了kafka偏移量。
-
用于kafka主题再处理的火花流批处理间隔
当前设置:Spark流作业处理timeseries数据的Kafka主题。大约每秒就有不同传感器的新数据进来。另外,批处理间隔为1秒。通过,有状态数据被计算为一个新流。一旦这个有状态的数据穿过一个treshold,就会生成一个关于Kafka主题的事件。当该值后来降至treshhold以下时,再次触发该主题的事件。 问题:我该如何避免这种情况?最好不要切换框架。在我看来,我正在寻找一个真正的流式(一个
-
 为什么Apache Storm KafkaSpout从Kafka话题发出这么多条目?
为什么Apache Storm KafkaSpout从Kafka话题发出这么多条目?我对Kafka和斯托姆有意见。我现在不确定是我正在设置的KafkaSpout配置有问题,还是我没有正确地进行处理。 我在我的Kafka主题上排了50个条目,但我的喷口发出了1300多个(而且还在计数)元组。此外,the Spout报道说,几乎所有人都“失败了”。拓扑实际上并没有失败,它正在成功地写入数据库,但我只是不知道为什么它明显地重播所有内容(如果它正在这样做的话) 最大的问题是: 下面是我如
-
Storm-KafkaSpout在open()时失败
然而,我在激活时不断得到错误,然后监视拓扑。下面是我实现的Storm拓扑的源代码: 但是,在执行时,我不断得到的错误消息如下: 然而,通过检查工作者的日志(worker.log文件),我得出结论认为KafkaSpout在open()方法上失败。
-
在尊重maxSpoutPending的同时关闭KafkaSpout中的添加
我用的是暴风0.9.3。我正在尝试关闭拓扑的每元组计数。我将config.topology_acker_executors设置为0,将maxSpoutPending设置为500。当我运行我的拓扑时,我注意到maxSpoutPending被忽略了,并且spout继续发射,远远超过了这个限制。这是我的配置- 我用KafkaSpout来读Kafka的文章,用一个螺栓来读Kafka的文章。