
火花流与Kafka-从检查点重新启动

我们正在构建一个使用Spark Streaming和Kafka的容错系统,并且正在测试Spark Streaming的检查点,以便在Spark作业因任何原因崩溃时可以重新启动它。下面是我们的spark过程的样子:
- Spark Streaming每5秒运行一次(幻灯片间隔),从Kafka读取数据
- Kafka每秒大约接收80条消息
我们想要实现的是一个设置,在这个设置中,我们可以关闭spark流作业(以模拟失败),然后重新启动它,并且仍然确保我们处理来自Kafka的每条消息。这似乎很管用,但我看到的是我不知道该怎么做:
-
null
如有任何关于这方面的投入,将不胜感激:
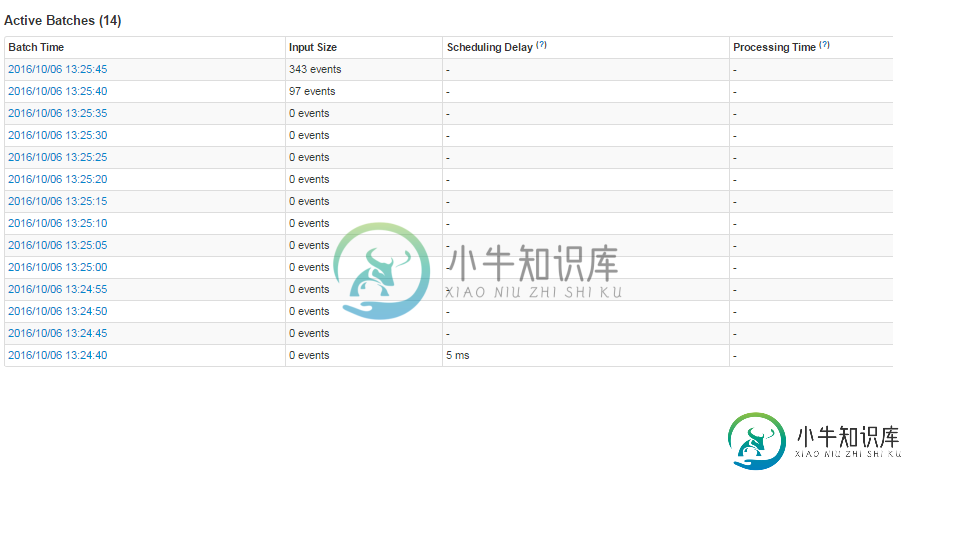
- 这是意料之中的吗?为什么批处理不处理任何数据(kafka主题是连续接收消息)时会创建批处理。
- 还有第二件事让人摸不着头脑。将spark进程关闭一分钟并重新启动后,kafka主题中有4800条(80*60)消息等待处理。看起来这些消息正在被处理,但我在UI上没有看到任何输入大小为4800 的批处理
共有1个答案
这是意料之中的吗?为什么在批处理不处理任何数据的情况下要创建批处理
这就是Sparks容错语义所保证的,即使您的服务失败了,它也可以从上一个处理的时间点恢复并继续处理。Spark正在读取检查点数据,并启动恢复过程,直到它到达当前时间点。Spark不知道0事件批次,因此没有做任何事情来优化它们。
看起来这些消息正在被处理,但我在UI上没有看到任何输入大小为4800的批处理
-
当streaming Spark DStreams作为来自Kafka源的消费者时,可以检查Spark上下文,因此当应用程序崩溃(或受到的影响)时,应用程序可以从上下文检查点恢复。但如果应用程序“意外地部署了错误的逻辑”,您可能想要倒回到最后一个主题+分区+偏移量,以重播某个Kafka主题的分区偏移量位置的事件,这些位置在“错误逻辑”之前正常工作。当检查点生效时,流式应用程序如何被重绕到最后的“好点
-
我在生产中遇到检查点问题,当 spark 无法从_spark_metadata文件夹中找到文件时 已经提出了一个问题,但目前还没有解决方案。 在检查点文件夹中,我看到批次29尚未提交,所以我可以从检查点的、和/或中删除一些内容,以防止火花因缺少文件而失败?
-
为什么以及何时会选择将Spark流媒体与Kafka结合使用? 假设我有一个系统通过Kafka每秒接收数千条消息。我需要对这些消息应用一些实时分析,并将结果存储在数据库中。 我有两个选择: > < li> 创建我自己的worker,该worker从Kafka读取消息,运行分析算法并将结果存储在DB中。在Docker时代,只需使用scale命令就可以轻松地在我的整个集群中扩展这个工作线程。我只需要确保
-
它没有任何错误,我得到以下错误时,我运行火花提交,任何帮助都非常感谢。谢谢你抽出时间。 线程“main”java.lang.noClassDeffounderror:org/apache/spark/streaming/kafka/kafkautils在kafkasparkstreaming.sparkstreamingtest(kafkasparkstreaming.java:40)在kafka
-
我正在使用spark structured streaming(2.2.1)来消费来自Kafka(0.10)的主题。 我的检查点位置设置在外部HDFS目录上。在某些情况下,我希望重新启动流式应用程序,从一开始就消费数据。然而,即使我从HDFS目录中删除所有检查点数据并重新提交jar,Spark仍然能够找到我上次使用的偏移量并从那里恢复。偏移量还在哪里?我怀疑与Kafka消费者ID有关。但是,我无法
-
我想知道Kafka分区是如何在从executor进程内部运行的SimpleConsumer之间共享的。我知道高水平的Kafka消费者是如何在消费者群体中的不同消费者之间分享利益的。但是,当Spark使用简单消费者时,这是如何发生的呢?跨计算机的流作业将有多个执行程序。