
分散Kafka流中的消息

我试图找出最好的方式将我的数据扇出到单独的占位符中,以供其他处理的数据使用
用例我正在接收Kafka主题中几个脚本(约2000只股票)的股票数据。我希望能够单独在所有脚本上运行KPI(KPI就像应用于输入数据以获取KPI值的公式)。
我能想到的选项
>
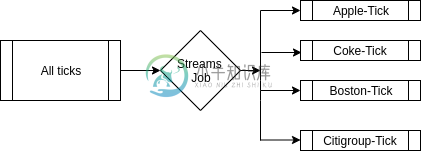
将所有刻度数据保存在一个主题中,并使用Custom分区器按脚本名称对其进行分区。这有助于保持低主题计数和系统易于管理。但是所有消费者都需要丢弃大量记录以获取导致延迟的数据块。(换句话说,希望在Apple Tick上运行KPI的作业将需要订阅公共主题并丢弃来自所有其他脚本的刻度)

请告诉我是否有更好的方法,如果没有,请选择哪一种。另一个重要的考虑因素是,每个KPI都会将数据写回Kafka主题,以供规则引擎进一步使用
共有1个答案

在我看来:
1.基于脚本名称的主题扇出
优点
- 单个占位符的完全控制。您可以为每个源设置不同的复制、持久性和分区号参数
- 方便的健康检查。您可以轻松检查某个来源(即花旗集团)是否比其他来源获得更多的传入数据,或者从影响流程的特定来源删除数据等
- 独立比例。与前一点相关,如果您对每个源有不同的主题,这将有助于解决扩展问题。在第二种方法中,您只需要与一个主题的分区数量挂钩,以扩展您的消费者(可能是您刚刚达到消费者的最大数量)。使用第一种方法,您可以创建不同的主题(从而创建不同的分区),允许您在需要的地方(主题)启动消费者,或者增加单个主题的分区数量
欺骗
- 许多主题可能会导致大量的复制、持久性、偏移量控制等:代理的更多工作
- 。。。以及维护人员:)
2.将所有勾号数据保存在单个主题中,并使用CustomPartitioner按脚本名称对其进行分区
优点
- 更少的代理/维护人员饱和。所有数据都在一个主题上,在这个主题中,您“仅”必须控制分区
欺骗
>
您的分区器必须不断更新(如果有新的源进来,如果分区数增加,…),这可能会成为一项繁琐的手工任务。
忘记对源的不同管理:所有传入数据,无论其来源如何,都将共享相同的主题参数,例如保留时间;您将无法选择将某些源比其他源更持久化,或者(轻松地)将其分布在更多的分区中,等等。
较小、较轻的数据源将受到较大数据源的影响,因为所有数据都在同一主题中处理。如果你建立消费者群体,“小”来源的消费者将不得不丢弃更多的信息,以获取他们自己的信息。另一方面,如果您不启动消费者组并手动分配消费者,则需要手动增加主题的分区数量,将新分区分配给大型源。这将涉及到您的分区器和您的消费者的分配的不断变化。
无论如何,如果您控制了源脚本,您可以摆脱第二个主题/主题,因为您可以在源主题中创建相同的逻辑,并避免数据的移动(我相信没有转换,只是从一个地方移动到其他地方)从源主题到最终主题。这在第二种方法中更明显(为什么不在第一个主题上进行分区?)
希望能有所帮助,其中一些完全是主观的
-
我最近看到了这篇关于Apache Kafka文档的文章,内容涉及如何处理Kafka流中的无序消息 https://kafka.apache.org/21/documentation/streams/core-concepts#streams_out_of_ordering 有人能给我解释一下下面这句话背后的原因吗: 在主题分区中,记录的时间戳可能不会随着它们的偏移量单调地增加。由于Kafka流总是
-
目前我们正在使用:Kafka Streams API(版本1.1.0)来处理来自Kafka集群的消息(3个代理,每个主题3个分区,复制因子为2)。安装的Kafka版本为1.1.1。 最终用户向我们报告数据消失的问题。他们报告说,突然之间他们看不到任何数据(例如,昨天他们可以在UI中看到n条记录,而第二天的morning table是空的)。我们检查了这个特定用户的changelog主题,看起来很奇
-
我开发了一个Python Kafka生成器,它将多个json记录作为nd-json二进制字符串发送到一个Kafka主题。然后,我尝试用PySpark在Spark结构化流媒体中读取这些消息,如下所示:
-
我有一个Apache Kafka2.6制作人,它写的主题-A(TA)。我还有一个Kafka streams应用程序,它使用TA并写入topic-B(TB)。在streams应用程序中,我有一个自定义的时间戳提取器,它从消息负载中提取时间戳。 对于我的一个失败处理测试用例,我在应用程序运行时关闭了Kafka集群。 当生产者应用程序试图向TA写入消息时,它无法写入,因为集群已关闭,因此(我假设)缓冲了
-
如何使用新的Spring Cloud Stream Kafka功能模型发送消息? 不推荐的方式是这样的。 但是我如何以函数式风格发送消息呢? 应用yml公司 我会自动连接MessageChannel,但对于process、process-out-0、output或类似的东西,没有MessageChannel Bean。或者我可以用供应商Bean发送消息吗?谁能给我举个例子吗?谢谢!
-
是否可以记录来自流函数的入站消息?有什么拦截器能让我这么做吗?