
Kafka聚合事件

我有一个条目主题,其中我从传感器接收数据。通常,我收到的数据如下所示:
key : project-id
value: {id: 'A', value: 1}
为了稍后在拓扑中进行一些计算,我需要构建一个映射,其中包含从每个捕获者接收到的所有最后值。
关键字:项目id值:{
为了做到这一点,我在传感器主题和聚合主题之间进行了连接,连接的结果是聚合主题中的post。
------ 传感器(KStream)-|
| ---------- aggreg
-------聚合(KTable)---|
更新:以下是实现这种连接的java代码:
KStream<String, String> sensorsSource = streamsBuilder.stream(sensorTopicName, Consumed.with(Serdes.String(),
Serdes.String()));
KTable<String, String> aggSource = streamsBuilder.table(aggregateTopicName, Consumed.with(Serdes.String(), Serdes.String()));
sensorsSource.leftJoin(aggSource, this::updateSensorAggregatedRecord).to(aggregateTopicName, Produced.with(Serdes.String(), Serdes.String()));
问题是,当我们在传感器主题上快速发布新值时,有时会使用旧版本的aggreg KTable进行连接。您可以使用以下模式可视化问题:
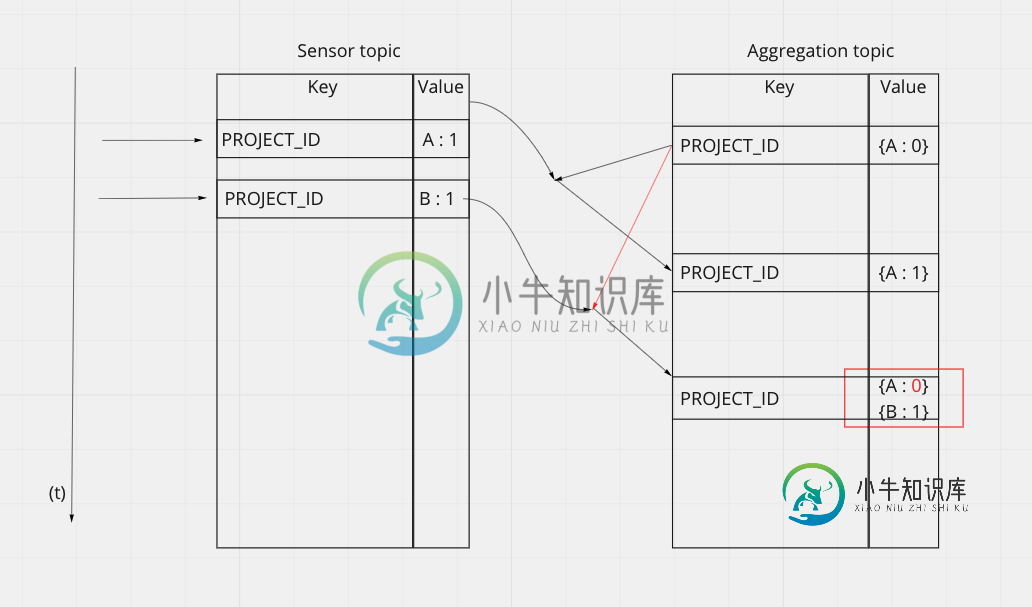
似乎当B事件到达时,Kafka在B事件发生的那一刻与相应的KTable状态进行了连接。而此时,ktable由于A事件而没有跟上应该做的修改。
有没有解决方案可以实现正确构建我的地图?
谢谢你的帮助问候CG
共有1个答案

这个解释很有帮助,但一些代码可能会更有用,无论如何,根据我对这个问题的理解,可能可行的方法是在聚合KTable上使用一个小的时间窗口,并有几毫秒的宽限期,这应该会起到作用,您希望进行多少窗口和宽限期取决于手头的业务案例。检查-
比如:
stram.groupByKey().windowedBy(TimeWindows.ofSizeAndGrace(Duration.ofMillis(10), Duration.ofMillis(100))...
-
当您的事件需要附加到更多侦听器或需要观察应用程序的某些功能并等待数据更新时,应使用事件聚合器。 Aurelia事件聚合器有三种方法。 publish方法将触发事件,并可供多个订阅者使用。 对于订阅事件,我们可以使用subscribe方法。 最后,我们可以使用dispose方法分离订阅者。 以下示例演示了这一点。 我们的视图将为三个功能中的每一个提供三个按钮。 app.html <template>
-
我有一个KStream,其中包含从主题到1的数据,如下所示: 和KTable,构造如下: 稍后,主题To2中出现以下消息: 现在,我希望我的KTable能够反映这些变化,并且看起来像这样: 但看起来是这样的: 我想我缩小了范围:显然聚合的只在第一次调用--之后聚合总是接收作为最后一个参数,例如。 其中,在第一次调用(通过初始值设定项创建)时为,但在第二次调用时为。 有什么想法吗? 编辑2 编辑3
-
我是事件采购的新手,但对于我们当前的项目,我认为这是一个非常有前途的选择,主要是因为审计跟踪。 有一件事我不是100%满意,那就是缺乏跨聚合的超越。请考虑以下问题: 我有一个订单,它在不同的机器上处理,在不同的车站。我们有集装箱,工人们把订单放进去,然后把它从一台机器运到另一台机器。 必须通过容器(具有唯一的条形码id)进行跟踪,订单本身无法识别。问题是:容器是重用的,需要锁定,因此没有工作人员可
-
我想连接两个主题流(左连接),并在连接的流上进行基于窗口的聚合。然而,聚合将某些消息计数两倍,因为在连接期间,根据正确主题中的延迟,某些消息将发出两倍。以下是POC的代码。 它是否可以修复以避免因连接而重复?
-
我有一个KTable,数据如下所示(key=>value),其中keys是客户ID,而value是包含一些客户数据的小型JSON对象: 我想对这个KTable做一些聚合,基本上保留每个的记录数。所需的KTable数据如下所示: 假设属于上面的组,她的生日使她进入了新的年龄组。支持第一个KTable的状态存储现在应该如下所示: 我希望得到的聚合KTable结果反映这一点。例如。 我可能过度概括了这里