《kafka》专题
-
 谈谈你对 Kafka 幂等的了解?
谈谈你对 Kafka 幂等的了解?本文向大家介绍谈谈你对 Kafka 幂等的了解?相关面试题,主要包含被问及谈谈你对 Kafka 幂等的了解?时的应答技巧和注意事项,需要的朋友参考一下 在之前的旧版本中,Kafka只能支持两种语义:At most once和At least once。At most once保证消息不会朝服,但是可能会丢失。在实践中,很有有业务会选择这种方式。At least once保证消息不会丢失,但是可能会
-
Kafka 新旧消费者的区别
本文向大家介绍Kafka 新旧消费者的区别相关面试题,主要包含被问及Kafka 新旧消费者的区别时的应答技巧和注意事项,需要的朋友参考一下 旧的 Kafka 消费者 API 主要包括:SimpleConsumer(简单消费者) 和 ZookeeperConsumerConnectir(高级消费者)。SimpleConsumer 名字看起来是简单消费者,但是其实用起来很不简单,可以使用它从特定的分区
-
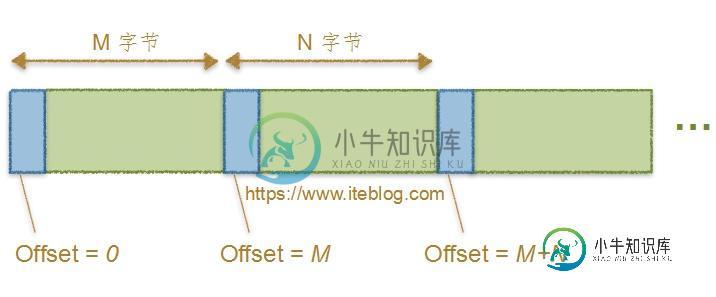 Kafka 偏移量的演变清楚吗?
Kafka 偏移量的演变清楚吗?本文向大家介绍Kafka 偏移量的演变清楚吗?相关面试题,主要包含被问及Kafka 偏移量的演变清楚吗?时的应答技巧和注意事项,需要的朋友参考一下 我在[《Apache Kafka消息格式的演变(0.7.x~0.10.x)》文章中介绍了 Kafka 几个版本的消息格式。仔细的同学肯定看到了在 MessageSet 中的 Message 都有一个 Offset 与之一一对应,本文将探讨 Kafka各
-
Kafka 是如何实现高吞吐率的?
本文向大家介绍Kafka 是如何实现高吞吐率的?相关面试题,主要包含被问及Kafka 是如何实现高吞吐率的?时的应答技巧和注意事项,需要的朋友参考一下 Kafka是分布式消息系统,需要处理海量的消息,Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失。kafka主要使用了以下几个方式实现了超高的吞吐率: 顺序读写; 零拷贝
-
如果我指定了一个offset,Kafka怎么查找到对应的消息?
本文向大家介绍如果我指定了一个offset,Kafka怎么查找到对应的消息?相关面试题,主要包含被问及如果我指定了一个offset,Kafka怎么查找到对应的消息?时的应答技巧和注意事项,需要的朋友参考一下 1.通过文件名前缀数字x找到该绝对offset 对应消息所在文件 2.offset-x为在文件中的相对偏移 3.通过index文件中记录的索引找到最近的消息的位置 4.从最近位置开始逐条寻找
-
kafka producer如何优化打入速度?
本文向大家介绍kafka producer如何优化打入速度?相关面试题,主要包含被问及kafka producer如何优化打入速度?时的应答技巧和注意事项,需要的朋友参考一下 增加线程 提高 batch.size 增加更多 producer 实例 增加 partition 数 设置 acks=-1 时,如果延迟增大:可以增大 num.replica.fetchers(follower 同步数据的线
-
Kafka中的消息是否会丢失和重复消费?
本文向大家介绍Kafka中的消息是否会丢失和重复消费?相关面试题,主要包含被问及Kafka中的消息是否会丢失和重复消费?时的应答技巧和注意事项,需要的朋友参考一下 要确定Kafka的消息是否丢失或重复,从两个方面分析入手:消息发送和消息消费。 1、消息发送 0---表示不进行消息接收是否成功的确认; 1---表示当Leader接收成功时确认; -1---表示Leader和Follower都接收成功
-
当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
本文向大家介绍当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?相关面试题,主要包含被问及当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?时的应答技巧和注意事项,需要的朋友参考一下 1)会在zookeeper中的/brokers/topics节点下创建一个新的topic节点,如:/broker
-
Kafka中是怎么体现消息顺序性的?
本文向大家介绍Kafka中是怎么体现消息顺序性的?相关面试题,主要包含被问及Kafka中是怎么体现消息顺序性的?时的应答技巧和注意事项,需要的朋友参考一下 kafka每个partition中的消息在写入时都是有序的,消费时,每个partition只能被每一个group中的一个消费者消费,保证了消费时也是有序的。 整个topic不保证有序。如果为了保证topic整个有序,那么将partition调整
-
Kafka 消费者是否可以消费指定分区消息?
本文向大家介绍Kafka 消费者是否可以消费指定分区消息?相关面试题,主要包含被问及Kafka 消费者是否可以消费指定分区消息?时的应答技巧和注意事项,需要的朋友参考一下 Kafa consumer消费消息时,向broker发出fetch请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer拥有了offset的控制权,可
-
Kafka创建Topic时如何将分区放置到不同的Broker中
本文向大家介绍Kafka创建Topic时如何将分区放置到不同的Broker中相关面试题,主要包含被问及Kafka创建Topic时如何将分区放置到不同的Broker中时的应答技巧和注意事项,需要的朋友参考一下 副本因子不能大于 Broker 的个数; 第一个分区(编号为0)的第一个副本放置位置是随机从 选择的; 其他分区的第一个副本放置位置相对于第0个分区依次往后移。也就是如果我们有5个 Broke
-
Kafka 高效文件存储设计特点
本文向大家介绍Kafka 高效文件存储设计特点相关面试题,主要包含被问及Kafka 高效文件存储设计特点时的应答技巧和注意事项,需要的朋友参考一下 Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。 通过索引信息可以快速定位message和确定response的最大大小。 通过index元数据全部映射到memor
-
Kafka中的事务是怎么实现的?
本文向大家介绍Kafka中的事务是怎么实现的?相关面试题,主要包含被问及Kafka中的事务是怎么实现的?时的应答技巧和注意事项,需要的朋友参考一下 事务,对于大家来说可能并不陌生,比如数据库事务、分布式事务,那么Kafka中的事务是什么样子的呢? 在说Kafka的事务之前,先要说一下Kafka中幂等的实现。幂等和事务是Kafka 0.11.0.0版本引入的两个特性,以此来实现EOS(exactly
-
Kafka 判断一个节点是否还活着有那两个条件?
本文向大家介绍Kafka 判断一个节点是否还活着有那两个条件?相关面试题,主要包含被问及Kafka 判断一个节点是否还活着有那两个条件?时的应答技巧和注意事项,需要的朋友参考一下 (1)节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连 接 (2)如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太久
-
Kafka 新建的分区会在哪个目录下创建?
本文向大家介绍Kafka 新建的分区会在哪个目录下创建?相关面试题,主要包含被问及Kafka 新建的分区会在哪个目录下创建?时的应答技巧和注意事项,需要的朋友参考一下 在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录, 这个参数可以配置多个目录,目录之间使用逗号分隔,通常这些目录是分布在不同的磁盘 上用于提高读写性能。 当然我们也可以配置 l