
谈谈你对 Kafka 幂等的了解?

在之前的旧版本中,Kafka只能支持两种语义:At most once和At least once。At most once保证消息不会朝服,但是可能会丢失。在实践中,很有有业务会选择这种方式。At least once保证消息不会丢失,但是可能会重复,业务在处理消息需要进行去重。、
Kafka在0.11.0.0版本支持增加了对幂等的支持。幂等是针对生产者角度的特性。幂等可以保证上生产者发送的消息,不会丢失,而且不会重复
如何实现幂等
HTTP/1.1中对幂等性的定义是:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同
Methods can also have the property of “idempotence” in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request.
实现幂等的关键点就是服务端可以区分请求是否重复,过滤掉重复的请求。要区分请求是否重复的有两点:
- 唯一标识:要想区分请求是否重复,请求中就得有唯一标识。例如支付请求中,订单号就是唯一标识
- 记录下已处理过的请求标识:光有唯一标识还不够,还需要记录下那些请求是已经处理过的,这样当收到新的请求时,用新请求中的标识和处理记录进行比较,如果处理记录中有相同的标识,说明是重复交易,拒绝掉
Kafka幂等性实现原理
为了实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。
- PID。每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是不可见的。
- Sequence Numbler。(对于每个PID,该Producer发送数据的每个<Topic, Partition>都对应一个从0开始单调递增的Sequence Number
Kafka可能存在多个生产者,会同时产生消息,但对Kafka来说,只需要保证每个生产者内部的消息幂等就可以了,所有引入了PID来标识不同的生产者。
对于Kafka来说,要解决的是生产者发送消息的幂等问题。也即需要区分每条消息是否重复。 Kafka通过为每条消息增加一个Sequence Numbler,通过Sequence Numbler来区分每条消息。每条消息对应一个分区,不同的分区产生的消息不可能重复。所有Sequence Numbler对应每个分区
Broker端在缓存中保存了这seq number,对于接收的每条消息,如果其序号比Broker缓存中序号大于1则接受它,否则将其丢弃。这样就可以实现了消息重复提交了。但是,只能保证单个Producer对于同一个<Topic, Partition>的Exactly Once语义。不能保证同一个Producer一个topic不同的partion幂等。
实现幂等前后对比
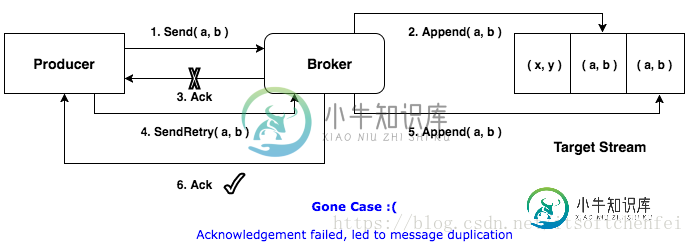
标准实现

发生重试时
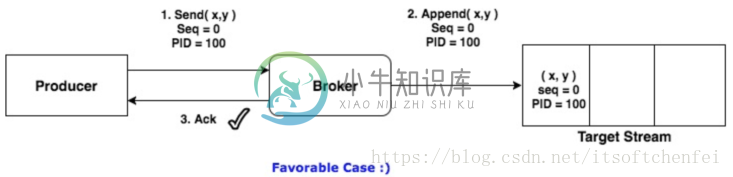
实现幂等之后
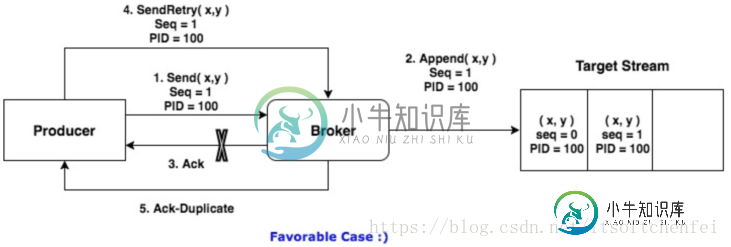
发生重试时
幂等性示例
生产者要使用幂等性很简单,只需要增加以下配置即可:
enable.idempotence=true
Properties props = new Properties();
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
props.put("acks", "all"); // 当 enable.idempotence 为 true,这里默认为 all
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
producer.send(new ProducerRecord(topic, "test");
Prodcuer 幂等性对外保留的接口非常简单,其底层的实现对上层应用做了很好的封装,应用层并不需要去关心具体的实现细节,对用户非常友好
幂等性实现生产者流程
此流程只展示了涉及生产者幂等性相关的重要操作
幂等性-生产者流程.png
这里重点关注幂等性相关的内容,首先,KafkaProducer启动时,会初始化一个 TransactionManager 实例,它的作用有以下几个部分:
- 记录本地的事务状态(事务性时必须)
- 记录一些状态信息以保证幂等性,比如:每个 topic-partition 对应的下一个 sequence numbers 和 last acked batch(最近一个已经确认的 batch)的最大的 sequence number 等;
- 记录 ProducerIdAndEpoch 信息(PID 信息)。
幂等性时,Producer 的发送流程如下: 1)调用kafkaProducer的send方法将数据添加到 RecordAccumulator 中,添加时会判断是否需要新建一个 ProducerBatch,这时这个 ProducerBatch 还是没有 PID 和 sequence number 信息的; 2)Producer 后台发送线程 Sender,在 run() 方法中,会先根据 TransactionManager 的 shouldResetProducerStateAfterResolvingSequences() 方法判断当前的 PID 是否需要重置,重置的原因是因为:如果有topic-partition的batch已经超时还没处理完,此时可能会造成sequence number 不连续。因为sequence number 有部分已经分配出去了,而Kafka服务端没有收到这部分sequence number 的序号,Kafka服务端为了保证幂等性,只会接受同一个pid的sequence number 等于服务端缓存sequence number +1的消息,所有这时候需要重置Pid来保证幂等性
synchronized boolean shouldResetProducerStateAfterResolvingSequences() {
/**
* 是否是事务即配置了Tid
* 如果是事务则不需重置Pid
*/
if (isTransactional())
// We should not reset producer state if we are transactional. We will transition to a fatal error instead.
return false;
for (Iterator<TopicPartition> iter = partitionsWithUnresolvedSequences.iterator(); iter.hasNext(); ) {
TopicPartition topicPartition = iter.next();
if (!hasInflightBatches(topicPartition)) {//没有该分区的消息在发送中
// The partition has been fully drained. At this point, the last ack'd sequence should be once less than
// next sequence destined for the partition. If so, the partition is fully resolved. If not, we should
// reset the sequence number if necessary.
/**
* 判断SequenceNo是否连续
* 如果连续的,就不需要重置Pid
*/
if (isNextSequence(topicPartition, sequenceNumber(topicPartition))) {
// This would happen when a batch was expired, but subsequent batches succeeded.
iter.remove();
} else {
// We would enter this branch if all in flight batches were ultimately expired in the producer.
log.info("No inflight batches remaining for {}, last ack'd sequence for partition is {}, next sequence is {}. " +
"Going to reset producer state.", topicPartition, lastAckedSequence(topicPartition), sequenceNumber(topicPartition));
return true;
}
}
}
return false;
}
3)Sender线程调用maybeWaitForProducerId()方法判断是否要申请Pid,如果需要,会阻塞直到成功申请到Pid
ProducerIdAndEpoch producerIdAndEpoch = null;
boolean isTransactional = false;
if (transactionManager != null) {//有事务或者启用幂等
//事务是否允许向此分区发送消息
if (!transactionManager.isSendToPartitionAllowed(tp))
break;
producerIdAndEpoch = transactionManager.producerIdAndEpoch();
if (!producerIdAndEpoch.isValid())
// we cannot send the batch until we have refreshed the producer id
break;
//是否支持事务
isTransactional = transactionManager.isTransactional();
/**
* 如果该分区的前面还有没发送完成的Batch,则需要跳过该分区的Batch,等待之前batch发送完成
*/
if (!first.hasSequence() && transactionManager.hasUnresolvedSequence(first.topicPartition))
break;
/**
* 该分区存在发送中的Batch,该Batch有Sequence,和first的不相等。则跳过、
*
* 也即first是个重试的Batch(因为它有Sequence),需要等待该分区发送中的Batch完成
*/
int firstInFlightSequence = transactionManager.firstInFlightSequence(first.topicPartition);
if (firstInFlightSequence != RecordBatch.NO_SEQUENCE && first.hasSequence()
&& first.baseSequence() != firstInFlightSequence)
break;
}
ProducerBatch batch = deque.pollFirst();
/**
* 校验当前batch是否已经设置了Sequence
* 如果没有,则需要设置batch的Sequence,增加对应分区的Next Sequence,将batch加入到inflightBatchesBySequence中
*/
if (producerIdAndEpoch != null && !batch.hasSequence()) {
//设置Batch的sequenceNumber 和isTransactional
batch.setProducerState(producerIdAndEpoch, transactionManager.sequenceNumber(batch.topicPartition), isTransactional);
//增加该分区的sequenceNumber,增加值为Batch中消息的个数
transactionManager.incrementSequenceNumber(batch.topicPartition, batch.recordCount);
log.debug("Assigned producerId {} and producerEpoch {} to batch with base sequence " +
"{} being sent to partition {}", producerIdAndEpoch.producerId,
producerIdAndEpoch.epoch, batch.baseSequence(), tp);
//加入到发送队列中
transactionManager.addInFlightBatch(batch);
}
batch.close();//关闭此batch,不可追加消息
size += batch.records().sizeInBytes();//累计size
ready.add(batch);//加到集合中,最后一起返回出去
batch.drained(now);//更新drainedMs时间戳
5)最后调用sendProduceRequest方法将消息发送出去
幂等性服务端相关的类
BatchMetadata
用来存储Batch的元数据, BatchMetadata类的几个重要的字段
- lastSeq:Batch中最后一条消息的seq
- lastOffset: Batch中最后一条消息的offset
- offsetDelta: 第一条消息和最后一条消息的offset之差 lastSeq-offsetDelta可以得到第一条消息的seq,lastOffset-offsetDelta可以得到第一条消息的offset
ProducerStateEntry
用于存储每个producerId对应的Batch,按照sequence从小到大进行排序,最小的作为头,最大的作为尾 ,每个producerId的队列失踪保持着最多5个Batch,如果超过5个了,就从头开始remove。 ProducerStateEntryl类的重要字段: producerId:生产者id,用服务端生成,生产者发送消息时会带上此字段 batchMetadata:Queue[BatchMetadata]类型,里面存放了服务端收到的该生产者最新的Batch,最多存放5个 producerEpoch: 生产者的年代,默认为-1
ProducerStateEntryl类的核心方法:addBatch()方法,往ProducerStateEntry中添加Batch,此方法首先会判断是否要更新epoch,如果epoch不一样,则会清空batchMetadata队列并更新最新的epoch,然后加batch添加到batchMetadata中,添加前也会先校验batchMetadata的元素个数是否等于ProducerStateEntry.NumBatchesToRetain,如果相等就剔除掉头部的BatchMetadata。代码如下:
def addBatch(producerEpoch: Short, lastSeq: Int, lastOffset: Long, offsetDelta:
Int, timestamp: Long): Unit = {
maybeUpdateEpoch(producerEpoch)//更新producerEpoch,如果producerEpoch不一样就清空队列中的Batch
addBatchMetadata(BatchMetadata(lastSeq, lastOffset, offsetDelta, timestamp))
}
def maybeUpdateEpoch(producerEpoch: Short): Boolean = {
if (this.producerEpoch != producerEpoch) {
batchMetadata.clear()//清空Batch
this.producerEpoch = producerEpoch//更新producerEpoch
true
} else {
false
}
}
private def addBatchMetadata(batch: BatchMetadata): Unit = {
if (batchMetadata.size == ProducerStateEntry.NumBatchesToRetain)
batchMetadata.dequeue()//去掉头部的Batch
batchMetadata.enqueue(batch)
}
findDuplicateBatch()方法用于校验新产生的消息是否是重复发送。遍历batchMetadata,如果新产生的Batch的firstSeq和lastSeq都和batchMetadata中缓存的某个Batch一样,说明是重复的,代码如下:
/**
* 查找重复的Batch
* 1)与缓存中的Batch,头和尾序号都一样的,说明是重复的Batch
*/
def findDuplicateBatch(batch: RecordBatch): Option[BatchMetadata] = {
if (batch.producerEpoch != producerEpoch)
None
else
batchWithSequenceRange(batch.baseSequence, batch.lastSequence)
}
def batchWithSequenceRange(firstSeq: Int, lastSeq: Int): Option[BatchMetadata] =
{
val duplicate = batchMetadata.filter { metadata =>
firstSeq == metadata.firstSeq && lastSeq == metadata.lastSeq
}
duplicate.headOption
}
ProducerAppendInfo
ProducerAppendInfo用于在追加的消息写到Log之前进行校验,主要对epoch、sequence number进行校验 currentEntry:ProducerStateEntry类型,就是pid对应的ProducerStateEntry中batchMetadata尾部对象,用于跟新追加的Batch做比较 validationType:校验的方式。不同的类型,校验的规则不一样
- ValidationType.None:什么也不用校验。如果请求来自非客户端(Kakfa内部),则就是这种类型
- ValidationType.EpochOnly:只校验Epoch。如果Topic是__consumer_offsets就是这种校验类型
- ValidationType.Full:检查ProducerEpoch和sequence number
核心方法就是maybeValidateAppend(),根据validationType做不同的校验
private def maybeValidateAppend(producerEpoch: Short, firstSeq: Int) = {
validationType match {
case ValidationType.None =>
case ValidationType.EpochOnly =>
checkProducerEpoch(producerEpoch)
case ValidationType.Full =>
checkProducerEpoch(producerEpoch)
checkSequence(producerEpoch, firstSeq)
}
}
checkProducerEpoch方法检查ProducerEpoch是否合法
private def checkProducerEpoch(producerEpoch: Short): Unit = {
if (producerEpoch < updatedEntry.producerEpoch) {
throw new ProducerFencedException(s"Producer's epoch is no longer valid.
There is probably another producer " +
s"with a newer epoch. $producerEpoch (request epoch),
${updatedEntry.producerEpoch} (server epoch)")
}
}
checkSequence方法是一个跟幂等性很重要的方法,此方法就是校验sequence number的。有以下几个判断规则
- 1)如果producerEpoch更新了,则追加的Batch里的appendFirstSeq必须是0
- 2)当currentLastSeq为-1时,说明此生产者还没有成功追加过消息,appendFirstSeq也必须是0
- 3)appendFirstSeq = currentLastSeq+1,或者当currentLastSeq达到Int的最大值Int.MaxValue时,appendFirstSeq为0
private def checkSequence(producerEpoch: Short, appendFirstSeq: Int): Unit = {
/**
* 如果producerEpoch更新了,appendFirstSeq必须从0开始
*/
if (producerEpoch != updatedEntry.producerEpoch) {
if (appendFirstSeq != 0) {
if (updatedEntry.producerEpoch != RecordBatch.NO_PRODUCER_EPOCH) {
throw new OutOfOrderSequenceException(s"Invalid sequence number for new epoch: $producerEpoch " +
s"(request epoch), $appendFirstSeq (seq. number)")
} else {
throw new UnknownProducerIdException(s"Found no record of producerId=$producerId on the broker. It is possible " +
s"that the last message with the producerId=$producerId has been removed due to hitting the retention limit.")
}
}
} else {
val currentLastSeq = if (!updatedEntry.isEmpty)
updatedEntry.lastSeq
else if (producerEpoch == currentEntry.producerEpoch)
currentEntry.lastSeq
else
RecordBatch.NO_SEQUENCE
//currentLastSeq为-1时,说明该生产者还没有上送成功过任何消息,appendFirstSeq必须从0开始
if (currentLastSeq == RecordBatch.NO_SEQUENCE && appendFirstSeq != 0) {
// the epoch was bumped by a control record, so we expect the sequence number to be reset
throw new OutOfOrderSequenceException(s"Out of order sequence number for producerId $producerId: found $appendFirstSeq " +
s"(incoming seq. number), but expected 0")
} else if (!inSequence(currentLastSeq, appendFirstSeq)) {//校验Sequence是否是连续的
throw new OutOfOrderSequenceException(s"Out of order sequence number for producerId $producerId: $appendFirstSeq " +
s"(incoming seq. number), $currentLastSeq (current end sequence number)")
}
}
}
private def inSequence(lastSeq: Int, nextSeq: Int): Boolean = {
nextSeq == lastSeq + 1L || (nextSeq == 0 && lastSeq == Int.MaxValue)
}
ProducerStateManager
用来管理Producer的状态,里面存储了各个生产者与ProducerStateEntry的对应关系。每个ProducerStateManager对应一个TopicPartition
producers:用于存储生产者与ProducerStateEntry的对应关系,key为pid,value为ProducerStateEntry prepareUpdate()方法返回ProducerAppendInfo对象,用于在写到Log之前校验消息
def prepareUpdate(producerId: Long, isFromClient: Boolean): ProducerAppendInfo =
{
val validationToPerform =
if (!isFromClient)
ValidationType.None
else if (topicPartition.topic == Topic.GROUP_METADATA_TOPIC_NAME)
ValidationType.EpochOnly
else
ValidationType.Full
//从队列中取出最近的ProducerStateEntry
val currentEntry =
lastEntry(producerId).getOrElse(<u>ProducerStateEntry.empty(producerId)</u>)
new ProducerAppendInfo(producerId, currentEntry, validationToPerform)
}
当消息写入到Log后,调用update方法,更新生产者状态信息
def update(appendInfo: ProducerAppendInfo): Unit = {
if (appendInfo.producerId == RecordBatch.NO_PRODUCER_ID)
throw new IllegalArgumentException(s"Invalid producer id ${appendInfo.producerId} passed to update " +
s"for partition $topicPartition")
trace(s"Updated producer ${appendInfo.producerId} state to $appendInfo")
val updatedEntry = appendInfo.toEntry
producers.get(appendInfo.producerId) match {
case Some(currentEntry) =>
currentEntry.update(updatedEntry)
case None =>
producers.put(appendInfo.producerId, updatedEntry)
}
appendInfo.startedTransactions.foreach { txn =>
ongoingTxns.put(txn.firstOffset.messageOffset, txn)
}
}
幂等性实现服务端流程
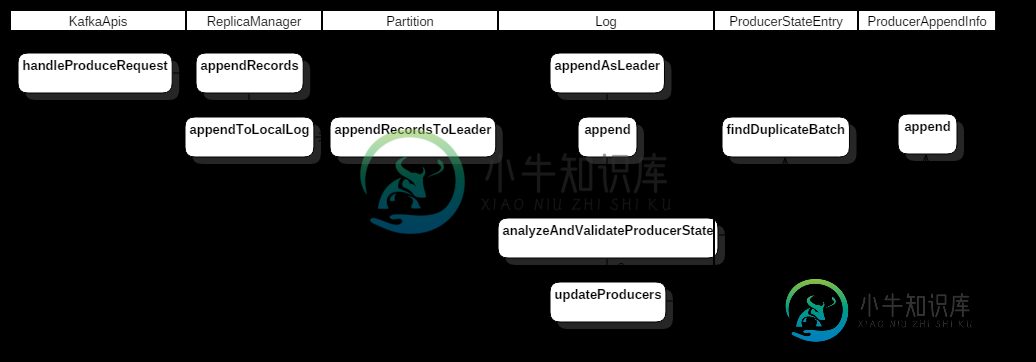
幂等性-服务端流程.png
如前面途中所示,当 Broker 收到 ProduceRequest 请求之后,会通过 handleProduceRequest() 做相应的处理,其处理流程如下(这里只讲述关于幂等性相关的内容):
1)如果请求是事务请求,检查是否对 TXN.id 有 Write 权限,没有的话返回TRANSACTIONAL_ID_AUTHORIZATION_FAILED; 2)如果请求设置了幂等性,检查是否对 ClusterResource 有 IdempotentWrite 权限,没有的话返回 CLUSTER_AUTHORIZATION_FAILED; 3)验证对 topic 是否有 Write 权限以及 Topic 是否存在,否则返回 TOPIC_AUTHORIZATION_FAILED 或 UNKNOWN_TOPIC_OR_PARTITION 异常; 4)检查是否有 PID 信息,没有的话走正常的写入流程; 5)LOG 对象会在 analyzeAndValidateProducerState() 方法先根据 batch 的 sequence number 信息检查这个 batch 是否重复(server 端会缓存 PID 对应这个 Topic-Partition 的最近5个 batch 信息),如果有重复,这里当做写入成功返回(不更新 LOG 对象中相应的状态信息,比如这个 replica 的 the end offset 等); 6)有了 PID 信息,并且不是重复 batch 时,在更新 producer 信息时,会做以下校验:
- 检查该 PID 是否已经缓存中存在(主要是在 ProducerStateManager 对象中检查);
- 如果不存在,那么判断 sequence number 是否 从0 开始,是的话,在缓存中记录 PID 的 meta(PID,epoch, sequence number),并执行写入操作,否则返回 UnknownProducerIdException(PID 在 server 端已经过期或者这个 PID 写的数据都已经过期了,但是 Client 还在接着上次的 sequence number 发送数据);
- 如果该 PID 存在,先检查 PID epoch 与 server 端记录的是否相同;
- 如果不同并且 sequence number 不从 0 开始,那么返回 OutOfOrderSequenceException 异常;
- 如果不同并且 sequence number 从 0 开始,那么正常写入;
- 如果相同,那么根据缓存中记录的最近一次 sequence number(currentLastSeq)检查是否为连续(会区分为 0、Int.MaxValue 等情况),不连续的情况下返回 OutOfOrderSequenceException 异常。
-
本文向大家介绍谈谈你对 Kafka 事务的了解?相关面试题,主要包含被问及谈谈你对 Kafka 事务的了解?时的应答技巧和注意事项,需要的朋友参考一下 为什么要提供事务机制 Kafka事务机制的实现主要是为了支持 即正好一次语义 操作的原子性 有状态操作的可恢复性 《Kafka背景及架构介绍》一文中有说明Kafka在0.11.0.0之前的版本中只支持和语义,尚不支持语义。 但是在很多要求严格的场景
-
本文向大家介绍请你谈谈对SOAP、WSDL、UDDI的了解?相关面试题,主要包含被问及请你谈谈对SOAP、WSDL、UDDI的了解?时的应答技巧和注意事项,需要的朋友参考一下 考察点:协议&语言 参考回答: - SOAP:简单对象访问协议(Simple Object Access Protocol),是Web Service中交换数据的一种协议规范。 - WSDL:Web服务描述语言(Web Se
-
本文向大家介绍谈谈对html5的了解相关面试题,主要包含被问及谈谈对html5的了解时的应答技巧和注意事项,需要的朋友参考一下 1.良好的移动性,以移动设备为主。 2.响应式设计,以适应自动变化的屏幕尺寸 3.支持离线缓存技术,webStorage本地缓存 4.新增canvas,video,audio等新标签元素。新增特殊内容元素:article,footer,header,nav,section
-
本文向大家介绍谈谈你对闭包的理解?相关面试题,主要包含被问及谈谈你对闭包的理解?时的应答技巧和注意事项,需要的朋友参考一下 说明: bar在foo函数的代码块中定义。我们称bar是foo的内部函数。 在bar的局部作用域中可以直接访问foo局部作用域中定义的m、n变量。 简单的说,这种内部函数可以使用外部函数变量的行为,就叫闭包。 闭包的意义与应用
-
本文向大家介绍请谈谈你对JVM的理解?相关面试题,主要包含被问及请谈谈你对JVM的理解?时的应答技巧和注意事项,需要的朋友参考一下 Java虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。 什么是字节码?采用字节码的好处是什么? 在 Java 中,JVM可以理解的代码就叫做(
-
本文向大家介绍谈谈你对多态的理解?相关面试题,主要包含被问及谈谈你对多态的理解?时的应答技巧和注意事项,需要的朋友参考一下 多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在程序运行期间才能决定。因为在程序运行时才确定具体的类,这样