《kafka》专题
-
如果抵消在Kafka中被破坏了会发生什么?
我们如何处理抵消腐败? 我想把偏移量日志保存在其他地方,或者拍摄偏移量的快照。我怎么能这么做?
-
具有相同组id的Kafka用户线程使用相同记录
我需要在多个线程中使用来自Kafka分区的记录,每个线程上有唯一的记录要处理。我有以下代码,我不知道是什么错误 结果 应为:
-
Kafka划分到Kafka消费者/消费者群体的映射
我正在阅读Kafka常见问题解答,他们如下所示。 •每个分区不会被每个使用者组中的多个使用者线程/进程使用。这允许每个进程以单线程方式使用,以保证分区内的使用者的顺序(如果我们将有序消息分割成一个分区并将它们传递给多个使用者,即使这些消息是按顺序存储的,它们有时也会被无序地处理)。 有没有可能,
-
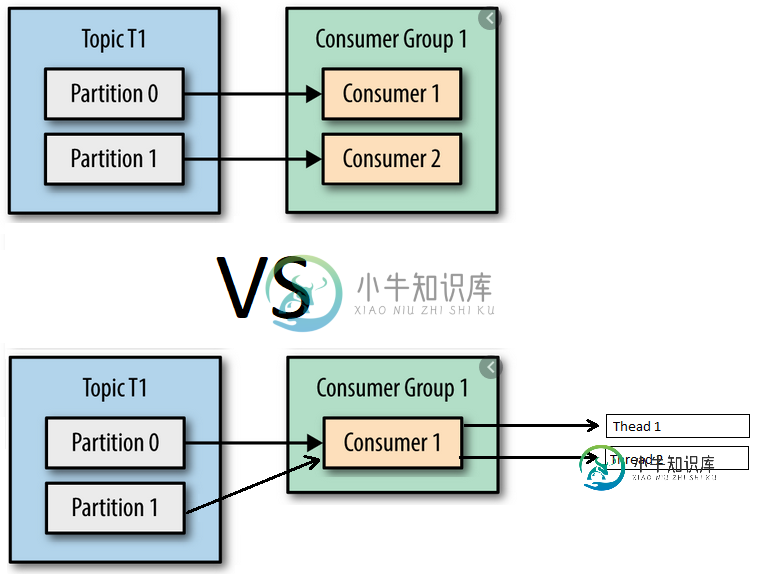 Kafka使用者/分区与线程/分区关系
Kafka使用者/分区与线程/分区关系我对Apache Kafka是新手,我试图理解以下两个方面的区别: 创建属于同一组id的两个使用者,这些使用者来自同一主题的两个分区。 用两个线程创建一个使用者,这些线程来自同一主题的两个分区。 在第一种方法中,我实际上理解的是,每个使用者将只使用与之“相关”的分区的消息,因为这两个使用者属于同一个组。 因此,在下面的示例中,可能会发生一些不同的情况: Thread1使用AAAA和CCCC/Thr
-
Kafka消费绩效
我的Kafka集群有下一个配置。 Kafka版本集群(V1.1.0)3个代理 一个主题(“FARA”),包含5个分区和3个副本 每个分区中有10000000条消息。总共50.000.0000 我使用的是Kafka-Consumer-Perf,测试用的是下面使用ConsumerPerformance的decro。 null 我定期运行下面的命令 ./kafka-run-class.sh kafka.
-
Kafka消费者-消费者进程和线程与主题分区的关系是什么
现在,让我们考虑另一个场景(我没有尝试过,但我很好奇),在这个场景中,我启动了两个使用者进程和,这两个进程都具有相同的组,并且它们都是一个单线程进程。现在我的问题是: > 在这种情况下,两个独立的使用者进程(在同一个组下)将如何与分区相关?与上面的单进程多线程场景有何不同? 一般来说,使用者线程或进程如何与主题中的分区映射/相关? 关于将消费者实现为进程与线程,我在这里遗漏了什么微妙的事情吗?提前
-
Kafka(kafka-node)使用者组接收来自所有分区的消息
我有一个名为“test-topic”的主题,有3个分区。 当我启动一个将group-id设置为“test-group”的使用者(consumer-1)时,它连接并读取主题上的所有分区。到目前为止还好。 当我在同一个组中启动另一个消费者(consumer-2)时,问题就出现了。我希望在两个消费者之间划分分区时能够重新平衡,例如,消费者-1得到分区0和2,消费者-2得到分区1。这种情况不会发生,当然我
-
如果消费者更多是分区,kafka消费者如何工作
谁能请解释和指导我链接或资源阅读关于Kafka消费者如何在下面的场景下工作。 > 一个有5个消费者的消费者组和3个分区的主题(Kafka是如何决定的) 一个消费者组有5个消费者,主题有10个分区(kafka如何分担负载) 两个消费者组和两个服务器的kafka集群,其中一个主题被划分在节点1和节点2之间,当来自不同组的消费者订阅到一个分区时,如何避免重复。 上面可能不是配置kafka时的最佳实践,但
-
Kafka:多个实例中的单一消费者群体
null null 使用简单消费者或低级消费者可以控制分区,但如果一个实例宕机,其他三个实例将不会处理来自第一个实例中使用的分区的消息
-
用于至少一次消息传递的Kafka分区和消费者组
我试图提出一个设计,使用Kafka为多个处理代理并行处理来自Kafka主题的消息。 null 或者还有什么我遗漏的地方可能有助于我对这一点的理解?
-
在Camel-Kafka中创建并发的Kafka消费者
我使用的是camel-kafka版本。以下是KafkaURI: 请注意,我在URI选项中使用了。但是,当我一次将多条消息发布到主题时(全部发布到同一个分区),kafka使用者将依次接收这些消息。怎样才能同时接收到这些信息? 我正在寻找如下的解决方案: 是我用来从ibm MQ中同时读取的内容
-
多重消费者Spring Kafka
问题是Spring Kafka侦听器只配置了主题名。 我似乎可以让Kafka产生100个消费者来处理来自“队列”(日志)的消息。怎么能做到呢?
-
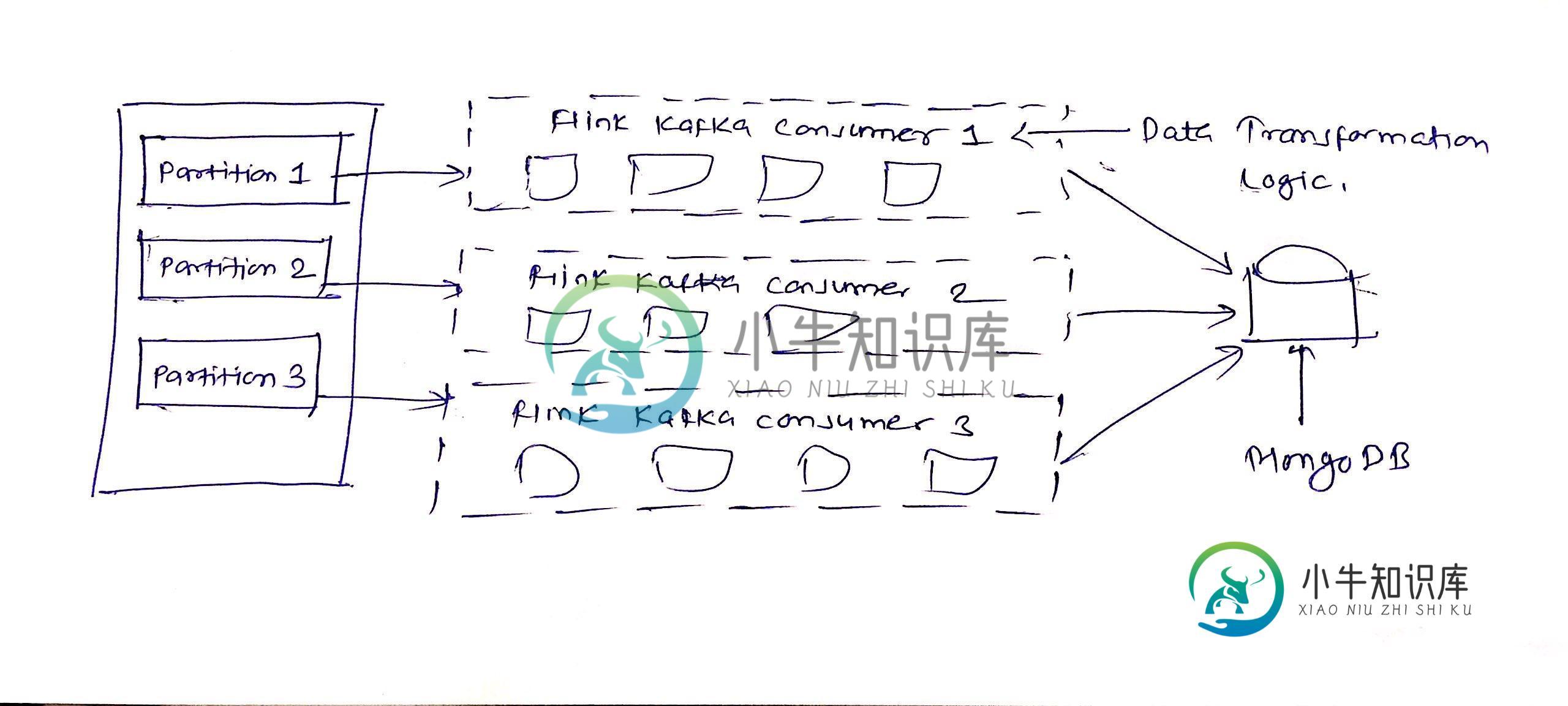 分区专用flink kafka使用者
分区专用flink kafka使用者我使用flink和Kafka创建了一个流媒体程序,用于流媒体mongodb oplog。根据与Flink支持团队的讨论,流的顺序不能通过kafka分区来保证。我已经创建了N个kafka分区,并希望每个分区创建N个flink kafka消费者,所以流的顺序应该至少在特定的分区中保持。请建议我是否可以创建分区特定的flink kafka消费者? 我正在使用env.setParallelism(N)进行
-
KafKa分区器类,使用键将消息分配给主题内的分区
我对Kafka是新的,所以道歉,如果我听起来很愚蠢,但我目前所理解的是…消息流可以定义为主题,就像类别一样。并且每个主题被分成一个或多个分区(每个分区可以有多个副本)。所以它们是平行的 他们说Kafka的主要网站 生成器能够选择将哪个消息分配给主题中的哪个分区。这可以通过循环的方式简单地平衡负载,也可以根据某个语义分区函数(例如基于消息中的某个键)来完成。 在0.8 beta版中创建produce
-
Kafka消费者-Java客户端
我在kafka消费者文档中看到了这个注释-