《pytorch》专题
-
pytorch-损失。backward()和优化器。是否在评估模式下使用batch Normal图层执行步骤()?
我有一个ResNet-8网络,我正在用于图像上的域适应项目,基本上我已经在数据集上训练了网络,现在我想在另一个模拟实时环境的数据集上评估它,我试图一次预测一个图像,但有趣的部分来了: 我想对目标数据集进行评估的方法是,对每幅图像,在训练模式下向前传递,以便更新批次规范层统计信息(使用torch.no\u grad(),因为我不想更新网络参数,而只想“适应”批次规范层),然后在评估模式下进行另一次前
-
Keras的BatchNormalization和PyTorch的BatchNormal2D之间的区别?
我有一个在Keras和PyTorch中实现的小型CNN示例。当我打印这两个网络的摘要时,可训练参数的总数是相同的,但参数总数和批量规范化的参数数量不匹配。 以下是CNN在Keras的实施情况: 为上述模型打印的摘要是: 下面是PyTorch中相同模型架构的实现: 以下是上述模型摘要的输出: 正如您在上面的结果中看到的,Keras中的批处理归一化比PyTorch有更多的参数(确切地说是2倍)。那么上
-
pytorch线性方法中的多维输入?
在建立一个简单的感知器神经网络时,我们通常将输入格式为的二维矩阵传递给一个二维权重矩阵,类似于这个简单的神经网络的numpy。我总是假设一个神经网络的感知器/密集/线性层只接受一个2D格式的输入并输出另一个2D输出。但是最近我遇到了这个pytorch模型,其中一个线性层接受一个3D输入张量并输出另一个3D张量()。 这些就是我的问题, 上述神经网络是否有效?这就是模型是否能够正确地训练? 即使在传
-
Pytorch Facenet MTCNN图像输出
我正在用facenet pytorch做一个人脸识别应用(https://github.com/timesler/facenet-pytorch)在python中使用两种方法。 第一种方法代码- 在这个代码中,我从给定的图像中提取人脸,并获得用于识别人脸的512编码。 在本例中,我使用了两个不同的面,并绘制了面之间的距离 它工作得很好... 第二种方法代码- 在这段代码中,我通常先获得面坐标,然后
-
利用PyTorch进行深度学习:理解神经网络示例
下文作如下说明: 让我们尝试一个随机的32x32输入。注:此网的预期输入大小(LeNet)为32x32。若要在MNIST数据集中使用此网络,请将数据集中的图像大小调整为32x32。 问题1:为什么图像需要32x32(我假设这意味着32像素乘32)? 在第一个卷积层,我们从一个输入通道到六个输入通道,这对我来说是有意义的。您只需将六个内核应用于单个输入通道,即可得到六个输出通道。从六个输入通道到十六
-
在Docker中访问Pytorch模型的GPU
我开发了一个机器学习模型,并将其与Flask应用程序集成。当我尝试为应用程序运行 docker 映像时,它显示我没有 GPU 访问权限。我应该如何编写一个 Docker 文件,以便我可以在容器内使用“cuda GPU”?下面是泊坞文件的当前状态。 来自蟒蛇:3.9 工作目录/myapp 补充。/myapp 运行pip3 install -r requirements.txt 复制… CMD["py
-
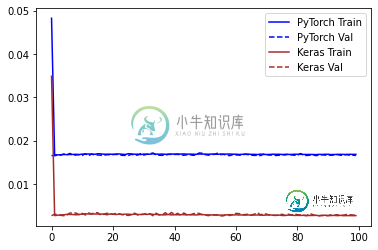 与相同的Keras模型(使用Adam优化器)相比,PyTorch的误差高出400%
与相同的Keras模型(使用Adam优化器)相比,PyTorch的误差高出400%TLDR: 一个简单的(单隐藏层)前馈Pytorch模型被训练来预测函数的性能大大低于使用Keras构建/训练的相同模型。为什么会这样,可以做些什么来减轻性能差异? 在训练回归模型时,我注意到PyTorch的性能大大低于使用Keras构建的相同模型。 这种现象以前已经被观察和报道过: > 相同的模型在pytorch上产生的结果比在张量流上更差 pytorch中的CNN模型比Tensoflowflo
-
为什么Keras在相同的网络配置下比Pytorch表现更好?
最近,我比较了Keras版本和Pytorch版本在同一数据集上的unet实现。但是,使用Keras,10个纪元后损失持续下降,准确率更高,而使用Pytorch,10个纪元后损失下降不均匀,准确率更低。有人遇到过这样的问题并有任何答案吗? 最终的pytorch训练过程如下所示: 2019-12-15 18:14:20 纪元:9 迭代:1214/1219 损失:0.464673 acc:0.58171
-
在 PyTorch 中,重复增加和减少精度是否正常?
我是PyTorch新手,目前正在做一个迁移学习的简单代码。当我训练我的模型时,我在准确性和损失的增加和减少之间得到一个大的变化。我对网络进行了50个纪元的训练,下面是结果: 有一些时期比其他时期具有更好的准确性和损失。然而,该模型在以后的时期丢失了它们。据我所知,准确性应该提高每一个时代。我是不是把训练代码写错了?如果不是,那这正常吗?有什么办法解决吗?是否应该保存先前的精度,并且只有在下一个历元
-
pytorch RNN损耗没有减少,验证精度保持不变
我在文本分类任务中使用Pytorch GRU训练模型(输出维度为5)。我的网络实现如下代码所示。 我用的是nn。损失函数的CrossEntropyLoss()和optim。SGD for optimizer。损失函数和优化器的定义是这样给出的。 我的培训程序大致如下所示。 当我训练这个模型时,验证准确性和损失是这样报告的。 它表明验证损失在第9个epoch之后不会减少,并且验证准确性自第一个epo
-
PyTorch:RNN,TensorBoard,部署PyTorch,数据增强
RNN的起因:现实世界中,很多元素都是相互连接的,比如室外的温度是随着气候的变化而周期性的变化的、我们的语言也需要通过上下文的关系来确认所表达的含义。但是机器要做到这一步就相当得难了。因此,就有了现在的循环神经网络,它的本质是:拥有记忆的能力,并且会根据这些记忆的内容来进行推断。因此,他的输出就依赖于当前的输入和记忆。
-
PyTorch:数据加载,数学原理,猫鱼分类,CNN,预训练,迁移学习
PyTorch开发了与数据交互的标准约定,所以能一致地处理数据,而不论处理图像、文本还是音频。与数据交互的两个主要约定是数据集(dataset)和数据加载器(dataloader)。数据集是一个Python类,使我们能获得提供给神经网络的数据。数据加载器则从数据集向网络提供数据。
-
PyTorch:环境搭建,张量概念,梯度计算,CIFAR-10分类,MINIS数字识别
Torch是一个与Numpy类似的张量(Tensor)操作库,与Numpy不同的是Torch对GPU支持的很好,Lua是Torch的上层包装。 PyTorch和Torch使用包含所有相同性能的C库:TH, THC, THNN, THCUNN,并且它们将继续共享这些库。其实PyTorch和Torch都使用的是相同的底层,只是使用了不同的上层包装语言。LUA虽然快,但是太小众了,所以才会有PyTorch(Python+Torch)的出现。
-
 PyTorch 自然语言处理
PyTorch 自然语言处理PyTorch 自然语言处理(Natural Language Processing with PyTorch 中文版)
-
 PyTorch 1.0 中文文档 & 教程
PyTorch 1.0 中文文档 & 教程PyTorch 是一个基于 python 的科学计算包,主要针对两类人群: 作为 NumPy 的替代品,可以利用 GPU 的性能进行计算 作为一个高灵活性、速度快的深度学习平台