《架构思维》专题
-
需要向图形QL视图提供一个架构
我正在按照本教程将 Graphql 与 Django 集成,当我在本地机器上点击 graphql URL 时,我根据该教程执行了所有操作 http://localhost:8000/graphql 我得到以下错误 断言错误在 /graphql 需要向GraphQLView提供架构。 请求方法:GET请求URL:http://localhost:8000/graphqlDjango版本:1.11.1
-
微服务架构的数据库设计[已关闭]
想要改进此问题?更新问题,以便它仅通过编辑这篇文章来关注一个问题。 我计划使用微服务架构来实现我们的网站。我想知道在服务之间共享数据库是否正确,或者为每个服务使用单独的数据库是否更好。在这方面,我可以考虑为所有服务使用一个通用数据库吗?还是它违反了微服务体系结构的本质?
-
Woodstox Stax2 XML W3C架构验证-唯一约束问题
我一直在尝试改进针对XSD模式的XML验证性能,特别是关于XSD唯一约束的性能,并决定尝试一下Woodstox。我基本上遵循了这个示例,将更改为。 不过,我遇到的问题是,Woodstox验证器会发现XML有效,即使XML违反了唯一约束。将我的java代码切换回“常规”、和时,会正确检测到唯一性约束冲突。 此外,我可以确认Woodstox验证器做了一些事情,因为例如,如果我有一个负数,其中一个正数是
-
spring integration 4.1.4。异常:无法找到XML架构的NamespaceHandler
我用的是Spring2.2。我最近升级到了Spring4.1.4。 我的项目使用以下应用程序上下文:
-
带有FXML的JavaFX UI控件架构(控制皮肤)
在JavaFX8中,有一个UI控件体系结构,用于创建自定义控件。基本上是基于: 控制。 皮肤。 新浪网. 此外,还有一个FXML项目的基本结构,也用于制作GUI。基本上: 控制。 FXML 文件。 新浪网. 我想将FXML与UI控件架构一起使用,所以我的问题是: 谁是FXML文件的控制器?皮肤? 我必须执行以下代码之类的操作?:
-
Kafka流拓扑不同的键,但相同的架构
我有一个Kafka Streams拓扑,其中我加入了5个表,每个表都是在一个主题上创建的,该主题由一些Kafka连接器填充,这些连接器产生KeyValue事件,其中Key是针对相同的Avro模式产生的,但在我的拓扑中,当我加入这些表时,Key似乎不一样,如果它们是Java等于事件。所有这些背后的原因是什么? 它与Confluent Schema Registry集成。 我们已经使用了调试器,并且在
-
如何查询架构中没有成员的团队
在我的数据库模式中,我有俱乐部、球队和球员,我想创建一个报告,统计俱乐部中的球队总数,以及没有球员的球队数量。输出如下: 我的架构在以下伪代码中进行了描述: 一些示例数据: 我已经成功开发了一个查询,它将给出每个俱乐部的球队数量: 然而,我还不能将这个查询扩展到包括球队成员数据和没有球员的球队。有什么建议吗?
-
Flyway在一个架构中有多个元数据表
我试图使用Flyway来版本模块化应用程序的数据库。每个模块都有自己独立的表集和迁移脚本,这些脚本将控制该表集的版本控制。 Flyway允许我为每个模块指定不同的元数据表——这样我就可以独立地版本每个模块。当我尝试升级应用程序时,我为每个模块运行一个迁移过程,每个模块都有自己的表和一组脚本。请注意,这些表都在同一个架构中。 但是,当我尝试迁移我的应用程序时,第一次迁移是唯一有效的。后续迁移失败,出
-
信息架构中reference _ constraints . unique _ constraint _ *列的值为空
在Postgres 10中,我声明了以下内容: 然后是第二个表,其中FK引用第一个表: 现在考虑这个查询的输出: 所有<code>unique_constraint_* 从 Postgres 文档中可以看出,这些元列应包含 包含外键约束引用的唯一或主键约束的 [对象] 的名称(始终为当前数据库) 问:我肯定在同一个数据库中,并且在< code>test_abc表上声明的惟一索引是一个惟一约束(否则
-
使用kafka-avro-console-producer而不自动注册架构
我试图使用kafka-avro-console-producer 5.4.0-ccs不自动注册模式。我试着用: 但它仍然在注册模式。属性似乎正确:https://github.com/confluentinc/schema-registry/blob/a0a04628687a72ac6d01869d881a60fbde4177e7/avro-serializer/src/main/java/io/
-
 更改架构时无法预填充room数据库
更改架构时无法预填充room数据库当我试图更改数据库中表的模式/数据时,我遇到了一个无法解决的问题。我正在用Rooms.CreateFromAsset方法预填充数据库。 当我使用以下代码构建数据库时: 和这个数据类:
-
 字节 基础架构 测试开发 实习 一面
字节 基础架构 测试开发 实习 一面我一直准备Java,但是面试官的意思是Python更重要一点,因为测试平常用的是Python。 直接放面经吧 先是项目 问题: 1.堆和栈的区别 2.数组和链表的区别 3.Linux查看端口(本菜狗不会。。) 4. 了解哪些端口(面试官在举例的时候把我知道的全说了,我没得说了。。。我就说我没太注意过这方面)😭 5.MySQL的多表联合查询 6.主键,索引,和外键的区别 7.冒泡排序 8.shel
-
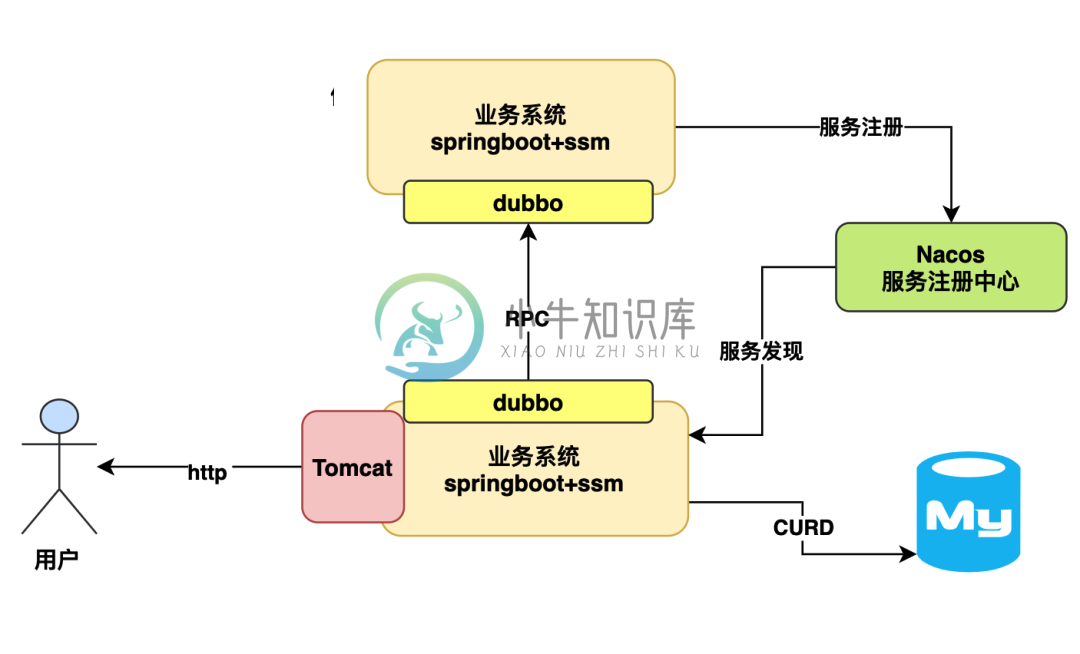 如何设计高性能的MySQL数据库架构?
如何设计高性能的MySQL数据库架构?主要内容:一般业务系统运行流程图,一台 4 核 8G 的机器能扛多少并发量呢?,高并发来袭时数据库会先被打死吗?,8 核 16G 的数据库每秒大概可以抗多少并发压力?,数据库架构可以从哪些方面优化?,总结今天给大家分享一个知识点,是关于 MySQL 数据库架构演进的,因为很多兄弟天天基于 MySQL 做系统开发,但是写的系统都是那种低并发压力、小数据量的,所以哪怕上线了也就是这么正常跑着而已。 但是你知道你连接的这个 MySQL 数据库他到底能抗多大并发压力吗?如果 MySQL 数据库扛不住压力
-
架构原理 - segment merge对写入性能的影响
通过上节内容,我们知道了数据怎么进入 ES 并且如何才能让数据更快的被检索使用。其中用一句话概括了 Lucene 的设计思路就是”开新文件”。从另一个方面看,开新文件也会给服务器带来负载压力。因为默认每 1 秒,都会有一个新文件产生,每个文件都需要有文件句柄,内存,CPU 使用等各种资源。一天有 86400 秒,设想一下,每次请求要扫描一遍 86400 个文件,这个响应性能绝对好不了! 为了解决这
-
8.8 使用NVIDIA计算机统一设备架构(CUDA)
8.8 使用NVIDIA计算机统一设备架构(CUDA) CUDA(Compute Unified Device Architecture)是一种由NVIDIA推出的通用并行计算架构,该架构使用GPU能够解决复杂的计算问题。它包含了CUDA指令集架构(ISA)及GPU内部的并行计算引擎。用户可以使用NVIDIA CUDA攻击使用哈希算法加密的密码,这样可以提高处理的速度。本节将介绍使用OclHash