《nodejs》专题
-
nodejs测试hyperledger作曲家v0.15失败,并出现错误:找不到卡:PeerAdmin @ hlfv1
问题内容: 随着v0.15中卡的实现,使用概要文件的测试例程的早期版本(显然)将无法工作。但是,我找不到SDK方法来创建运行测试所需的卡。通过v0.14进行测试的代码的“之前”部分如下所示,该部分使用嵌入式配置文件,创建网络的临时实例并运行测试: 我试图在Nodejs文档中找到(并且还没有发现)的是如何在使用相同方法的同时创建必要的卡来完成这项工作。 我希望将以下代码行替换为可创建必要卡片的内容:
-
Socket.io + NodeJS + Nginx + SSL
问题内容: 使用Nginx时,我的套接字无法连接。我的配置文件是: 我的NodeJS是: 我的客户是 不用说,两者都不显示任何东西。我担心Nginx阻止了该请求,而节点却实际上从未收到它? 问题答案: 好像缺少了
-
在nodejs socket.io中显示连续连接消息
问题内容: 我正在尝试使用laravel开发实时聊天应用程序。我遇到了问题。当我运行“ node index.js”时,在命令提示符下连续显示“连接已建立”消息。 我的index.js文件是: 我的index.html页面是: 我该如何解决? 问题答案: 客户端不断尝试一遍又一遍地进行连接的通常原因是,因为客户端和服务器版本的socket.io不匹配,导致它们不兼容。您没有显示如何在网页中加载so
-
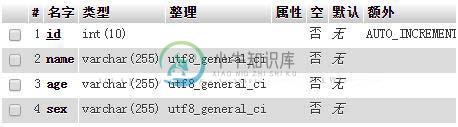 nodejs操作mysql实现增删改查的实例
nodejs操作mysql实现增删改查的实例本文向大家介绍nodejs操作mysql实现增删改查的实例,包括了nodejs操作mysql实现增删改查的实例的使用技巧和注意事项,需要的朋友参考一下 首先需要安装mysql模块:npm install mysql --save 然后创建user数据表: 接着使用nodejs对数据库进行增删改查: 最后运行js: 增删改查都已经执行成功了。 以上这篇nodejs操作mysql实现增删改查的实例就是
-
Nginx和多个Meteor / Nodejs应用出现问题
问题内容: 我知道可以使用Nginx在一台服务器上运行多个Node.js(扩展名为Meteor)。我已经安装好Nginx并可以在Ubuntu服务器上运行它,我什至可以使其响应请求并将其代理到我的一个应用程序中。但是,当尝试让Nginx将流量代理到第二个应用程序时,我遇到了障碍。 一些背景: 在端口8001上运行的第一个应用程序 在端口8002上运行的第二个应用 Nginx在端口80上监听 尝试让N
-
 NodeJS制作爬虫全过程(续)
NodeJS制作爬虫全过程(续)本文向大家介绍NodeJS制作爬虫全过程(续),包括了NodeJS制作爬虫全过程(续)的使用技巧和注意事项,需要的朋友参考一下 书接上回,我们需要修改程序以达到连续抓取40个页面的内容。也就是说我们需要输出每篇文章的标题、链接、第一条评论、评论用户和论坛积分。 如图所示,$('.reply_author').eq(0).text().trim();得到的值即为正确的第一条评论的用户。 {<1>}
-
 nodejs爬虫抓取数据之编码问题
nodejs爬虫抓取数据之编码问题本文向大家介绍nodejs爬虫抓取数据之编码问题,包括了nodejs爬虫抓取数据之编码问题的使用技巧和注意事项,需要的朋友参考一下 cheerio DOM化并解析的时候 1.假如使用了 .text()方法,则一般不会有html实体编码的问题出现 2.如果使用了 .html()方法,则很多情况下(多数是非英文的时候)都会出现,这时,可能就需要转义一番了 类似这些 因为需要作数据存储,所有需要转换 大
-
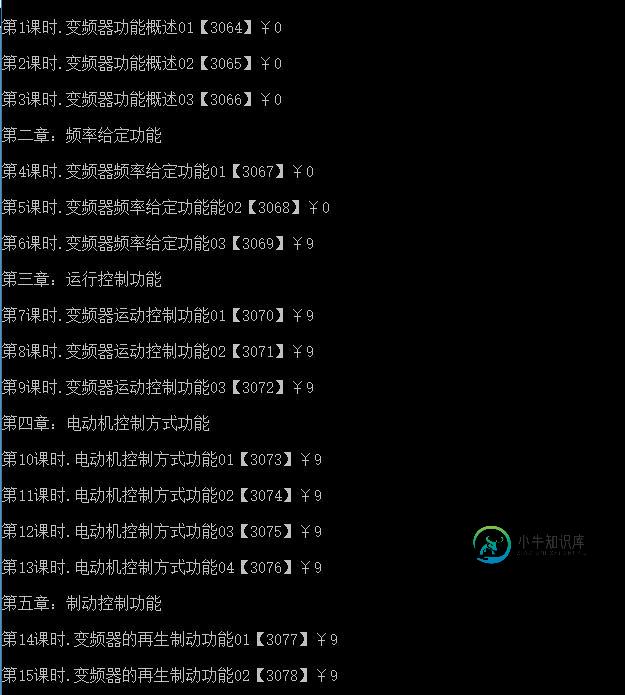 nodeJs爬虫获取数据简单实现代码
nodeJs爬虫获取数据简单实现代码本文向大家介绍nodeJs爬虫获取数据简单实现代码,包括了nodeJs爬虫获取数据简单实现代码的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了nodeJs爬虫获取数据代码,供大家参考,具体内容如下 效果图: 以上就是nodeJs爬虫获取数据的相关代码,希望对大家的学习有所帮助。
-
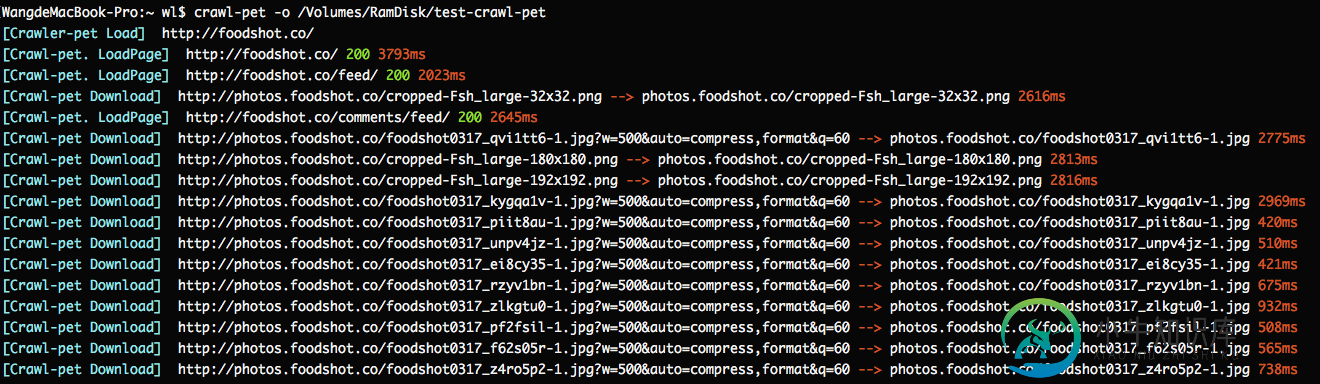 简单好用的nodejs 爬虫框架分享
简单好用的nodejs 爬虫框架分享本文向大家介绍简单好用的nodejs 爬虫框架分享,包括了简单好用的nodejs 爬虫框架分享的使用技巧和注意事项,需要的朋友参考一下 这个就是一篇介绍爬虫框架的文章,开头就不说什么剧情了。什么最近一个项目了,什么分享新知了,剧情是挺好,但介绍的很初级,根本就没有办法应用,不支持队列的爬虫,都是耍流氓。 所以我就先来举一个例子,看一下这个爬虫框架是多么简单并可用。 第一步:安装 Crawl-pet
-
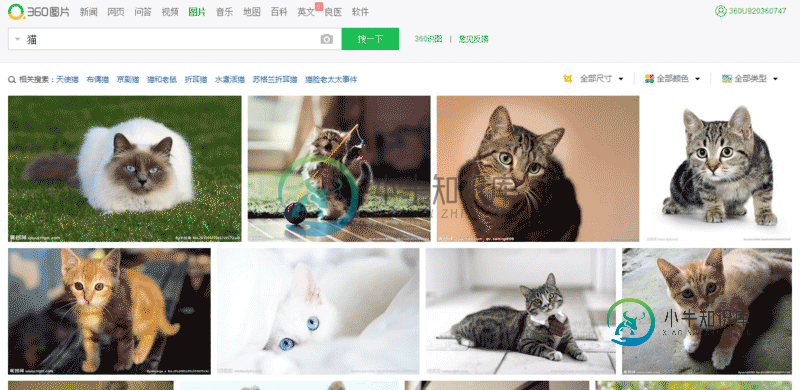 nodejs制作爬虫实现批量下载图片
nodejs制作爬虫实现批量下载图片本文向大家介绍nodejs制作爬虫实现批量下载图片,包括了nodejs制作爬虫实现批量下载图片的使用技巧和注意事项,需要的朋友参考一下 今天想获取一大批猫的图片,然后就在360流浪器搜索框中输入 猫 ,然后点击图片。就看到了一大波猫的图片: http://image.so.com/i?q=%E7%8... ,我在想啊,要是审查元素,一张张手动下载,多麻烦,所以打算写程序来实现。不写不知道,一写发现
-
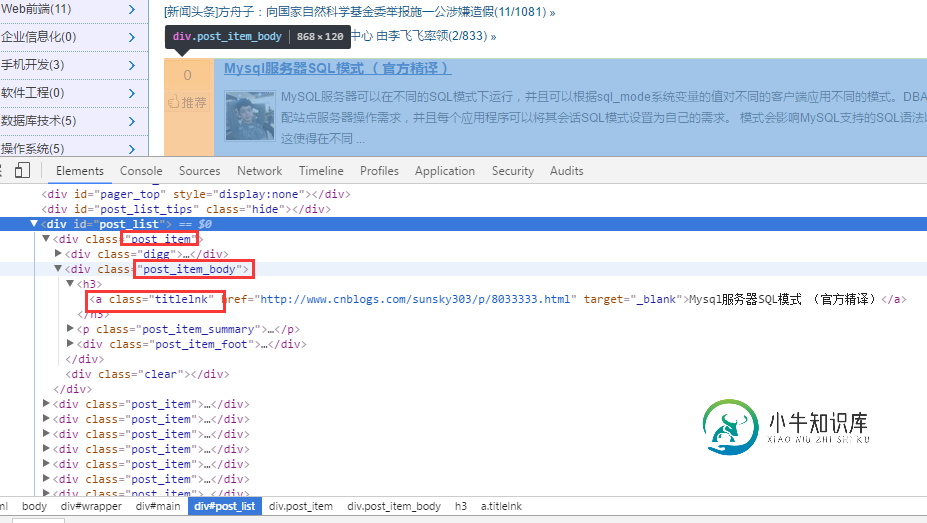 NodeJS爬虫实例之糗事百科
NodeJS爬虫实例之糗事百科本文向大家介绍NodeJS爬虫实例之糗事百科,包括了NodeJS爬虫实例之糗事百科的使用技巧和注意事项,需要的朋友参考一下 1.前言分析 往常都是利用 Python/.NET 语言实现爬虫,然现在作为一名前端开发人员,自然需要熟练 NodeJS。下面利用 NodeJS 语言实现一个糗事百科的爬虫。另外,本文使用的部分代码是 es6 语法。 实现该爬虫所需要的依赖库如下。 request: 利用 g
-
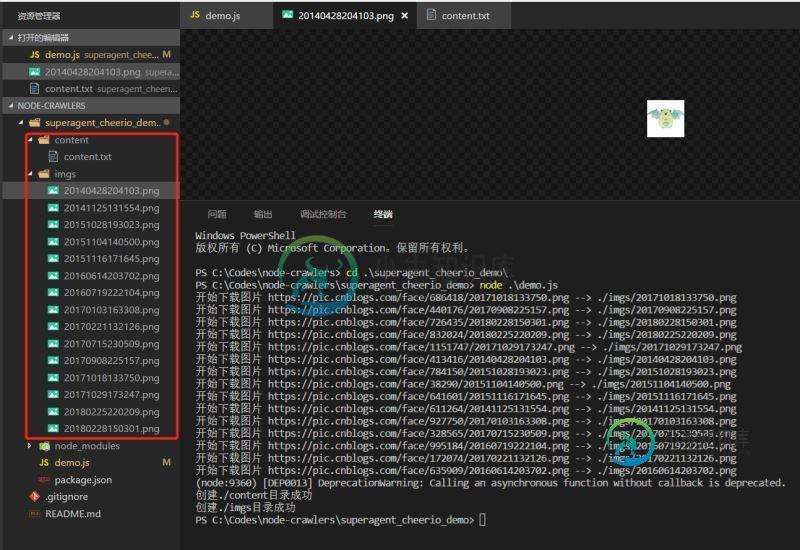 nodejs爬虫初试superagent和cheerio
nodejs爬虫初试superagent和cheerio本文向大家介绍nodejs爬虫初试superagent和cheerio,包括了nodejs爬虫初试superagent和cheerio的使用技巧和注意事项,需要的朋友参考一下 前言 早就听过爬虫,这几天开始学习nodejs,写了个爬虫https://github.com/leichangchun/node-crawlers/tree/master/superagent_cheerio_demo
-
nodeJs爬虫的技术点总结
本文向大家介绍nodeJs爬虫的技术点总结,包括了nodeJs爬虫的技术点总结的使用技巧和注意事项,需要的朋友参考一下 背景 最近打算把之前看过的nodeJs相关的内容在复习下,顺便写几个爬虫来打发无聊,在爬的过程中发现一些问题,记录下以便备忘。 依赖 用到的是在网上烂大街的cheerio库来处理爬取的内容,使用superagent处理请求,log4js来记录日志。 日志配置 话不多说,直接上代码
-
Nodejs实现爬虫抓取数据实例解析
本文向大家介绍Nodejs实现爬虫抓取数据实例解析,包括了Nodejs实现爬虫抓取数据实例解析的使用技巧和注意事项,需要的朋友参考一下 开始之前请先确保自己安装了Node.js环境,如果没有安装,大家可以到呐喊教程下载安装。 1.在项目文件夹安装两个必须的依赖包 superagent 是一个轻量的,渐进式的ajax api,可读性好,学习曲线低,内部依赖nodejs原生的请求api,适用于node
-
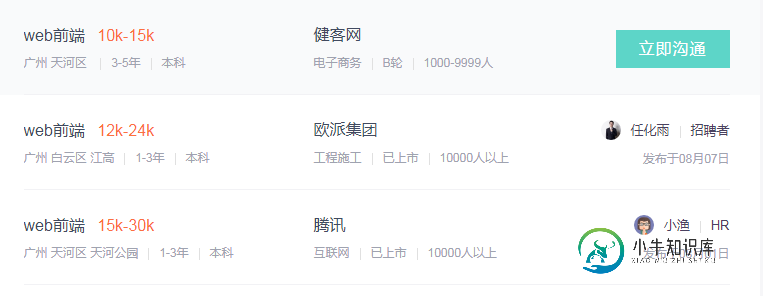 NodeJs实现简单的爬虫功能案例分析
NodeJs实现简单的爬虫功能案例分析本文向大家介绍NodeJs实现简单的爬虫功能案例分析,包括了NodeJs实现简单的爬虫功能案例分析的使用技巧和注意事项,需要的朋友参考一下 1.爬虫:爬虫,是一种按照一定的规则,自动地抓取网页信息的程序或者脚本;利用NodeJS实现一个简单的爬虫案例,爬取Boss直聘网站的web前端相关的招聘信息,以广州地区为例; 2.脚本所用到的nodejs模块 express 用来搭建一个服务,将结果