《同花顺2024春招交流讨论》专题
-
交易
交易 为了与Infura节点进行交易,需要在发送它们之前离线创建交易和签名,因为Infura节点没有加密的以太坊密钥文件的访问权限,这是需要通过geth或者Parity管理命令来解锁帐户。 有关详细信息,请参阅以太坊交易中离线交易和签名部分和web3j如何使用管理APIs。
-
交易
交易 Web3j支持使用以太坊钱包文件(推荐的)和用于发送事务的以太坊客户端管理命令。 使用以太钱包文件发送以太币给其他人: Web3j web3 = Web3j.build(new HttpService()); // defaults to http://localhost:8545/ Credentials credentials = WalletUtils.loadCredentials
-
提交
说明 支付宝报关接口 官方文档:https://docs.open.alipay.com/155/104778/ 类 请求参数类 请求参数 类名:\Yurun\PaySDK\AlipayCrossBorder\Customs\Submit\Request 属性 名称 类型 说明 $service string 接口名称 $out_request_no string 商户生成的用于唯一标识一次报关操
-
提交
说明 微信支付-订单附加信息提交接口SDK。 官方文档:https://pay.weixin.qq.com/wiki/doc/api/external/declarecustom.php?chapter=18_1 类 请求参数类 请求参数 类名:\Yurun\PaySDK\Weixin\CustomDeclareOrder\Request 属性 名称 类型 说明 $_apiMethod strin
-
交易
交易有不同的分类,不同交易有不同的操作码。 这样做的好处就是明确用户行为,简化系统复杂度。 操作码列表 OpsTransfer:用于普通的链内转账 OpsMove:用于链间的转账 OpsNewChain:用于创建新的子链 OpsNewApp:用于创建智能合约 OpsRunApp:用于执行智能合约 OpsRegisterMiner:用于注册矿工 OpsUpdateAppLife:更新智能合约的生命周
-
在使用包括重试的流量时顺序调用非阻塞操作
正如你所看到的,我所做的是:从Kafka那里获取消息,将其转换成一个意在新目的地的对象,然后将其发送到目的地,然后确认偏移量以标记消息为已消费和已处理。以与从Kafka消费的消息相同的顺序确认偏移量是非常关键的,这样我们就不会将偏移量移动到未完全处理的消息之外(包括将一些数据发送到目的地)。因此,我使用来确保这一点。 为了简单起见,我们假设方法是一个标识转换。 方法需要通过网络执行某些操作,例如调
-
谷歌数据流和发布订阅 - 无法实现一次交付
我正在尝试使用Google Dataflow和Apache Beam SDK 2.6.0的PubSub实现一次性交付。 用例非常简单: 'Generator'数据流作业将1M消息发送到PubSub主题。 “存档”数据流作业从PubSub订阅中读取消息,并保存到Google云存储中。 我在 Pubsub.IO.Write(“生成器”作业)和 PubsubIO.Read(“存档”作业)中都添加了“带
-
在相同goroutine中创建的goroutine是否总是按顺序执行?
问题内容: 上面的代码创建了100个goroutine,将num插入到通道c,所以我只是想知道,这些goroutine是否会以随机顺序执行?在我的测试期间,输出将始终为1到100 问题答案: 严格来说,您观察到的“随机”行为是不确定性行为。 要了解此处发生的情况,请考虑通道的行为。在这种情况下,它有许多goroutine试图写入通道,而只有一个goroutine从通道中读出。 阅读过程只是顺序的,
-
如何在Java中以相同顺序随机播放两个数组
问题内容: 我有两个问题和答案 我曾经洗牌每个数组。如何对每个数组进行混洗,以便在混洗后保持相同的顺序? 问题答案: 您可以改组包含索引的新数组。然后从第一个索引获取两个数组中的元素。 当然,如其他答案所建议的那样,创建一个包含和将是一种更加面向对象的方法。这样,与当前方法相比,您仅需维护一个或。
-
Netty 4使用不同于通道的键来维护事件顺序
Netty 3中有一个OrderedMemoryAwareThreadPoolExecutor,文档中描述了如何更改排序键:http://docs.jboss.org/netty/3.2/api/org/jboss/netty/handler/execution/OrderedMemoryAwareThreadPoolExecutor.html 在Netty 4中,这是用EventExecutor
-
DocuSign-添加一个路由顺序相同的非签名CC角色
我们在Docusign中配置了一个模板,并要求添加一个签名者和一个非签名者,我们需要在签名过程之前和之后向他们发送副本。我选择了Add CC按钮,添加了所需的角色,并将操作指定为Receive a copy,现在,签名者和非签名者的电子邮件地址是动态的,因此我使用API填充角色名称,电子邮件地址。对于角色名,我在模板中指定它,并通过代码使用相同的匹配角色名。 我怎么才能绕过这个?
-
如何联合两个火花Dataframe与类型结构,可以不同的字段?
我对Apache Spark很陌生,有时仍在努力。我正在尝试导入一个非常复杂的json文件,并在将其保存到拼花文件之前将其展平。 我的json文件是一个存储树。 每个商店都可以有一个字段,该字段是一个帐户数组。一个帐户有3个必填字段和两个可选字段。所以我有一个数据框,它的字段可以有3种不同的类型。 在数据帧中导入文件并没有什么大不了的,但在扁平化过程中,我可能希望对两个数据帧进行联合,这两个数据帧
-
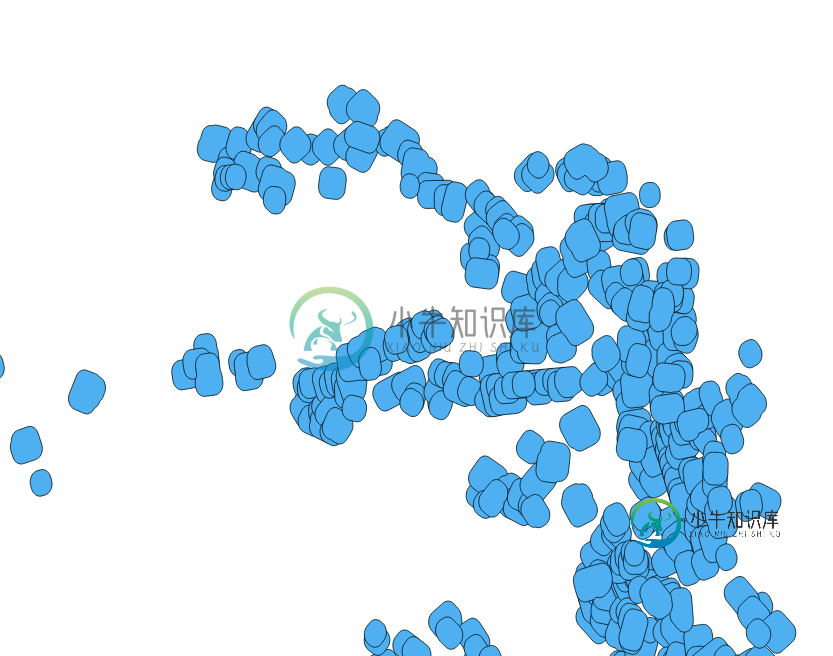 PostGIS-合并不同组中的缓冲区几何(相交时)
PostGIS-合并不同组中的缓冲区几何(相交时)我在这个表中存储了一些几何图形(140k) CREATE TABLE缓冲区(pk整数NOT NULL,geom几何体(MultiPolygon,4326),) 我想(如果可能的话)创建一个新表(buffersmerged),该表将包含生成的几何图形,其中预览在彼此相交时进行分组。 我预期的输出,就像在QGIS中使用缓冲区工具检查“溶解缓冲区结果”时一样,但我希望,而不仅仅是一个大的独特几何作为输出
-
防止表单提交后重置多个同名复选框
我有多个类/组的复选框,每个类/组包含多个同名复选框。提交表单时,所有复选框都会重置。我在这个网站上尝试了很多解决方案,但这些都不适用于复选框组。例如:- 如何防止表单提交后复选框被重置?
-
按Enter键提交两个不同的div标签的表单
我有一个带有两个div标签的登录控件的表单 第一个DIV包含用户名、密码和登录按钮,而且我忘记了表单中的密码链接。。当我们点击它时,它会显示另一个带有输入电子邮件id文本框和提交按钮的div。 我使用JQuery的回车键来提交表单,它工作得很好...但在忘记密码链接的情况下,单击它会显示另一个div...与提交按钮,但回车键不适用于按键上的div 这是我的jQuery代码: 如何提交表单输入键按两