《同花顺2024春招交流讨论》专题
-
 没有显示贴花
没有显示贴花我试图在我的网格上创建一个贴花使用three.js和反应-三纤维。我相信我正确地设置了网格和材料,但由于某种原因,贴花没有出现在画布上。 这是包含模型、背板和贴花的父组件。 这是我从. glb文件创建t恤网格的组件的一部分。网格传递回父节点,然后传递到Decal组件。 以下是我尝试设置贴花网格的方式: 我没有得到任何错误,贴花只是没有出现。我希望有人有一些见解。没有太多关于贴花几何体与3J在那里,
-
火花映射变换
我是新的火花,请帮助我这一点。
-
火花读阿夫罗
正在尝试读取avro文件。 无法将运行到Avro架构的数据转换为Spark SQL StructType:[“null”,“string”] 尝试手动创建架构,但现在遇到以下情况: 通用域名格式。databricks。火花阿夫罗。SchemaConverters$CompatibleSchemaException:无法将Avro架构转换为catalyst类型,因为路径处的架构不兼容(avroTyp
-
火花 2.0 设置罐
我正在一个playscala应用程序中从1.6升级到spark 2.0,不太确定如何设置我想要的jar文件。以前会定义一个SparkConf,我可以调用的方法之一是setJars,它允许我指定我想要的所有jar文件。现在我正在使用SparkSession构建器构建我的spark conf和spark上下文,我没有看到任何类似的方法来指定jar文件?我该怎么做? 这是我之前如何创建我的火花会议: 我
-
插入表($table_variable)雪花
我正在使用雪花,我正在寻找插入数据到一个表,而使用一个变量,使用变量的目的是,当我可以改变它,而不做查找和替换所有 以下作品 以下操作不起作用 然而,这是有效的。 https://docs.snowflake.com/en/sql-reference/session-variables.html
-
雪花外部表DDL
我知道我们将无法使用雪花中的GET_DDL函数获取外部表的DDL。是否有任何变通方法来获取雪花中外部表的DDL(Create语句)?
-
火花累计金额
我想在Spark中做累积和。以下是注册表(输入): 配置单元查询: 输出: 使用火花逻辑,我得到相同的输出: 然而,当我在spark cluster上尝试这个逻辑时,的值将是累积和的一半,有时它是不同的。我不知道为什么它会发生在spark cluster上。是因为分区吗? 如何计算spark cluster上一列的累积和?
-
火花记忆问题
嗨,我对Spark很陌生。我正在Apache Spark scala命令行上执行以下命令
-
火花UDF零处理
我正在处理UDF中的空值,该UDF在数据帧(源自配置单元表)上运行,该数据帧由浮点数结构组成: 数据帧()具有以下架构: 例如,我想计算x和y的总和。请注意,我不会在以下示例中“处理”空值,但我希望能够在我的udf中检查、或是否。 第一种方法: 如果<code>struct是否为空,因为在scala中<code>浮点不能为空。 第二种方法: 这种方法,我可以在我的udf中检查是否为空,但我可以检查
-
雪花绑定变量
如何使用雪花存储过程将current_date()bind变量插入到表中 创建或替换过程abc(“p_message_id”浮点数、“p_theater”字符串、“p_month”字符串、“p_message”字符串、“p_message”字符串、“p_start_date”字符串、“p_end_date”字符串、“p_action”字符串、“p_msg_type”字符串、“p_logged_us
-
贴花几何体(DecalGeometry)
DecalGeometry 可被用于创建贴花网格物体,以达到不同的目的,例如:为模型增加独特的细节、进行动态的视觉环境改变或覆盖接缝。 代码示例 const geometry = new DecalGeometry( mesh, position, orientation, size ); const material = new THREE.MeshBasicMaterial( { color
-
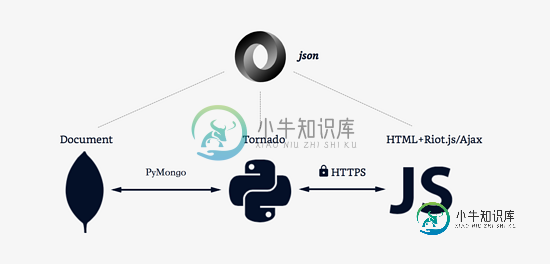 JSON 的正确用法探讨:Pyhong、MongoDB、JavaScript与Ajax
JSON 的正确用法探讨:Pyhong、MongoDB、JavaScript与Ajax本文向大家介绍JSON 的正确用法探讨:Pyhong、MongoDB、JavaScript与Ajax,包括了JSON 的正确用法探讨:Pyhong、MongoDB、JavaScript与Ajax的使用技巧和注意事项,需要的朋友参考一下 关于本文 本文主要总结网站编写以来在传递 JSON 数据方面遇到的一些问题以及目前采用的解决方案。网站数据库采用 MongoDB,后端是 Python,前端采用“半
-
Python的类实例属性访问规则探讨
本文向大家介绍Python的类实例属性访问规则探讨,包括了Python的类实例属性访问规则探讨的使用技巧和注意事项,需要的朋友参考一下 一般来说,在Python中,类实例属性的访问规则算是比较直观的。 但是,仍然存在一些不是很直观的地方,特别是对C++和Java程序员来说,更是如此。 在这里,我们需要明白以下几个地方: 1.Python是一门动态语言,任何实体都可以动态地添加或删除属性。 2.一个
-
从Kinesis中的两个不同流获取数据?
我正试图成为一个动觉消费者客户。为了解决这个问题,我阅读了《Kinesis开发人员指南》和AWS文档http://docs.aws.amazon.com/kinesis/latest/dev/kinesis-record-processor-implementation-app-java.html. 我想知道是否有可能从两个不同的流中获取数据并进行相应的处理。 假设我有两个不同的流,分别是流1和流
-
Flink流媒体:比较不同窗口的事件
首先,我是流处理框架的新手。我想对其中一些进行基准测试,所以我从Flink开始。 对于我的用例,我需要将窗口t中的事件与窗口t-1中的事件进行比较,两者的大小都是15分钟,然后进行一些聚合。 以下是我的用例的简化版本: 我们将分析的事件视为形式的元组。在窗口1中,我们有:(A,1),(B,2),(C,3),在窗口2中,我们有:(D,6)和(B,7)。然后,我需要将当前窗口中的事件与前一个窗口中的事