《同花顺2024春招》专题
-
雪花复制到并行拼花文件加载
我如何一次加载5年的拼花数据并复制到一个表中?因为1个月的负荷比我1.5个小时,5年就要花我90个小时。如果有可能并行加载?我该怎么做呢? 谢谢
-
迭代JsonObject的密钥时,它们的顺序与服务器响应中的顺序不同
问题内容: 我收到来自JSON字符串服务器的很大响应。我将其转换为JSON对象,然后获取密钥并对其进行迭代。 问题是,当我进行迭代时,它的顺序与服务器的响应顺序相同。 接下来,我通过添加所有键并对其进行排序来应用另一种方法,然后获得该方法的迭代器,但仍然不是我所需要的(作为响应)。 代码示例在这里: 问题答案: JSON对象的键顺序不应该有意义。如果要特定顺序,则应使用数组,而不是对象。 您的Ja
-
我们可以在同一个拼花文件中每个行组有不同的模式吗?
在创建拼花文件时,我们可以在每个行组中使用不同的模式吗?在这种情况下,页脚将合并所有行组中的所有模式,但每个行组的模式将不同。这是公认的拼花格式吗?拼花规范是否清楚地表明模式不能在同一拼花文件中按行组更改? 官方规范对这一部分不是很具体,但当我们以这种方式编写文件时,Spark无法读取。 我尝试编写这样的文件和阅读使用spark.read.parquet和我得到以下错误 <代码>组织。阿帕奇。火花
-
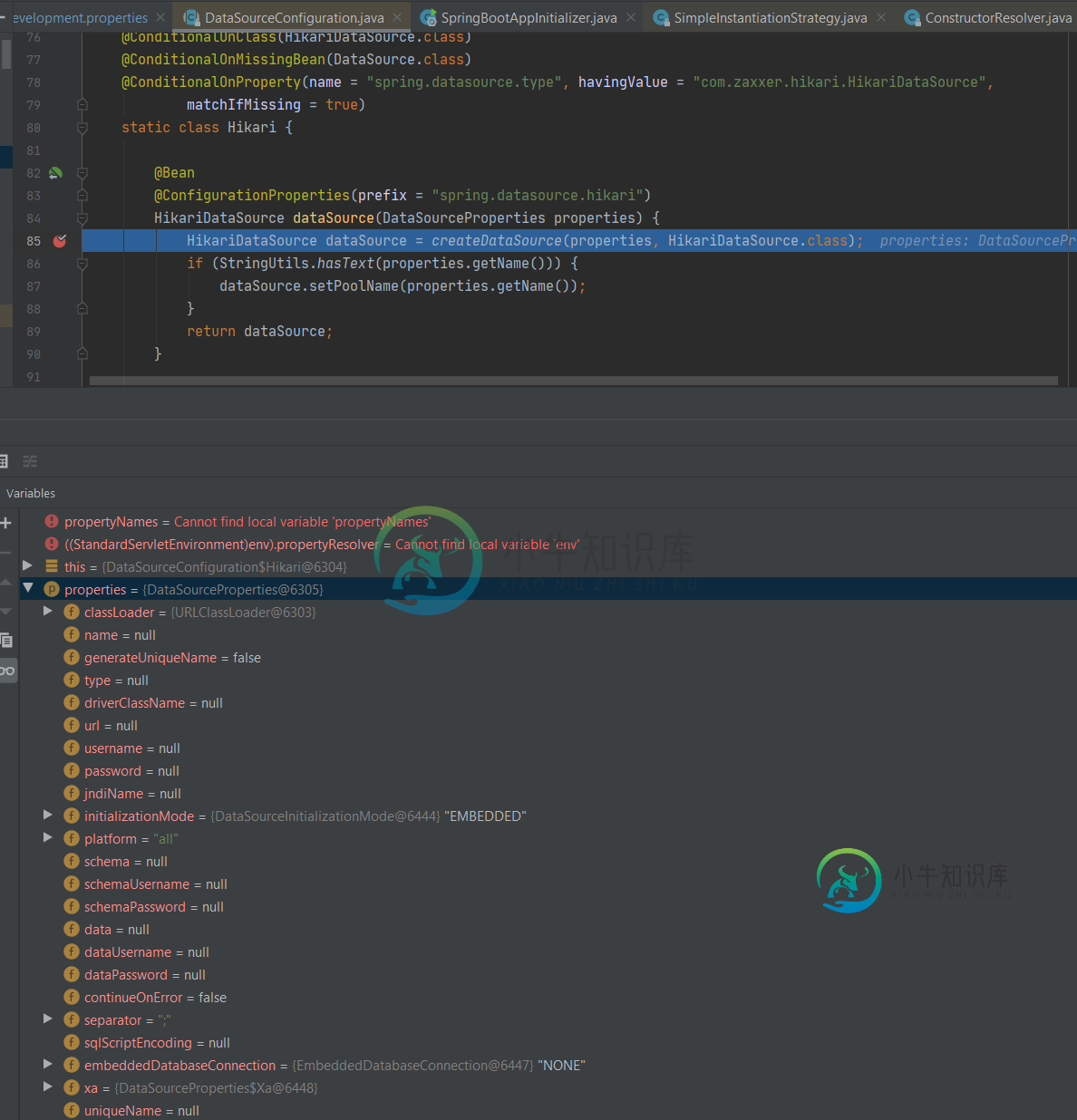 春到春的引导迁移。嵌入式Spring数据源
春到春的引导迁移。嵌入式Spring数据源目前,它已经被Spring Boot应用程序与如下所示的自定义数据源配置一起使用 之前 上面的代码正在工作
-
 2024届奇安信秋招算法工程师一面
2024届奇安信秋招算法工程师一面奇安信 计划研究院 算法工程师 一面 40min 11.06 1.介绍了三段实习实习经历,里面用到的模型的原理,改进方法等 聊了20min 2.刚收到图像的训练数据,怎么进行处理 3.Yolov5的主要改进点 4.介绍特征金字塔,以及为什么它能提升模型的效果 5.介绍Centernet模型 6.anchor free比 anchor base有什么优缺点 7.Python列表去重的方法 8.Pyt
-
 2024届BOSS直聘算法工程师秋招面经
2024届BOSS直聘算法工程师秋招面经https://zhuanlan.zhihu.com/p/665595011 Boss直聘 算法工程师 一面 11.06 项目介绍 画出Lstm的结构图,并进行说明 Lstm用的激活函数是什么?相比sigmoid有什么优势? 介绍Rcnn。为什么它速率较慢 C++内存泄露的原因 Python哪些对象是可变的,哪些是不可变的,怎么判断 Coding y = np.array([1, 1, 1, 1,
-
 百度产品运营2024届秋招面试(一面)
百度产品运营2024届秋招面试(一面)背景:我从百度百家号离职一个月,实习时是内容运营,秋招投的产品运营。产运负责人直接问了我业务相关的问题,让我提意见和建议,甚至自我介绍都没有,够直接的哈哈哈。 面我的应该是产运一个部门leader,更多从业务角度出发来跟我交流,其实好些问题我都没接住,不过似乎对我比较包容,一直在创造机会让我说话。 具体问题 1、最有收获/成就感的事情 2、从内容运营角度评价运营后台,有哪些不足,怎么改进(重点)
-
Eclipse和花括号
问题内容: 有没有一种快速的方法可以使Eclipse将花括号放在代码块的下一行上(本身)? 问题答案: 对于预先编写的代码块,请先按照Don的建议进行设置,然后选择该代码段,然后右键单击SourceCode->Format,然后按照首选项中的设置进行格式化。
-
RDD火花质疑
我想了解以下关于火花概念的RDD的事情。 > RDD仅仅是从HDFS存储中复制某个节点RAM中的所需数据以加快执行的概念吗? 如果一个文件在集群中被拆分,那么对于单个flie来说,RDD从其他节点带来所有所需的数据? 如果第二点是正确的,那么它如何决定它必须执行哪个节点的JVM?数据局部性在这里是如何工作的?
-
火花行到JSON
我想从Spark v.1.6(使用scala)数据帧创建一个JSON。我知道有一个简单的解决方案,就是做。 但是,我的问题看起来有点不同。例如,考虑具有以下列的数据帧: 我想在最后有一个数据帧 其中C是包含、、的JSON。不幸的是,我在编译时不知道数据框是什么样子的(除了始终“固定”的列和)。 至于我需要这个的原因:我使用Protobuf发送结果。不幸的是,我的数据帧有时有比预期更多的列,我仍然会
-
聚合火花流
我试图从聚合原理的角度来理解火花流。Spark DF 基于迷你批次,计算在特定时间窗口内出现的迷你批次上完成。 假设我们有数据作为- 然后首先对Window_period_1进行计算,然后对Window_period_2进行计算。如果我需要将新的传入数据与历史数据一起使用,比如说Window_priod_new与Window_pperid_1和Window_perid_2的数据之间的分组函数,我该
-
雪花-TABLE命令
我正在搜索TABLE命令的官方文档(它与TABLE( ))不同。 我搜索了所有命令/查询语法,但没有太多成功。
-
火花UDF过载
我有一个要求,火花UDF必须超载,我知道UDF超载是不支持火花。因此,为了克服spark的这一限制,我尝试创建一个接受任何类型的UDF,它在UDF中找到实际的数据类型,并调用相应的方法进行计算并相应地返回值。这样做时,我得到一个错误 以下是示例代码: 有可能使上述要求成为可能吗?如果没有,请建议我一个更好的方法。 注:Spark版本-2.4.0
-
JDBC火花连接
我正在研究建立一个JDBC Spark连接,以便从r/Python使用。我知道和都是可用的,但它们似乎更适合交互式分析,特别是因为它们为用户保留了集群资源。我在考虑一些更类似于Tableau ODBC Spark connection的东西--一些更轻量级的东西(据我所知),用于支持简单的随机访问。虽然这似乎是可能的,而且有一些文档,但(对我来说)JDBC驱动程序的需求是什么并不清楚。 既然Hiv
-
 JavaScript 秘密花园
JavaScript 秘密花园JavaScript 秘密花园是一个不断更新,主要关心 JavaScript 一些古怪用法的文档。 对于如何避免常见的错误,难以发现的问题,以及性能问题和不好的实践给出建议, 初学者可以籍此深入了解 JavaScript 的语言特性。 JavaScript 秘密花园不是用来教你 JavaScript。为了更好的理解这篇文章的内容, 你需要事先学习 JavaScript 的基础知识。在 Mozill