《架构师》专题
-
老的 React 架构
在上一节中我们了解了React的理念,简单概括就是快速响应。 React从v15升级到v16后重构了整个架构。本节我们聊聊v15,看看他为什么不能满足快速响应的理念,以至于被重构。 React15架构 React15架构可以分为两层: Reconciler(协调器)—— 负责找出变化的组件 Renderer(渲染器)—— 负责将变化的组件渲染到页面上 Reconciler(协调器) 我们知道,在R
-
架构及原理
Xwindow 使用服务器-客户端架构。无论本地图形界面,还是远程图形界面,都以同样的流程工作。这样便不需要分别进行设计和维护。 本地X客户端 ┐ ┌ 键盘 远程X客户端 ┼ X协议 ─ X服务器 ─ 驱动程序┼ 鼠标 远程X客户端 ┘ └ 显示器 Xserver Xwindow 系统服务器端,通过驱动程序(硬件规范)来管理硬件资源。 例如:当我们移动鼠标时,通过驱动程序[窗口
-
元数据/架构
当我说 table.drop() / metadata.drop_all() sqlacalchemy是否支持alter table、create view、create trigger、schema升级功能? 如何根据表对象的依赖关系对其排序? 如何以字符串形式获取创建表/删除表输出? 我如何子类表/列以提供某些行为/配置? 当我说 table.drop() / metadata.drop_al
-
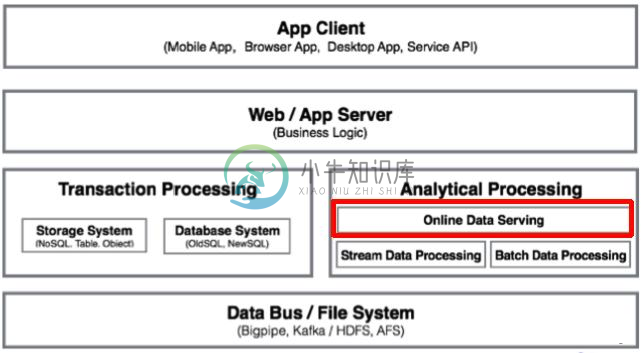 Doris架构原理
Doris架构原理主要内容:1.介绍,2.Doris 定位,3.Doris架构,4.Frontend MetaData Management1.介绍 Doris是一个MPP的OLAP系统,以较低的成本提供在大数据集上的高性能分析和报表查询功能。 MPP (Massively Parallel Processing),即大规模并行处理。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似) 注:MPPDB与Hadoop都是将运算
-
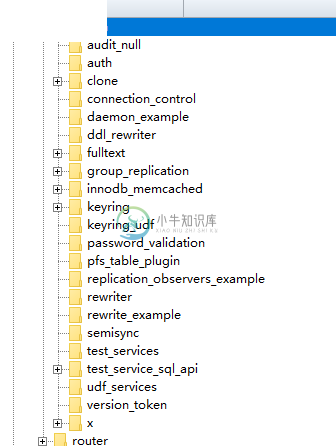 插件Plugin架构
插件Plugin架构主要内容:一、Mysql中的Plugin,二、Plugin的架构,三、源码分析,四、总结一、Mysql中的Plugin 在程序设计的发展过程中,插件(Plugin)形式的设计存在的时间很长了,这种源于硬件的插件接口设计,优势在于可以很从容的进行不同场景应用的切换,甚至在运行时也可以通过动态的参数配置来实现整个功能应用场景的快速适配。从Eclipse到Idea等IDE开发工具,到实际的项目开发中,只要开发经验较多的程序员一定会遇到过类似的工程实践。 插件一般是基于一定的插件协议,通过开
-
Android 架构蓝图
Google 推出的一个项目,专门展示 Android 引用各种各样的 MVP 架构。 目前已经完成的示例有 todo-mvp(mvp 基础架构示例) todo-mvp-loaders(基于 mvp 基础架构项目,获取数据部分使用了 Loaders 架构) todo-mvp-databinding(基于 mvp 基础架构项目,使用了数据绑定组件) todo-mvp-clean(基于 mvp 基础架
-
第2章 设备架构 - 2.3 架构设计空间
现实世界中,我们所见的架构远比之前提到架构复杂。我们所使用的计算机架构在各个方面都会发生很大的变化,具有很大的设计空间。即便是当前公开的架构,不同厂商的实现都有不同。 当前一些人对于架构的观点过于简单。例如,在GPU领域,我们经常会遇到下面的几种情况: CPU是串行的,GPU是并行的 CPU只有几个核,GPU有数百个核 CPU只能运行一两个线程,GPU可以运行成千上万个线程 当然,现实中的设计要远
-
融合kafka生产者avro架构错误ClientError:架构解析失败:未知命名架构
我在Kafka的制作人那个里工作,推动主题中的信息。我用的是融合的Kafka。 github上的喜欢问题 下面是我的模式。avsc文件。 Keys.avsc 测试.avsc 生产者.py 当我尝试注册时,它工作正常,没有错误。但是当我尝试注册之后注册。我得到以下错误。 confluent_kafka.avro.error。ClientError:架构分析失败:未知的命名架构“io.codebrew
-
如何通过Spring Boot框架构建微服务架构
大家好, 我试图找出如何基于Wildfly中运行的模块(war)移动我当前的系统架构。现在所有的基础资源都放在JNDI树中,比如数据源、JMS等等。。。我的项目框架是Spring 4和family,它允许我查找这些资源和其他内容。 我的目标是使用Spring Boot和Spring Cloud Netflix创建一个微服务架构,其中每一个WAR都是一个通过总线服务集成的新的独立应用程序。 但我的疑
-
向架构集中添加XSD架构内容时出错
我有一个XSD模式,根文档是:
-
中间件及架构 - 驱动框架
translated_page: https://github.com/PX4/Devguide/blob/master/en/middleware/drivers.md translated_sha: 95b39d747851dd01c1fe5d36b24e59ec865e323e 驱动框架 PX4的代码库使用一个轻量级的,统一的驱动抽象层:DriverFramework. POSIX和 QuR
-
Django Haystack-无法构建solr架构
当我尝试构建solr架构时,出现以下错误: 也许这些信息会很有用: MySite/settings.py文件: 博客/search_indexes.py文件: blog/templates/search/index/blog/post_text.txt文件: 我正在使用Apache Solr 4.10.4、Python 3.4.5和Django 1.11.5。当我试图导入干草堆在Python控制台
-
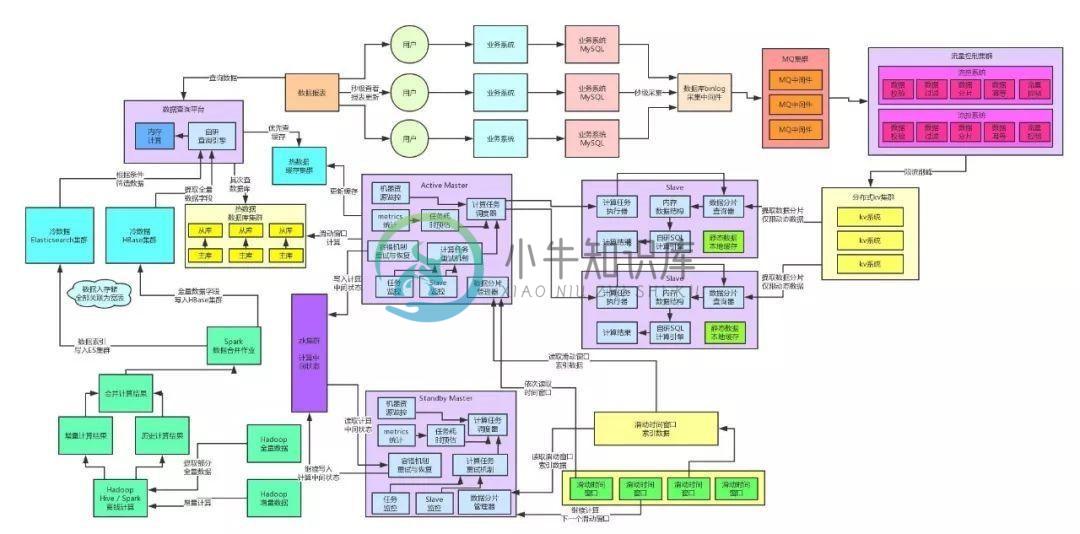 架构师的必备能力
架构师的必备能力主要内容:一、前情回顾,二、MQ集群高可用方案,三、KV集群高可用保障方案,四、实时计算链路高可用保障方案,五、热数据高可用保障方案,六、冷数据高可用保障方案,七、最终总结一、前情回顾 上篇文章:《同事老是吐槽我的接口性能差,原来真凶就在这里!》,聊了一下系统架构中的查询平台。 我们采用冷热数据分离: 冷数据基于HBase+Elasticsearch+纯内存自研的查询引擎,解决了海量历史数据的高性能毫秒级的查询 热数据基于缓存集群+MySQL集群做到了当日数据的几十毫秒级别的查询性能。 最终,整
-
 架构师 2015 年 2 月刊
架构师 2015 年 2 月刊《架构师》是由 InfoQ 中文站制作发布的刊物,为高级技术开发和管理人员提供关于技术创新方面的深度文章与最新观点,范围包括但不限于语言开发、架构设计、团队管理、流程管理、基础架构、企业架构等方面。每月8日发布的《架构师》月刊是电子刊物,可从 InfoQ 中文站上下载获取;每年《架构师》也会精选内容制作一本实体书,可从QCon大会、QClub 技术沙龙等线下活动获取。
-
Android 架构师技能图谱
架构与设计 设计模式 重构 技术选型 特性 可用性 性能 包大小 方法数 文档 技术支持 UI架构模式 MVC MVP MVVM 研发工具 集成开发环境 Android Studio Sublime Text 版本控制系统 svn git gitlab github mercurial 调试工具 ADB DDMS Stetho LeakCanary ClassyShark Postman mark